
Qwen-AgentWorld is a language world model released by the Qwen team for simulating agent environments. Instead of only answering questions like a general chat model, it is designed to predict what an environment would return after an agent takes an action.
This makes it especially relevant for AI agent research, simulated reinforcement learning, benchmark evaluation, and local experiments around terminal, software engineering, search, MCP, web, operating system, and Android-style environments.
This article is a lightly rewritten and translated version of the original Chinese article. The structure, technical flow, commands, tables, and key ideas are preserved, while the language has been adjusted for smoother English reading and SEO publishing.
Source note: The original article was published on CSDN and states that it follows the CC BY-SA 4.0 license. Original source: Qwen-AgentWorld完整部署指南:免费开源,性能超GPT-5.4,5分钟跑起来. Verification note: Official Qwen pages confirm the public release of
Qwen-AgentWorld-35B-A3Bmodel weights andAgentWorldBench. The largerQwen-AgentWorld-397B-A17Bis included in official benchmark results, but the public model page and GitHub release primarily point to the 35B-A3B model weights.
1. Background: Why Do We Need a Language World Model?
Over the past two years, AI agents have moved quickly from simple chat assistants into tools that can operate websites, run terminal commands, control mobile apps, and complete software engineering tasks.
But training a strong agent is expensive. It often requires large volumes of real environment interaction, and that creates several practical problems:
Building and maintaining environments is tedious.
Data collection is slow and hard to scale.
Real environments carry risk, especially when testing failure cases or injecting controlled disruptions.
A Language World Model, or LWM, is built to solve this problem. The idea is simple but powerful: let a model play the role of the environment. Given an agent action and the interaction history, the model predicts the next environment state.
With that setup, agents can be trained and evaluated in simulation instead of always relying on real systems.
On 2026-06-24, the Qwen team released Qwen-AgentWorld, a native language world model that unifies seven agent interaction domains in one model. The companion benchmark, AgentWorldBench, was also released.
Official resources:
GitHub: QwenLM/Qwen-AgentWorld
2. Core Idea: What Makes It a “Native” World Model?
The word native is important here. Qwen-AgentWorld is not just a general-purpose LLM adapted after training to imitate an environment. Its world-modeling goal is built into the training process from the beginning.
Comparison Dimension | Traditional Approach | Qwen-AgentWorld |
Training starting point | Fine-tune a general LLM | Treat environment modeling as the goal from CPT onward |
Training process | Usually SFT or RL only | CPT → SFT → RL |
Environment knowledge | Added through extra data or adaptation | Internalized during training |
Domain coverage | One or a few domains | Seven domains in one model |
In other words, Qwen-AgentWorld is not just a general model wrapped with prompts. It is trained from the lower layers of the pipeline to predict the next state of an environment.
That gives the model a more structured understanding of environment dynamics, especially when simulating long interaction trajectories.
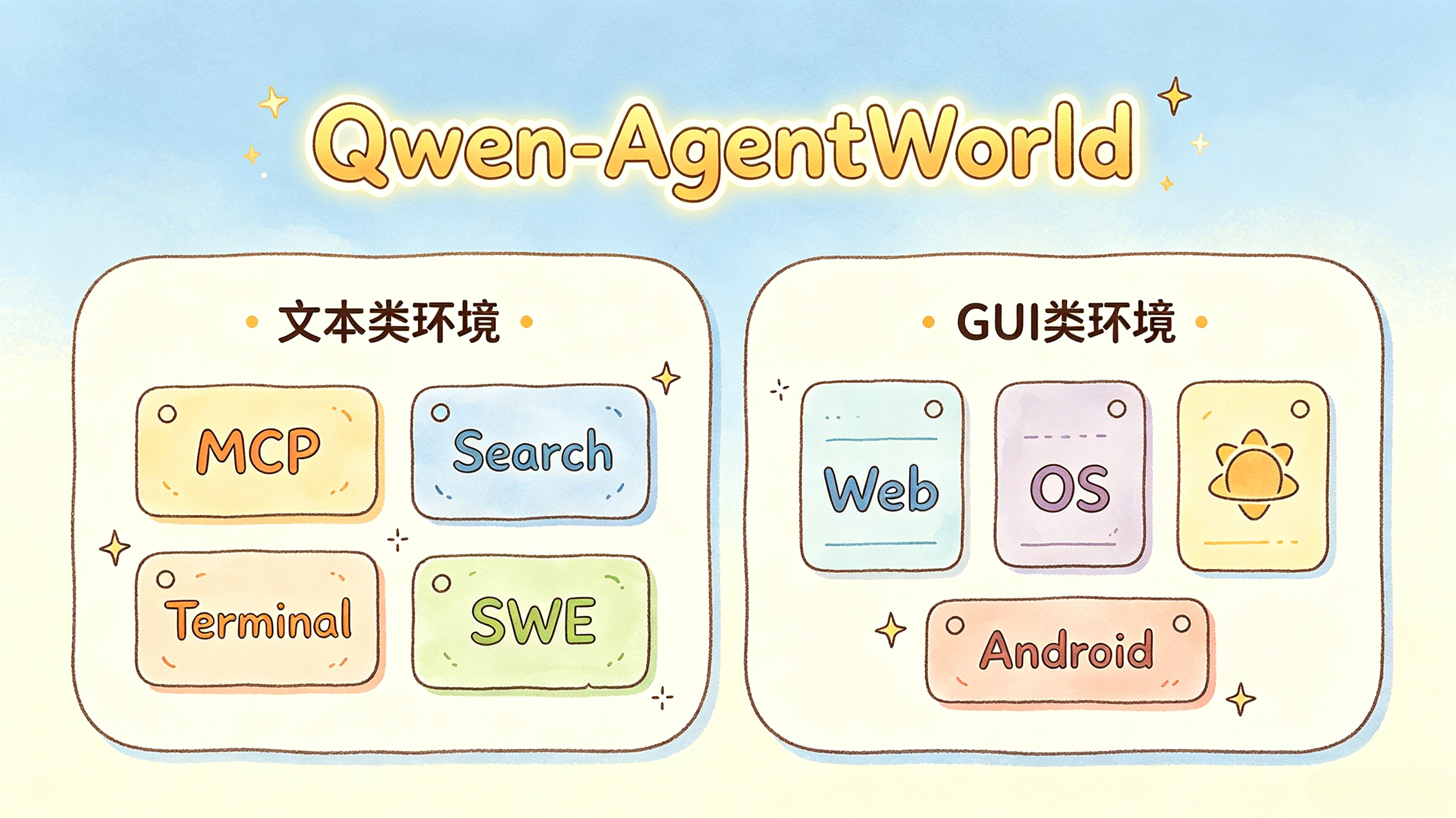
3. Seven Domains: Text and GUI Environments in One Model
Qwen-AgentWorld splits agent interaction scenarios into two large groups: text-based environments and GUI-based environments.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Text Environments GUI Environments │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Search │ │ OS │ │
│ │ Terminal│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Domain | Type | Description |
MCP | Text | Tool calling and Model Context Protocol interactions |
Search | Text | Search engine interaction and retrieval behavior |
Terminal | Text | Linux terminal command execution |
SWE | Text | Software engineering tasks, such as code fixes |
Web | GUI | Browser and webpage interaction |
OS | GUI | Desktop operating system interaction |
Android | GUI | Mobile app and Android-style UI interaction |
For the three GUI domains, observations are represented as renderable code rather than raw pixel frames. This lets a text-based world model cover visual environments without directly processing full image sequences.
The model was trained on more than 10 million real-world interaction trajectories across the seven domains.
4. Three-Stage Training Pipeline
Qwen-AgentWorld uses a connected three-stage training pipeline: CPT → SFT → RL.
Stage 1: CPT — Injecting Environment Knowledge
During continual pre-training, the model learns from large-scale real environment interaction trajectories. This stage embeds environment dynamics into the model weights.
The original article also mentions a turn-level information-theoretic loss mask. The goal is to identify which dialogue turns actually carry environment-state information and reduce noise from less useful turns.
Stage 2: SFT — Activating Chain-of-Thought Reasoning
Supervised fine-tuning turns next-state prediction into a chain-of-thought style reasoning pattern.
Instead of directly outputting a predicted result, the model learns to reason through why a state should change before generating the next observation.
Stage 3: RL — Refining Simulation Fidelity
The reinforcement learning stage uses hybrid reward signals, including the GSPO algorithm, to improve output quality.
The optimization focuses on:
Format correctness
Factual accuracy
Context consistency
Realism
Overall simulation quality
Emergent behaviors mentioned in the original article: Qwen-AgentWorld reportedly shows self-correction behavior, information-leakage prevention in search scenarios, and multi-step causal reasoning for some command-output predictions.
5. Open-Source Model List
Release | Parameters | Activated Parameters | Context Length | Positioning |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K tokens | Public, efficient open model |
Qwen-AgentWorld-397B-A17B | 397B | 17B | Not clearly listed in the original table | Flagship benchmark model |
AgentWorldBench | — | — | — | Evaluation benchmark |
35B-A3B Architecture Details
Base model: Qwen3.5-35B-A3B-Base
Model type: Causal Language Model / Language World Model
Architecture style: Hybrid linear attention + MoE
Hidden dimension: 2048
Layers: 40 layers
Layer layout: repeated groups with Gated DeltaNet, Gated Attention, and MoE components
Experts: 256 experts
Activated experts: 8 routed experts + 1 shared expert
Context length: 262,144 tokens
Recommended minimum context: 128K tokens for better long-trajectory simulation quality
Official Hugging Face documentation also notes that the model is compatible with Transformers, vLLM, and SGLang.
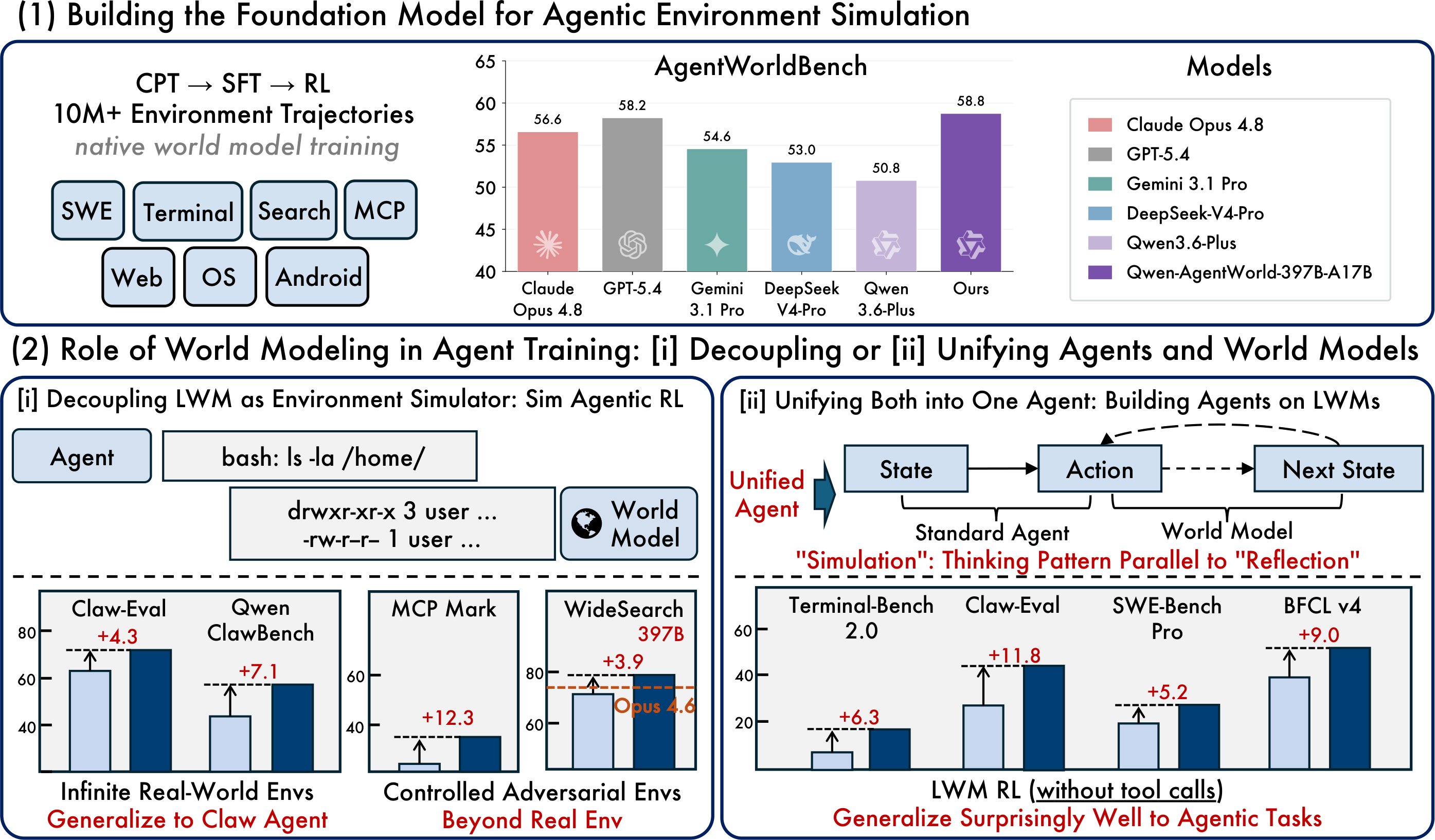
6. Performance Comparison: AgentWorldBench Results
AgentWorldBench scores each model across five dimensions: Format, Factuality, Consistency, Realism, and Quality. Scores are normalized to a 0–100 scale, where higher is better.
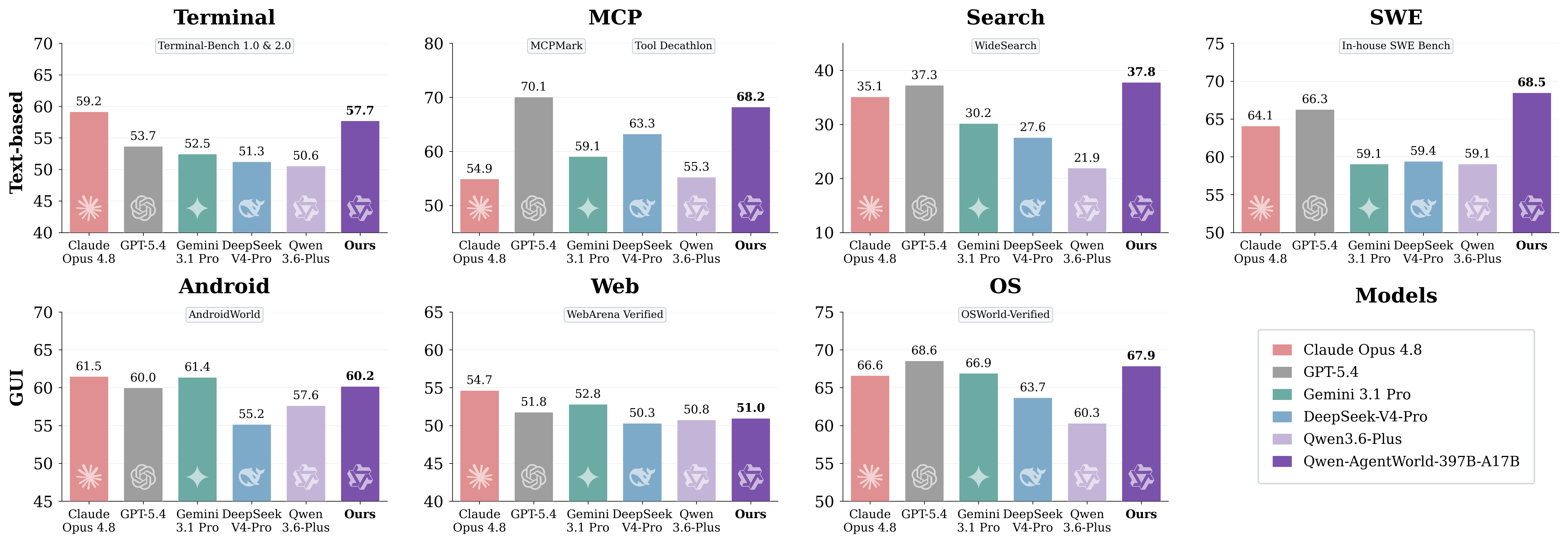
Full Ranking by Overall Score
Model | MCP | Search | Terminal | SWE | Android | Web | OS | Overall |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 Use We0 AI Build a showcase site and grow leads in minutesDescribe your idea once, and We0 AI can generate a showcase site, pages, and CMS, then help you attract customers and traffic after launch. Untitled-1 Fill Radius Generating | 64.44 | 54.90 | 48.55 | 60.85 | 54.74 |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Key takeaways from the original article:
Qwen-AgentWorld-397B-A17Breaches an overall score of 58.71 and ranks first in the listed AgentWorldBench table.Qwen-AgentWorld-35B-A3Bimproves by +8.66 points over the baseQwen3.5-35B-A3Bmodel.
Practical note: Treat benchmark numbers as reference data from the official benchmark setup. Real results will depend on hardware, prompt design, serving framework, context length, and the environment being simulated.
7. Four Application Patterns and Experimental Results
Pattern 1: Generalizable OOD Environment Expansion
The original article describes using Qwen-AgentWorld-397B-A17B for simulated RL across 4,000 out-of-distribution OpenClaw environments, then testing zero-shot generalization in new domains.
Training Method | Claw-Eval | QwenClawBench |
Base SFT | 65.4 | 47.9 |
Sim RL with a general model simulator | 66.7 | 47.8 |
Sim RL with Qwen-AgentWorld simulator | 69.7 | 55.0 |
Improvement | +4.3 | +7.1 |
Pattern 2: Controllable Simulation — MCP Targeted Perturbation
Controlled perturbations can expose weak points in an agent more effectively than standard real-environment training.
Configuration | Tool Decathlon | MCPMark |
Base SFT | 32.4 | 21.5 |
Sim RL without control | 31.5 | 24.6 |
Sim RL with control | 36.1 | 33.8 |
Improvement | +3.7 | +12.3 |
Pattern 3: Fictional World Construction — Search Domain
The Search-domain experiment uses a fictional but self-consistent search world for training, then evaluates generalization on real search tasks.
Configuration | WideSearch F1 Item | WideSearch F1 Row |
Base SFT, 35B | 34.02 | 13.72 |
+ Sim RL fictional world | 50.31 | 24.21 |
Improvement | +16.29 | +10.49 |
Pattern 4: Agent Foundation Model — LWM RL Warm-Up Transfer
The article also describes LWM RL warm-up as a way to improve downstream agent performance without extra RL fine-tuning on those specific tasks.
Metric | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
Base SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ LWM RL warm-up | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Improvement | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Highlight: The warm-up data comes from single-turn, non-agentic trajectories, yet the improvement transfers to more complex multi-turn tool-calling agent tasks. That suggests world-modeling knowledge can transfer beyond its original training format.
8. Quick Deployment Guide
Method 1: Deploy with SGLang
SGLang is recommended in the original article for fast serving.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3After startup, the OpenAI-compatible API endpoint is:
http://localhost:8000/v1Method 2: Deploy with vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeOfficial-docs note: The current Hugging Face model card also recommends using
--language-model-onlywith vLLM because the model architecture includes visual component definitions while the checkpoint contains language model weights. If vLLM initialization fails, try adding that flag.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeMethod 3: Local Inference with Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Method 4: Call Through an OpenAI-Compatible API
This method works after serving the model through SGLang or vLLM.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Best Practices
Recommended sampling:
temperature=0.6,top_p=0.95,top_k=20
Recommended output length: around 32,768 tokens for most long observations
Use the domain-specific system prompts from the repository
prompts/directory for better simulation qualityKeep context length at least
128Kwhen possible; the default model context is256K
9. AgentWorldBench Evaluation Workflow
If you want to test your own world model on AgentWorldBench, the original article gives a three-step workflow.
# 1. Clone the evaluation repository
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Download the evaluation dataset
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Install dependencies
pip install openai
cd eval
# Step 1: world model inference
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Step 2: LLM judge scoring. This requires an OpenAI API key.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Step 3: aggregate scores
python eval.py score --predictions ./results/judged.jsonlEach test sample includes ground-truth observation data from real environment execution. The benchmark evaluates world-modeling ability across format, factuality, consistency, realism, and quality.
10. Fine-Tuning Suggestions
If you want to customize Qwen-AgentWorld for a specific domain, the original article recommends three common fine-tuning frameworks.
Framework | Strength | Suitable Scenario |
High integration with ModelScope | Fast experiments and Alibaba ecosystem workflows | |
Active community and broad training strategy support | Practical engineering deployment | |
Strong memory optimization | Resource-constrained fine-tuning |
11. Source Notes and Image Handling
The original article includes several images related to Qwen-AgentWorld domains and benchmark results. These were kept in the relevant sections.
CSDN platform icons, promotion modules, author subscription blocks, QR codes, reward buttons, and unrelated recommendation images were removed according to the publishing requirements.
FAQ
What is Qwen-AgentWorld?
Qwen-AgentWorld is a language world model from the Qwen team. It predicts the next environment state after an agent takes an action, making it useful for agent simulation, training, and evaluation.
Is Qwen-AgentWorld the same as a normal chat model?
No. A normal chat model is mainly optimized for conversation and instruction following. Qwen-AgentWorld is trained as an environment simulator, so its main use case is predicting observations in agent interaction environments.
Which Qwen-AgentWorld model is publicly available?
Official pages list Qwen-AgentWorld-35B-A3B as the publicly released model weight. AgentWorldBench is also available as an evaluation benchmark. The larger 397B model appears in benchmark tables, but the public model release mainly points to the 35B-A3B version.
Can Qwen-AgentWorld be deployed with vLLM?
Yes. The Hugging Face model card includes a vLLM serving example. If you run into initialization issues, the official model card recommends adding --language-model-only because the checkpoint contains language model weights.
Can Qwen-AgentWorld be deployed with SGLang?
Yes. SGLang is one of the recommended serving options and can expose an OpenAI-compatible API endpoint. The model can then be called through local API requests.
Why does Qwen-AgentWorld need a long context window?
Agent environment simulation often depends on long interaction histories. A shorter context window may lose important state information, so the official guidance recommends keeping at least 128K tokens when possible.
What is AgentWorldBench used for?
AgentWorldBench is the benchmark released with Qwen-AgentWorld. It evaluates language world models across seven domains using dimensions such as format, factuality, consistency, realism, and quality.
Is Qwen-AgentWorld suitable for production use?
It can be useful for research, evaluation, simulation, and internal experiments. For production systems, you still need to evaluate latency, hardware cost, safety, prompt reliability, and whether simulated results match your real environment closely enough.
Related Tools
Qwen-AgentWorld GitHub: Official repository for Qwen-AgentWorld code, prompts, and evaluation workflow.
Qwen-AgentWorld-35B-A3B on Hugging Face: Official model page for the public 35B-A3B weights.
AgentWorldBench: Official benchmark dataset for evaluating language world models.
SGLang: A fast serving framework for large language models.
vLLM: A high-throughput inference engine for serving LLMs.
Transformers: Hugging Face library for local model loading and inference.
OpenAI Python SDK: Python client that can call OpenAI-compatible local model servers.
ms-swift: ModelScope’s training and fine-tuning framework for LLM workflows.
Related Links
Qwen-AgentWorld Technical Report: The official arXiv paper introducing the model, benchmark, and training setup.
Qwen-AgentWorld Official Blog: Qwen’s official release post for the project.
Qwen-AgentWorld GitHub Repository: Main source for prompts, evaluation scripts, and project documentation.
Qwen-AgentWorld-35B-A3B Model Card: Official Hugging Face page with deployment and inference examples.
AgentWorldBench Dataset: Official benchmark dataset used for model evaluation.
SGLang Documentation: Documentation for serving LLMs with SGLang.
vLLM Documentation: Documentation for high-throughput LLM inference and OpenAI-compatible serving.
LLaMA-Factory: Popular open-source framework for LLM fine-tuning and deployment experiments.


