
Die wichtigsten Erkenntnisse
Die teuersten Fehler bei Gemini 3.5 Flash sind stille Standardwerte, nicht Syntaxfehler.
Für viele Coding-Agents ist
lowder bessere Standard, als die meisten erwarten.Umfangreiche Agent-Schleifen über GitHub Copilot können durch die 14-fache Abrechnung deutlich teurer werden.
Bei We0 AI ist die Modellauswahl nur ein Teil des Workflows. Der Rest besteht darin, wie das Produkt erklärt, sichtbar gemacht und entdeckt wird.
gemini-3.5-flash wirkt leicht aufzurufen.
Genau deshalb wird es leicht unterschätzt. Schon eine kleine Migration von Code aus der Preview-Ära kann schlechtere Ausgaben, ein anderes Kostenprofil und teurere Multi-Turn-Schleifen verursachen, ohne jemals einen sichtbaren Fehler auszulösen.
Dieser Leitfaden konzentriert sich auf die drei wichtigsten Fallen, die Code-Struktur, die sie vermeidet, und eine praktische MCP-ähnliche Agent-Schleife, die du schnell anpassen kannst.
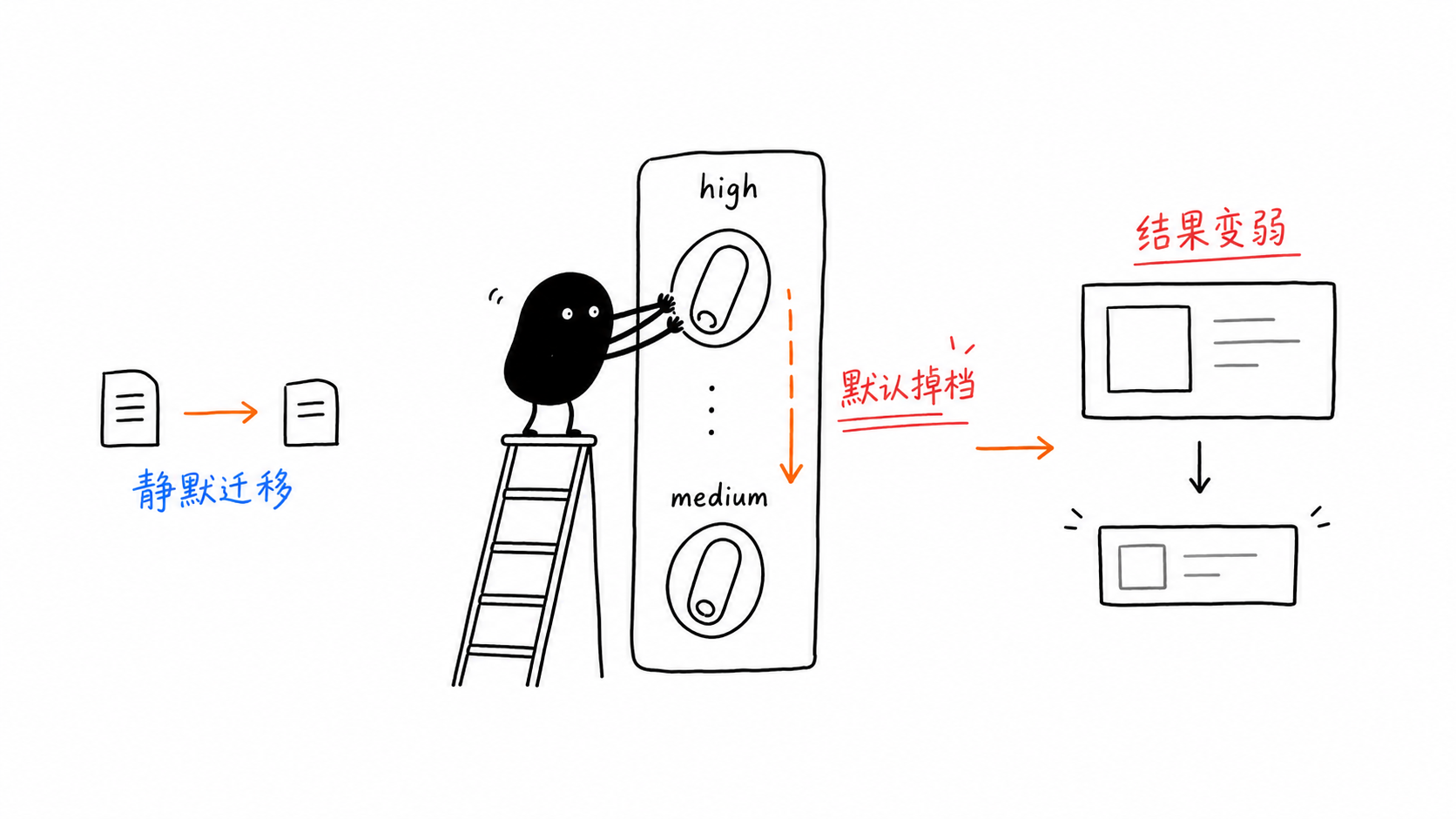
Falle 1: Der Standardwert von thinking_level wurde von Hoch auf Mittel gesenkt
Das ist gefährlich, weil nichts abstürzt.
Du übernimmst den alten Code, die Anfrage liefert weiterhin eine Antwort, aber das Modell schlussfolgert nicht mehr auf dem Niveau, das du vorausgesetzt hast.
Altes vs. neues mentales Modell
Wert
Was es bewirkt
Wann man es verwenden sollte
minimal
Schlussfolgern auf absolutem Minimum
Autocomplete, Klassifizierung, Single-Shot-Vervollständigungen
low
Neu abgestimmt für Code- und agentische Aufgaben
Coding-Agents, MCP-Tool-Schleifen, mehrstufige Workflows
medium
Neuer Standard — ausgewogen
Consumer-Chat, allgemeine Fragen und Antworten
high
Maximaler Schlussfolgerungsaufwand
Schwieriges Schlussfolgern, Debugging neuartiger Probleme, Mathematik, Planung
Der leicht zu machende Fehler
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)Der zweite Ausschnitt wird ausgeführt, aber die Standardwerte sind nicht mehr dieselben.
Eine sicherere Portierung
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)Die kontraintuitive Empfehlung
Bei vielen Coding-Agent-Workflows solltest du mit low beginnen, nicht mit high.
Der praktische Grund ist einfach:
schneller
günstiger
für tool-lastige Coding-Schleifen oft gut genug oder vergleichbar
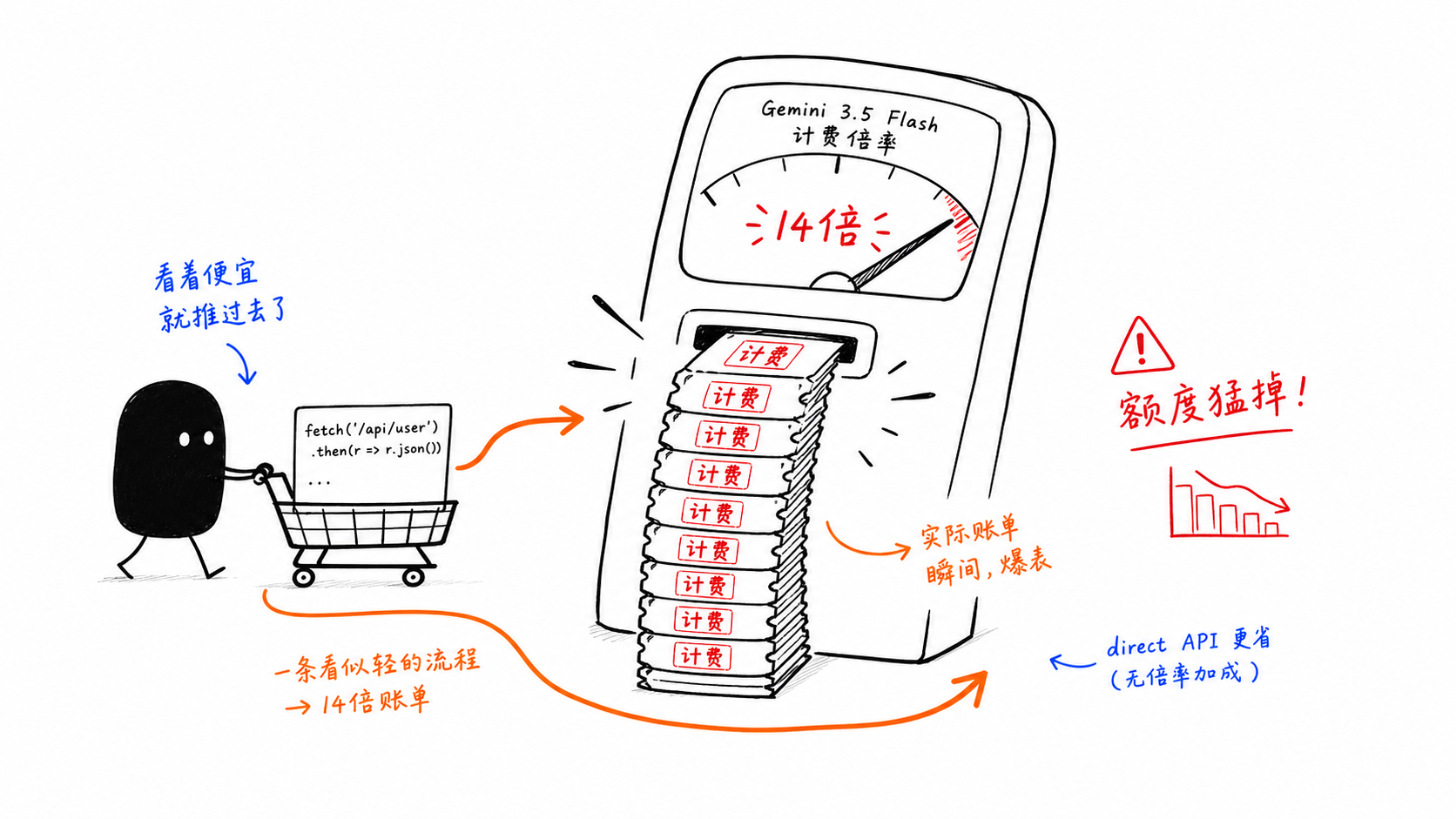
Falle 2: GitHub Copilot rechnet Gemini 3.5 Flash mit dem 14-Fachen ab
Das ist die kostspieligste Falle in diesem Artikel.
Das Problem ist nicht der Listenpreis des Modells. Es ist der Premium-Request-Multiplikator innerhalb von GitHub Copilot. Sobald Flash agentisch eingesetzt wird, verändert sich die Kostenstruktur schnell.
Deshalb teilen viele Teams den Pfad auf:
leichtgewichtige interaktive Nutzung bleibt innerhalb von Copilot
umfangreiche Schleifen und batchartige Workflows laufen über die direkte API
Crea un sitio de presentacion y capta leads en minutos
Describe tu idea una vez y We0 AI puede generar un sitio de presentacion, paginas y CMS, y ayudarte a atraer clientes y trafico tras el lanzamiento.
Una generación completa de proyectos para registro gratuito
Lo mejor para probar un flujo de generación completo y ver rápidamente el primer borrador del proyecto.
Architektur wird zu Kostenkontrolle.
Falle 3: Thought Preservation bläht Multi-Turn-Token-Kosten automatisch auf
Gemini 3.5 Flash übernimmt internes Schlussfolgern über mehrere Turns hinweg.
Das verbessert die Kohärenz, bedeutet aber auch, dass diese Gedanken in der späteren Token-Abrechnung weiterhin auftauchen können.
Bei langen Agent-Schleifen kann das den Token-Verbrauch erheblich erhöhen.
Praktische Gegenmaßnahmen
Chats an sauberen Phasengrenzen zurücksetzen
nur das zusammenfassen und weitertragen, was wichtig ist
Prompt-Caching für stabile Anweisungen und Tool-Definitionen verwenden
das Verhältnis von Thought-Tokens zu Prompt-Tokens im Zeitverlauf beobachten
Ein funktionierender MCP-Agent auf Gemini 3.5 Flash
Der Originalartikel enthält ein sehr nützliches End-to-End-Muster: ein Tool zum Lesen von Dateien, ein Tool zum Abrufen von URLs, eine standardmäßige Struktur für Funktionsdeklarationen und eine Schleife, die Tool-Antworten zurück an das Modell sendet.
Tool-Definitionen
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Agent-Loop-Muster
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
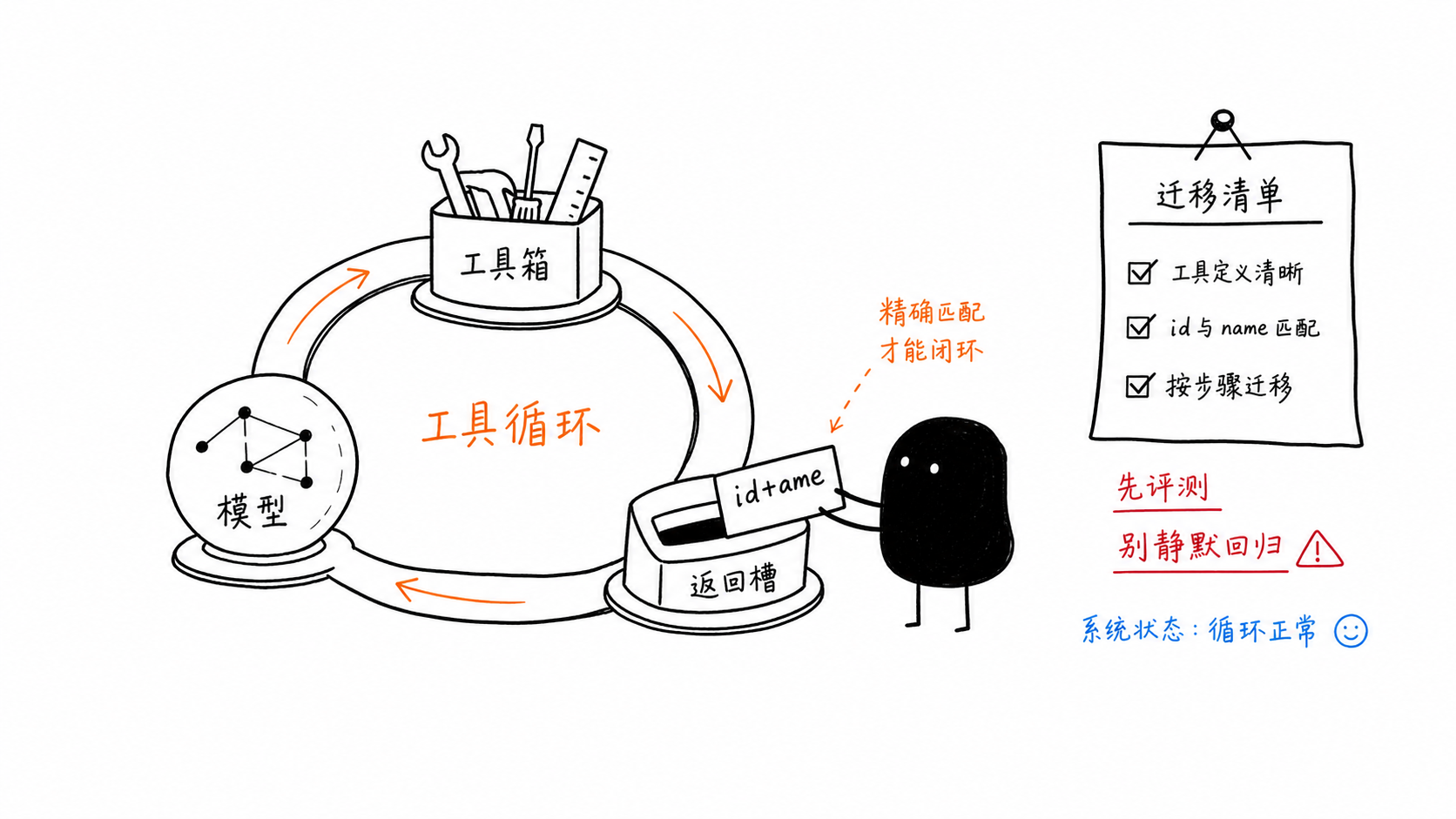
history.append(types.Content(role="tool", parts=tool_results))Die kleine, aber entscheidende Migrationsregel ist, dass Ihre Funktionsantwort sowohl mit id als auch mit name aus dem ursprünglichen Aufruf übereinstimmen muss.
Wann Sie stattdessen zu Antigravity greifen sollten
Tool-Loops manuell zu erstellen, ist für Prototypen in Ordnung. In der Produktion bauen Sie jedoch schnell Orchestrierung, Caching, Routing, Wiederholungslogik und Beobachtbarkeit neu auf.
Deshalb lautet die wichtigere Frage nicht nur: „Kann ich dieses Modell integrieren?“, sondern auch: „Wie viel Agenten-Infrastruktur werde ich gleich selbst besitzen und betreiben müssen?“
Kurze Migrations-Checkliste
Wenn Sie von gemini-3-flash-preview zu gemini-3.5-flash wechseln, prüfen Sie diese Punkte ausdrücklich:
die Modell-ID sorgfältig ersetzen
thinking_levelgezielt festlegenveraltete Sampling-Überschreibungen entfernen, es sei denn, Evaluierungen rechtfertigen sie
id und name in Tool-Antworten abgleichen
response.usage_metadata.thoughts_token_countprüfenbei der Preview bleiben für nicht unterstützte APIs, auf die Sie weiterhin angewiesen sind
Vorher-/Nachher-Evaluierungen durchführen
die Copilot-Abrechnung mit direkten API-Kosten vergleichen
Probieren Sie Gemini 3.5 Flash mit Ihren Tools aus
Wenn Ihr Ziel nicht nur das Testen von Prompts ist, sondern auch das Verbinden von Dateien, Repositories, APIs, Dokumentationen und Agenten-Workflows, benötigen Sie in der Regel mehr als nur einen rohen Modell-Endpunkt.
Bei We0 AI geht dieses Prinzip noch einen Schritt weiter: Der Agenten-Workflow ist nur die halbe Arbeit. Der Rest besteht darin, das Produkt durch Dokumentation, FAQs, Produktseiten, Showcase-Inhalte sowie SEO-/GEO-Flächen verständlich, auffindbar, empfehlenswert und konvertierend zu machen.
FAQ
Wie rufe ich Gemini 3.5 Flash aus Python auf?
Der Aufruf selbst ist kurz. Entscheidend ist, thinking_level ausdrücklich festzulegen, damit die Migration die Ausgabequalität nicht unbemerkt verschlechtert.
Welche Werte gibt es für thinking_level?
minimalfür sehr leichte Aufgabenlowfür Coding- und agentische Workflowsmediumals standardmäßige Voreinstellung im Consumer-Stilhighfür anspruchsvolleres Schlussfolgern und tiefere Planung
Warum kostet Gemini 3.5 Flash innerhalb von GitHub Copilot mehr?
Weil der Abrechnungs-Multiplikator die Wirtschaftlichkeit verändert. Bei intensiver Agentennutzung kann das die Kostenseite stärker dominieren als der Basispreis des Modells.
Was ist Thought Preservation?
Dabei trägt das Modell internes Schlussfolgern über mehrere Turns hinweg weiter. Das verbessert die Kohärenz über mehrere Interaktionen, erhöht aber auch die Wahrscheinlichkeit, dass die Token-Kosten im Laufe der Zeit steigen.
Ist Gemini 3.5 Flash gut für MCP?
Ja, insbesondere wenn Tool-Schemata, Antwortabgleich, thinking_level und Token-Budgetierung sorgfältig gehandhabt werden.


