
Conclusiones clave
Los errores más costosos de Gemini 3.5 Flash son los valores predeterminados silenciosos, no los errores de sintaxis.
Para muchos agentes de programación,
lowes un mejor valor predeterminado de lo que la gente espera.Los bucles intensivos de agentes a través de GitHub Copilot pueden volverse mucho más caros debido a la medición de 14x.
En We0 AI, la elección del modelo es solo una parte del flujo de trabajo. El resto es cómo se explica, se muestra y se descubre el producto.
gemini-3.5-flash parece fácil de invocar.
Precisamente por eso es fácil subestimarlo. Una pequeña migración desde código de la era de vista previa aún puede producir peores resultados, un perfil de costos diferente y bucles de varios turnos más caros sin que nunca aparezca un error visible.
Esta guía se centra en las tres trampas más importantes, la estructura de código que las evita y un bucle de agente de estilo MCP práctico que puedes adaptar rápidamente.
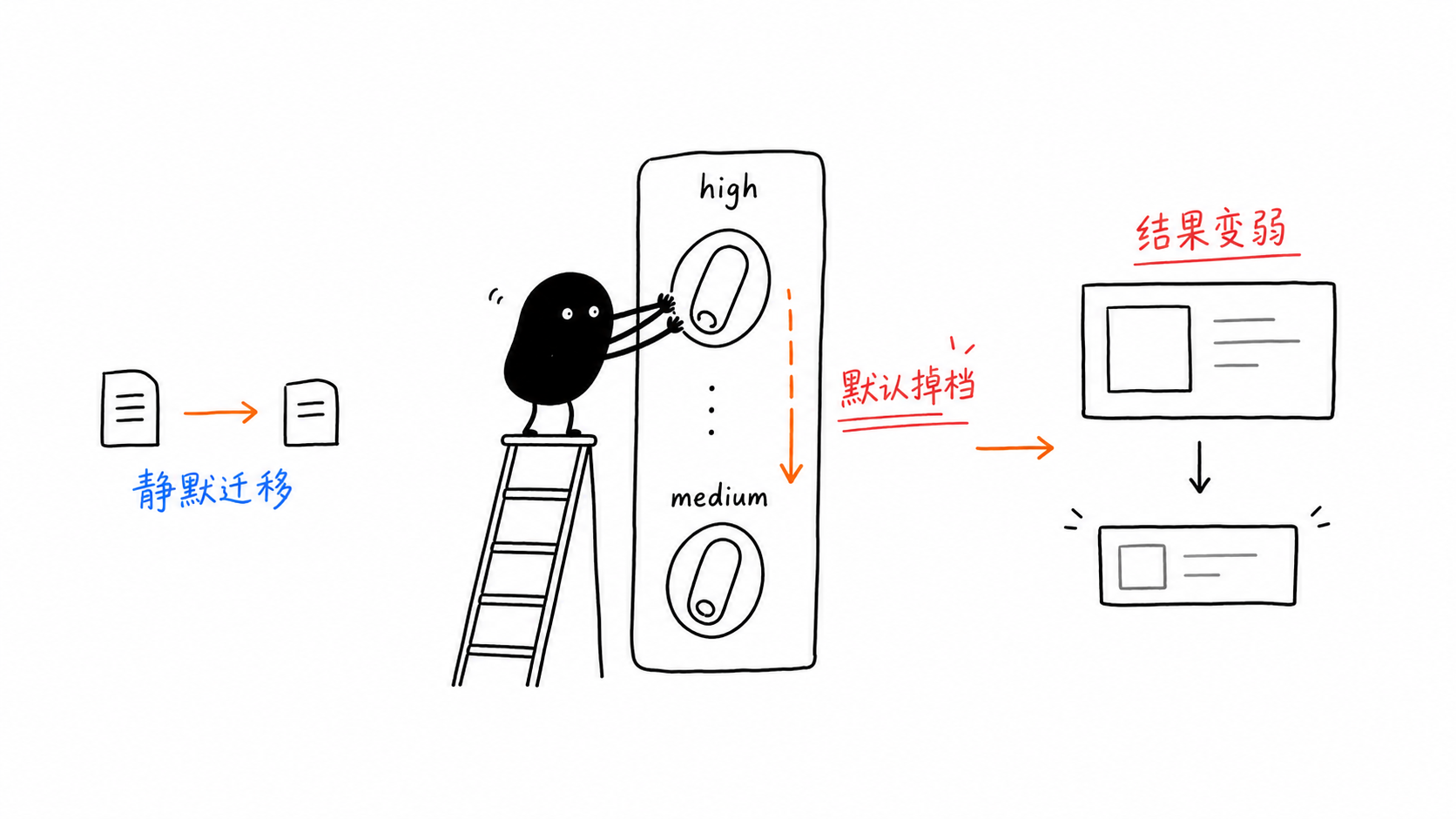
Trampa 1: El valor predeterminado de thinking_level bajó de alto a medio
Esto es peligroso porque nada falla.
Portas el código antiguo, la solicitud sigue devolviendo una respuesta, pero el modelo ya no está razonando al nivel que suponías.
Modelo mental antiguo vs. nuevo
Valor
Qué hace
Cuándo usarlo
minimal
Razonamiento mínimo indispensable
Autocompletado, clasificación, completados de una sola vez
low
Reajustado para código y tareas agénticas
Agentes de programación, bucles de herramientas MCP, flujos de trabajo de varios pasos
medium
Nuevo valor predeterminado — equilibrado
Chat de consumo, preguntas y respuestas generales
high
Máximo esfuerzo de razonamiento
Razonamiento complejo, depuración de problemas novedosos, matemáticas, planificación
El error fácil de cometer
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)El segundo fragmento se ejecuta, pero los valores predeterminados ya no son los mismos.
Una migración más segura
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)La recomendación contraintuitiva
Para muchos flujos de trabajo de agentes de programación, empieza con low, no con high.
La razón práctica es simple:
más rápido
más barato
a menudo es suficiente o comparable para bucles de programación con uso intensivo de herramientas
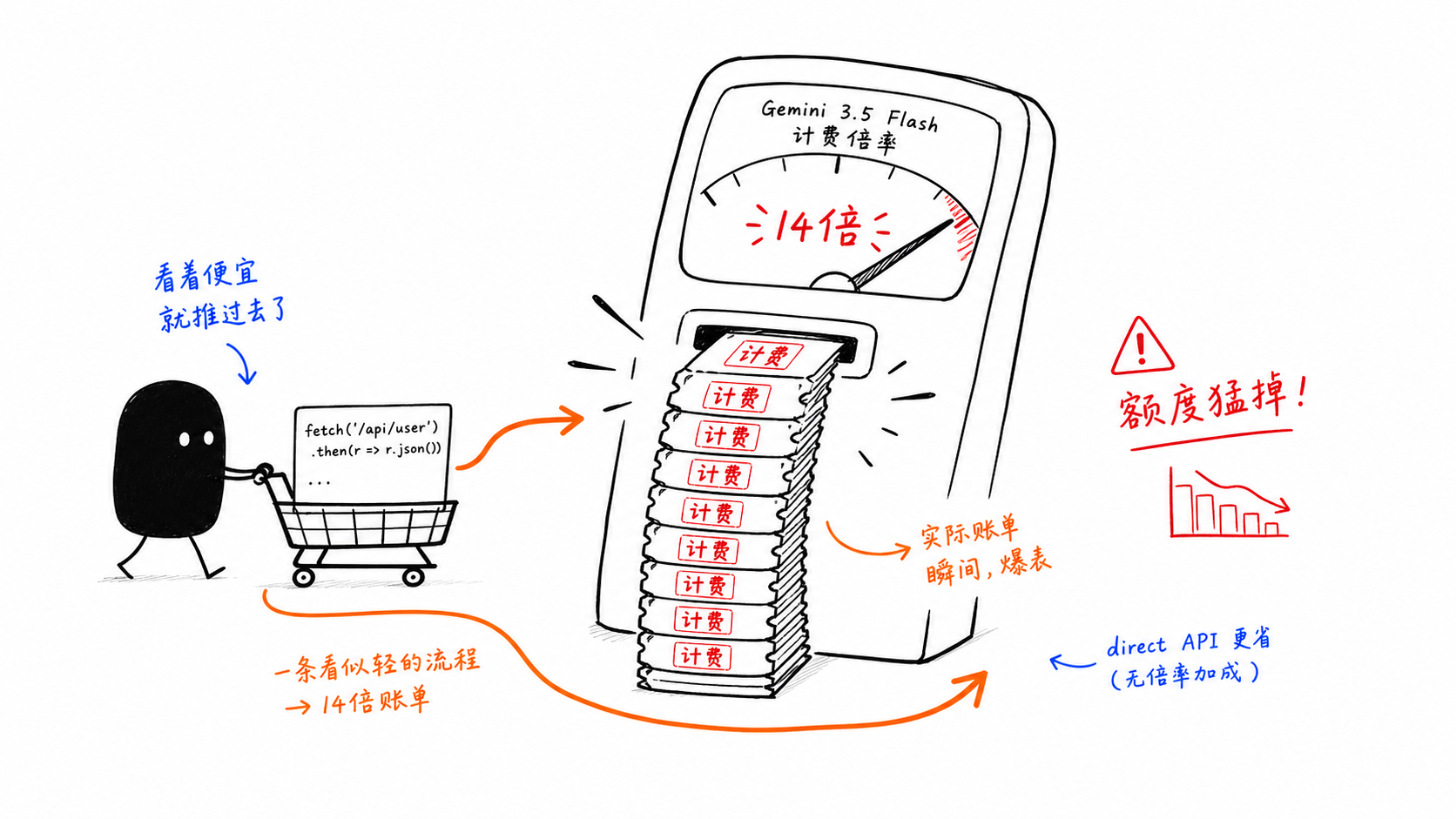
Trampa 2: GitHub Copilot factura Gemini 3.5 Flash a 14x
Esta es la trampa más costosa del artículo.
El problema no es el precio de lista del modelo. Es el multiplicador de solicitudes premium dentro de GitHub Copilot. Una vez que Flash se usa de forma agéntica, la estructura de costos cambia rápidamente.
Por eso muchos equipos dividen el camino:
el uso interactivo ligero permanece dentro de Copilot
los bucles intensivos y los flujos de trabajo de estilo por lotes pasan por la API directa
La arquitectura se convierte en control de costos.
Trampa 3: La preservación del pensamiento infla automáticamente las facturas de tokens en varios turnos
Gemini 3.5 Flash arrastra el razonamiento interno de un turno a otro.
Eso mejora la coherencia, pero también significa que esos pensamientos pueden seguir apareciendo en el cómputo de tokens posteriores.
En bucles largos de agentes, eso puede aumentar sustancialmente el uso de tokens.
Mitigaciones prácticas
reinicia los chats en límites de fase limpios
resume y arrastra solo lo que importa
usa caché de prompts para instrucciones estables y definiciones de herramientas
vigila con el tiempo la proporción entre tokens de pensamientos y tokens del prompt
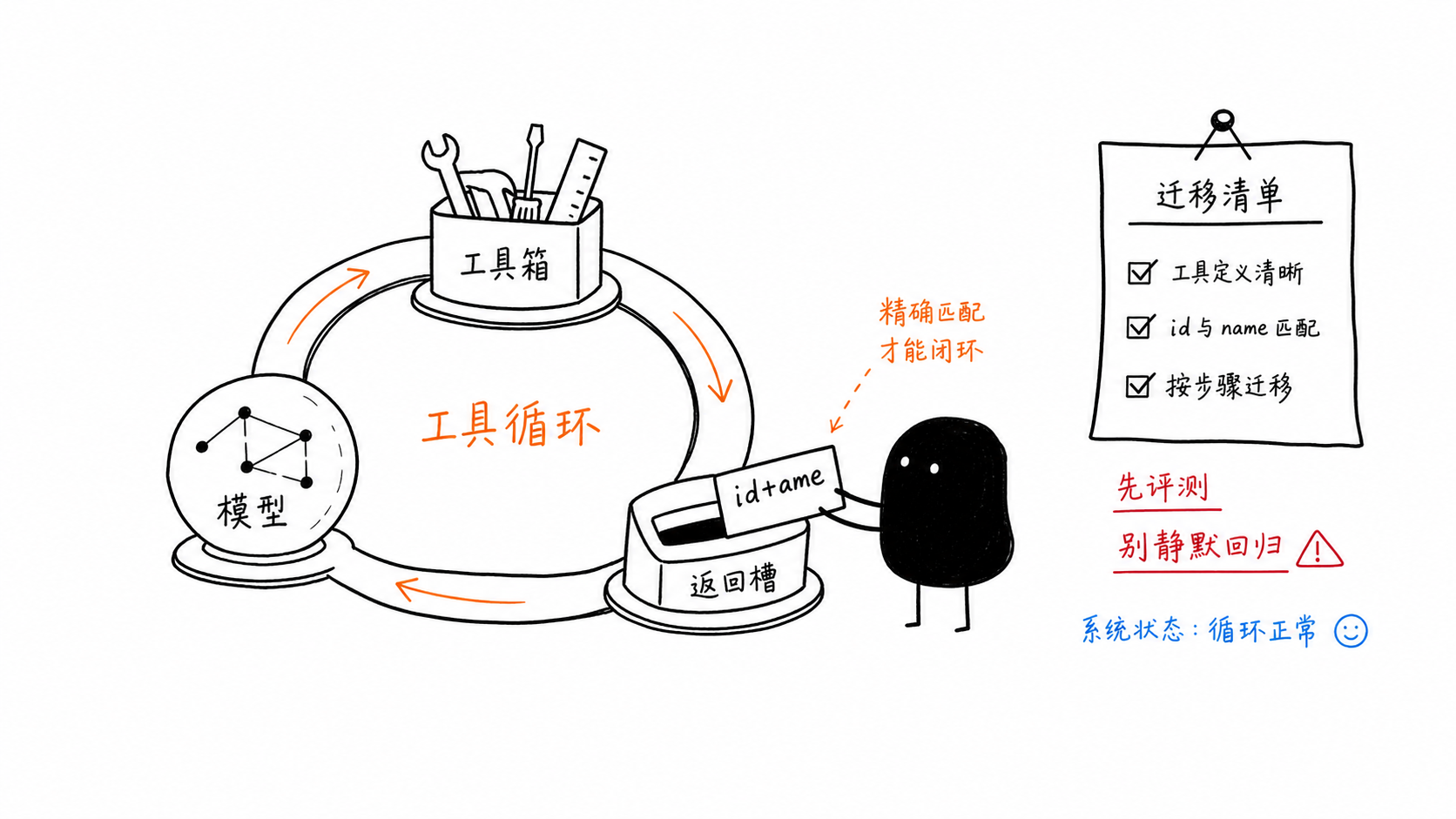
Un agente MCP funcional en Gemini 3.5 Flash
El artículo original incluye un patrón integral muy útil: una herramienta de lectura de archivos, una herramienta de obtención de URL, una forma estándar de declaración de funciones y un bucle que devuelve las respuestas de las herramientas al modelo.
Definiciones de herramientas
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Leer un archivo local y devolver su contenido como texto.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Ruta absoluta al archivo"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Obtener una URL y devolver el cuerpo de la respuesta como texto.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "URL completamente calificada"
}
},
"required": ["url"],
},
)Patrón de bucle de agente
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Herramienta desconocida: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
history.append(types.Content(role="tool", parts=tool_results))La regla de migración pequeña pero crucial es que la respuesta de tu función debe coincidir tanto con el id como con el name de la llamada original.
Cuándo recurrir a Antigravity en su lugar
Construir manualmente bucles de herramientas está bien para prototipos. En producción, rápidamente terminas reconstruyendo orquestación, caché, enrutamiento, reintentos y observabilidad.
Por eso, la pregunta más importante no es solo “¿puedo conectar este modelo?”, sino “¿cuánta infraestructura de agentes estoy a punto de tener que asumir por mi cuenta?”
Lista rápida de verificación para la migración
Si te estás moviendo de gemini-3-flash-preview a gemini-3.5-flash, verifica explícitamente estos puntos:
reemplaza cuidadosamente el id del modelo
establece
thinking_levelintencionalmenteelimina las anulaciones de muestreo obsoletas, a menos que las evaluaciones las justifiquen
haz coincidir id y name en las respuestas de herramientas
inspecciona
response.usage_metadata.thoughts_token_countmantén la versión preview para las API no compatibles de las que aún dependes
ejecuta evaluaciones antes y después
compara la medición de Copilot con los costos directos de la API
Prueba Gemini 3.5 Flash con tus herramientas
Si tu objetivo no es solo probar prompts, sino conectar archivos, repositorios, API, documentación y flujos de trabajo de agentes, por lo general necesitas algo más que un endpoint de modelo sin procesar.
En We0 AI, ese mismo principio va un paso más allá: el flujo de trabajo del agente es solo la mitad del trabajo. El resto consiste en hacer que el producto sea comprensible, localizable, recomendable y convertible mediante documentación, preguntas frecuentes, páginas de producto, contenido de showcase y superficies de SEO / GEO.
Preguntas frecuentes
¿Cómo llamo a Gemini 3.5 Flash desde Python?
La llamada en sí es corta. La parte importante es establecer thinking_level explícitamente para que la migración no degrade silenciosamente la calidad de la salida.
¿Cuáles son los valores de thinking_level?
minimalpara tareas muy ligeraslowpara programación y flujos de trabajo agénticosmediumcomo valor predeterminado de estilo de consumohighpara razonamiento más complejo y planificación más profunda
¿Por qué Gemini 3.5 Flash cuesta más dentro de GitHub Copilot?
Porque el multiplicador de medición cambia la economía. Para un uso intensivo de agentes, eso puede dominar la estructura de costos más que el precio base del modelo.
¿Qué es la preservación del pensamiento?
Es que el modelo mantenga el razonamiento interno a lo largo de varios turnos. Eso ayuda a la coherencia en múltiples turnos, pero también aumenta la probabilidad de que los costos de tokens crezcan con el tiempo.
¿Es Gemini 3.5 Flash bueno para MCP?
Sí, especialmente cuando los esquemas de herramientas, la coincidencia de respuestas, thinking_level y la gestión del presupuesto de tokens se manejan con cuidado.


