
Principais conclusões
Os erros mais caros do Gemini 3.5 Flash são os padrões silenciosos, não os erros de sintaxe.
Para muitos agentes de programação,
lowé um padrão melhor do que as pessoas esperam.Loops intensivos de agentes através do GitHub Copilot podem se tornar muito mais caros por causa da cobrança 14x.
Na We0 AI, a escolha do modelo é apenas parte do fluxo de trabalho. O restante é como o produto é explicado, apresentado e descoberto.
gemini-3.5-flash parece fácil de chamar.
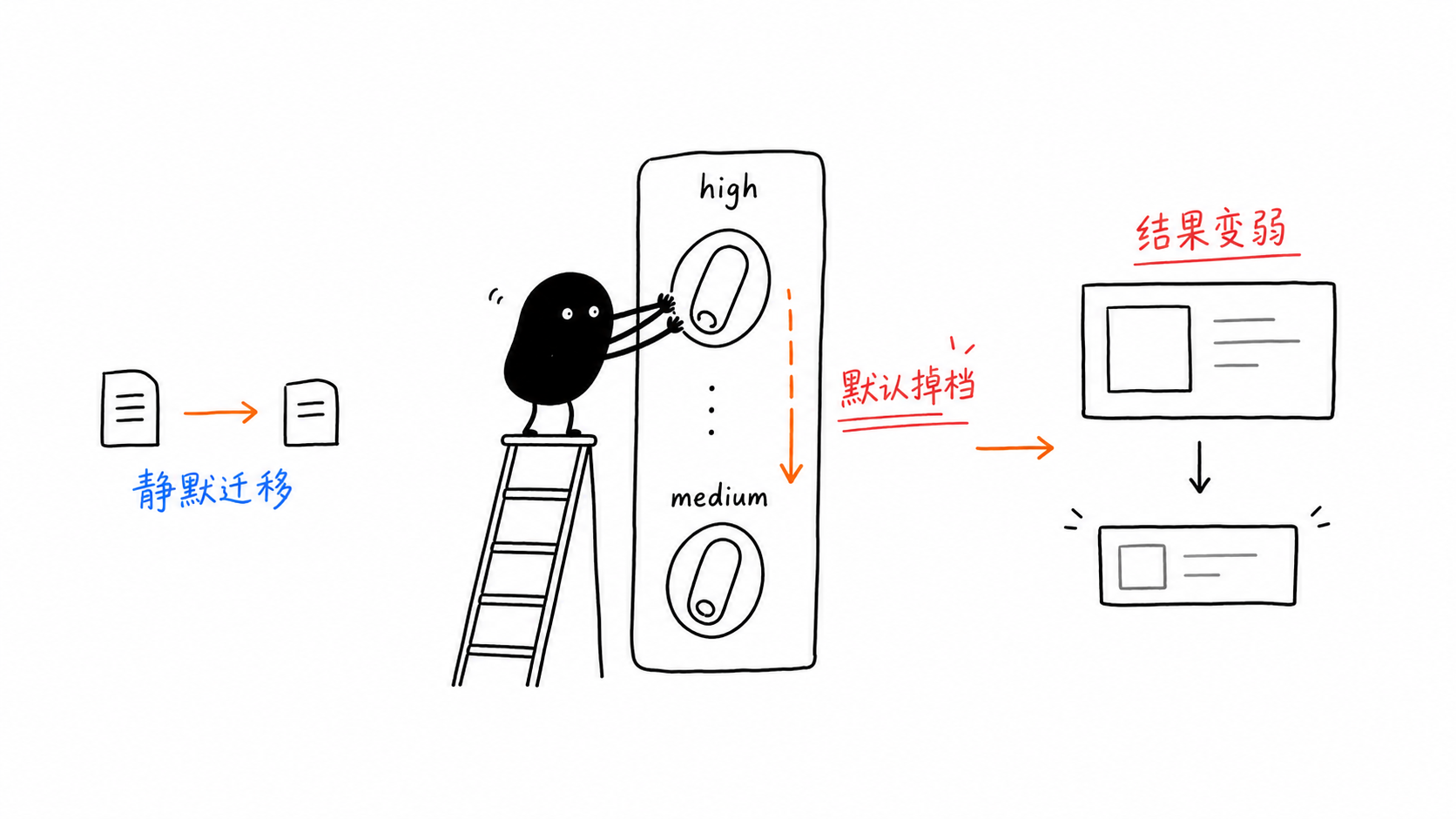
É exatamente por isso que é fácil subestimá-lo. Uma pequena migração de código da era de pré-visualização ainda pode produzir saídas piores, um perfil de custo diferente e loops de múltiplas interações mais caros, sem jamais gerar um erro visível.
Este guia se concentra nas três armadilhas mais importantes, no formato de código que as evita e em um loop prático de agente no estilo MCP que você pode adaptar rapidamente.
Armadilha 1: O padrão de thinking_level caiu de alto para médio
Isso é perigoso porque nada falha.
Você porta o código antigo, a solicitação ainda retorna, mas o modelo já não está mais raciocinando no nível que você supunha.
Modelo mental antigo vs. novo
Valor
O que faz
Quando usar
minimal
Raciocínio mínimo indispensável
Autocompletar, classificação, conclusões em uma única tentativa
low
Reajustado para código e tarefas agentivas
Agentes de programação, loops de ferramentas MCP, fluxos de trabalho em várias etapas
medium
Novo padrão — equilibrado
Chat para consumidores, perguntas e respostas gerais
high
Esforço máximo de raciocínio
Raciocínio difícil, depuração de problemas inéditos, matemática, planejamento
O erro fácil de cometer
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)O segundo trecho é executado, mas os padrões já não são mais os mesmos.
Uma migração mais segura
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)A recomendação contraintuitiva
Para muitos fluxos de trabalho com agentes de programação, comece com low, não com high.
O motivo prático é simples:
mais rápido
mais barato
muitas vezes é suficiente ou comparável para loops de programação com uso intenso de ferramentas
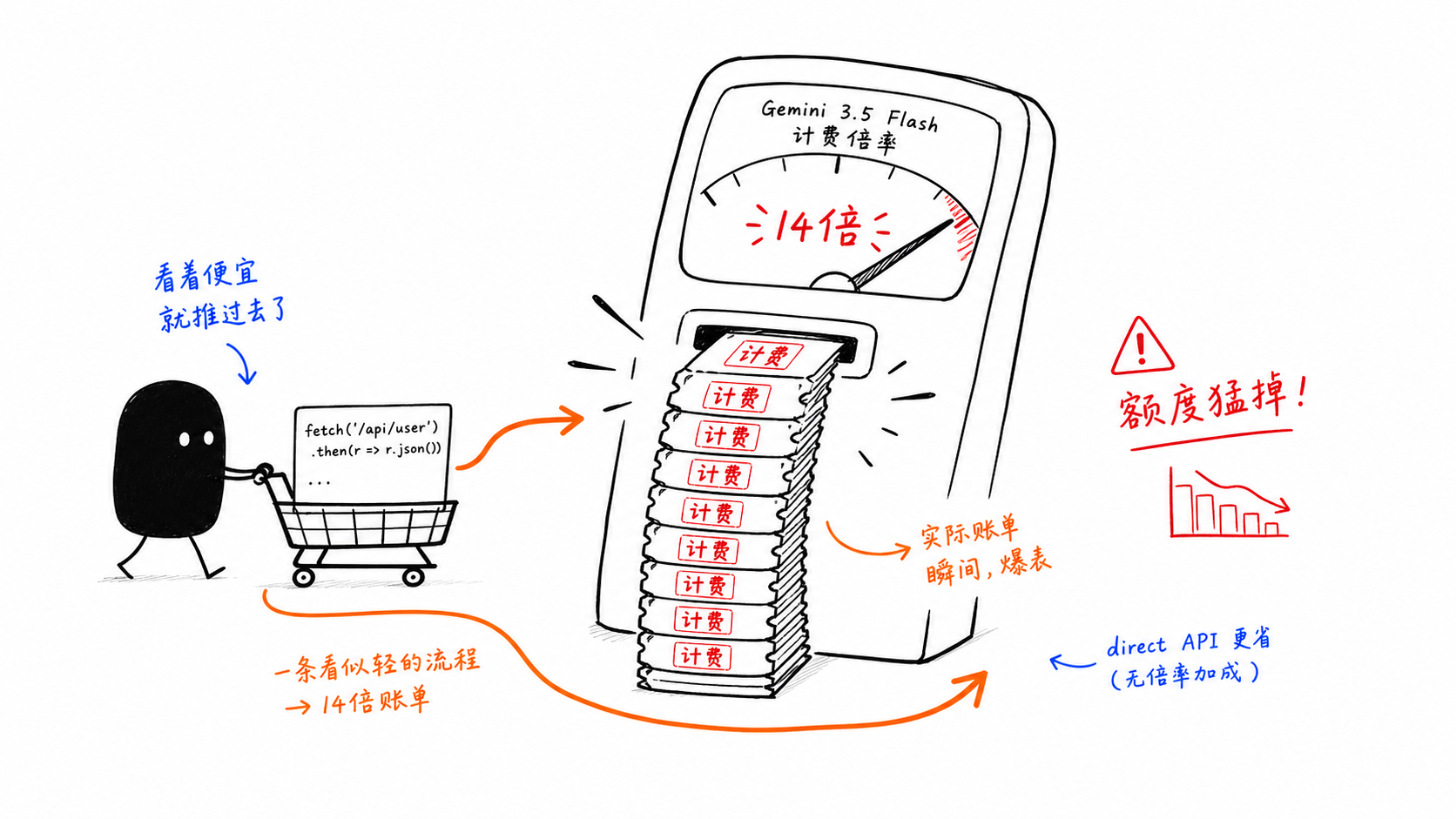
Armadilha 2: o GitHub Copilot cobra o Gemini 3.5 Flash em 14x
Esta é a armadilha mais cara do artigo.
O problema não é o preço de tabela do modelo. É o multiplicador de solicitações premium dentro do GitHub Copilot. Quando o Flash é usado de forma agentiva, o perfil de custo muda rapidamente.
É por isso que muitas equipes dividem o caminho:
o uso interativo leve permanece dentro do Copilot
loops pesados e fluxos de trabalho em estilo batch passam pela API direta
A arquitetura passa a ser controle de custos.
Armadilha 3: A preservação de pensamentos infla automaticamente as cobranças de tokens em múltiplas interações
O Gemini 3.5 Flash carrega adiante o raciocínio interno entre interações.
Isso melhora a coerência, mas também significa que esses pensamentos podem continuar aparecendo na contabilização de tokens posteriores.
Em loops longos de agentes, isso pode aumentar substancialmente o uso de tokens.
Mitigações práticas
redefina os chats em limites limpos entre fases
resuma e leve adiante apenas o que importa
use cache de prompts para instruções estáveis e definições de ferramentas
acompanhe ao longo do tempo a proporção entre tokens de pensamentos e tokens de prompt
Um agente MCP funcional no Gemini 3.5 Flash
O artigo de origem inclui um padrão de ponta a ponta muito útil: uma ferramenta de leitura de arquivos, uma ferramenta de busca de URL, um formato padrão de declaração de função e um loop que envia as respostas das ferramentas de volta ao modelo.
Definições de ferramentas
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Padrão de loop de agente
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
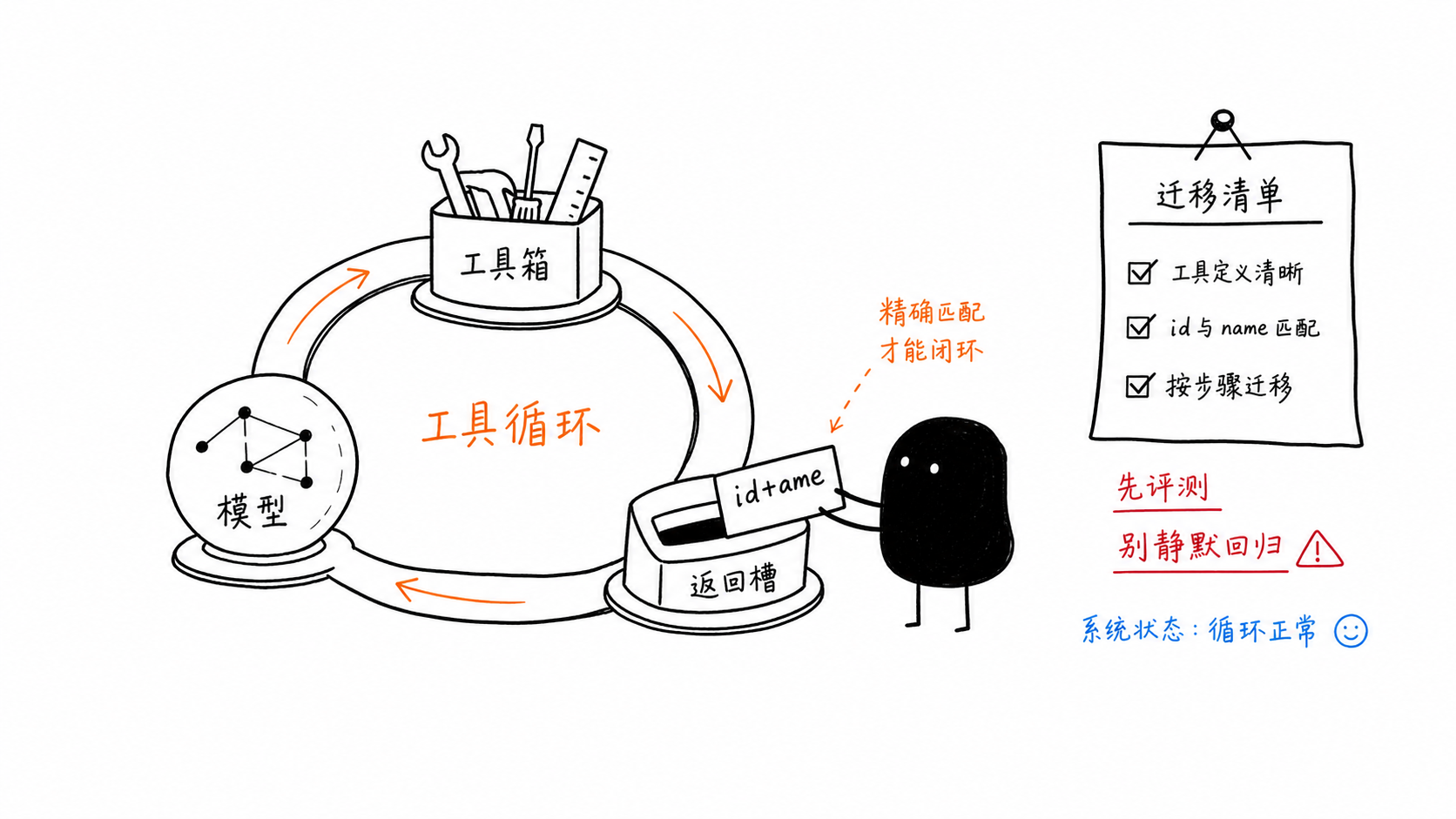
history.append(types.Content(role="tool", parts=tool_results))A regra de migração pequena, mas crucial, é que a resposta da sua função precisa corresponder tanto ao id quanto ao name da chamada original.
Quando optar pelo Antigravity em vez disso
Construir loops de ferramentas manualmente é aceitável para protótipos. Em produção, você rapidamente acaba reconstruindo orquestração, cache, roteamento, tentativas, repetição e observabilidade.
É por isso que a pergunta mais importante não é apenas “consigo conectar este modelo?”, mas “quanta infraestrutura de agente estou prestes a assumir por conta própria?”
Checklist rápido de migração
Se você está migrando de gemini-3-flash-preview para gemini-3.5-flash, verifique explicitamente estes itens:
substitua o ID do modelo com cuidado
defina
thinking_levelde forma intencionalremova substituições de amostragem obsoletas, a menos que as avaliações as justifiquem
faça corresponder id e name nas respostas das ferramentas
inspecione
response.usage_metadata.thoughts_token_countmantenha a versão preview para APIs não compatíveis das quais você ainda depende
execute avaliações antes/depois
compare a medição do Copilot com os custos diretos da API
Experimente o Gemini 3.5 Flash com suas ferramentas
Se o seu objetivo não é apenas testar prompts, mas conectar arquivos, repositórios, APIs, documentos e fluxos de trabalho de agentes em conjunto, normalmente você precisa de mais do que um endpoint bruto de modelo.
Na We0 AI, esse mesmo princípio vai um passo além: o fluxo de trabalho do agente é apenas metade do trabalho. O restante é tornar o produto compreensível, pesquisável, recomendável e conversível por meio de documentação, FAQs, páginas de produto, conteúdo de vitrine e superfícies de SEO / GEO.
FAQ
Como chamo o Gemini 3.5 Flash a partir de Python?
A chamada em si é curta. A parte importante é definir thinking_level explicitamente para que a migração não degrade silenciosamente a qualidade da saída.
Quais são os valores de thinking_level?
minimalpara tarefas muito leveslowpara codificação e fluxos de trabalho agentivosmediumcomo padrão no estilo de consumohighpara raciocínio mais difícil e planejamento mais profundo
Por que o Gemini 3.5 Flash custa mais dentro do GitHub Copilot?
Porque o multiplicador de medição altera a economia. Para uso intenso de agentes, isso pode pesar mais na estrutura de custos do que o preço base do modelo.
O que é preservação de pensamento?
É o modelo carregando o raciocínio interno adiante ao longo dos turnos. Isso ajuda na coerência em múltiplos turnos, mas também aumenta a chance de que os custos de tokens cresçam com o tempo.
O Gemini 3.5 Flash é bom para MCP?
Sim, especialmente quando os esquemas de ferramentas, a correspondência de respostas, thinking_level e o gerenciamento do orçamento de tokens são tratados com cuidado.


