
Points clés
Les erreurs les plus coûteuses de Gemini 3.5 Flash sont les valeurs par défaut silencieuses, pas les erreurs de syntaxe.
Pour de nombreux agents de codage,
lowest une meilleure valeur par défaut que ce que les gens imaginent.Les boucles d’agents intensives via GitHub Copilot peuvent devenir bien plus coûteuses en raison d’une tarification multipliée par 14.
Chez We0 AI, le choix du modèle ne représente qu’une partie du workflow. Le reste dépend de la manière dont le produit est expliqué, mis en avant et découvert.
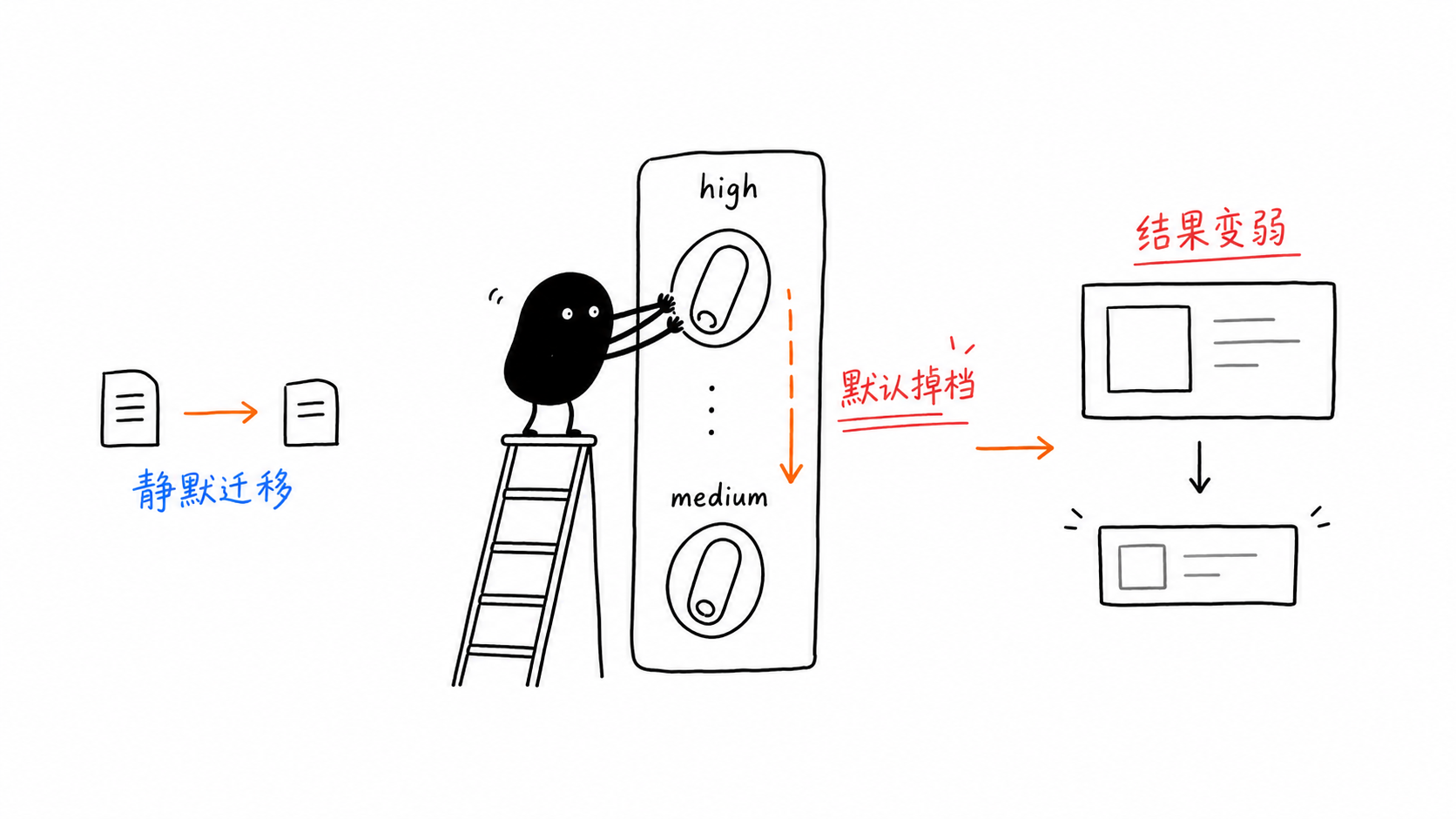
gemini-3.5-flash semble facile à appeler.
C’est précisément pour cela qu’il est facile de le sous-estimer. Une petite migration depuis du code de l’ère preview peut toujours produire de moins bons résultats, un profil de coûts différent et des boucles multi-tours plus onéreuses sans jamais générer d’erreur visible.
Ce guide se concentre sur les trois pièges les plus importants, la structure de code qui permet de les éviter, ainsi qu’une boucle d’agent de style MCP pratique que vous pouvez adapter rapidement.
Piège 1 : la valeur par défaut de thinking_level est passée de élevée à moyenne
C’est dangereux parce que rien ne plante.
Vous portez l’ancien code, la requête renvoie toujours un résultat, mais le modèle ne raisonne plus au niveau que vous supposiez.
Ancien vs nouveau modèle mental
Valeur
Ce qu’elle fait
Quand l’utiliser
minimal
Raisonnement strictement minimal
Autocomplétion, classification, complétions en une seule tentative
low
Réajusté pour le code et les tâches agentiques
Agents de codage, boucles d’outils MCP, workflows en plusieurs étapes
medium
Nouvelle valeur par défaut — équilibrée
Chat grand public, questions-réponses générales
high
Effort de raisonnement maximal
Raisonnement complexe, débogage de problèmes inédits, mathématiques, planification
L’erreur facile à commettre
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)Le deuxième extrait s’exécute, mais les valeurs par défaut ne sont plus les mêmes.
Un portage plus sûr
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)La recommandation contre-intuitive
Pour de nombreux workflows d’agents de codage, commencez avec low, pas avec high.
La raison pratique est simple :
plus rapide
moins cher
souvent suffisant ou comparable pour les boucles de codage fortement axées sur les outils
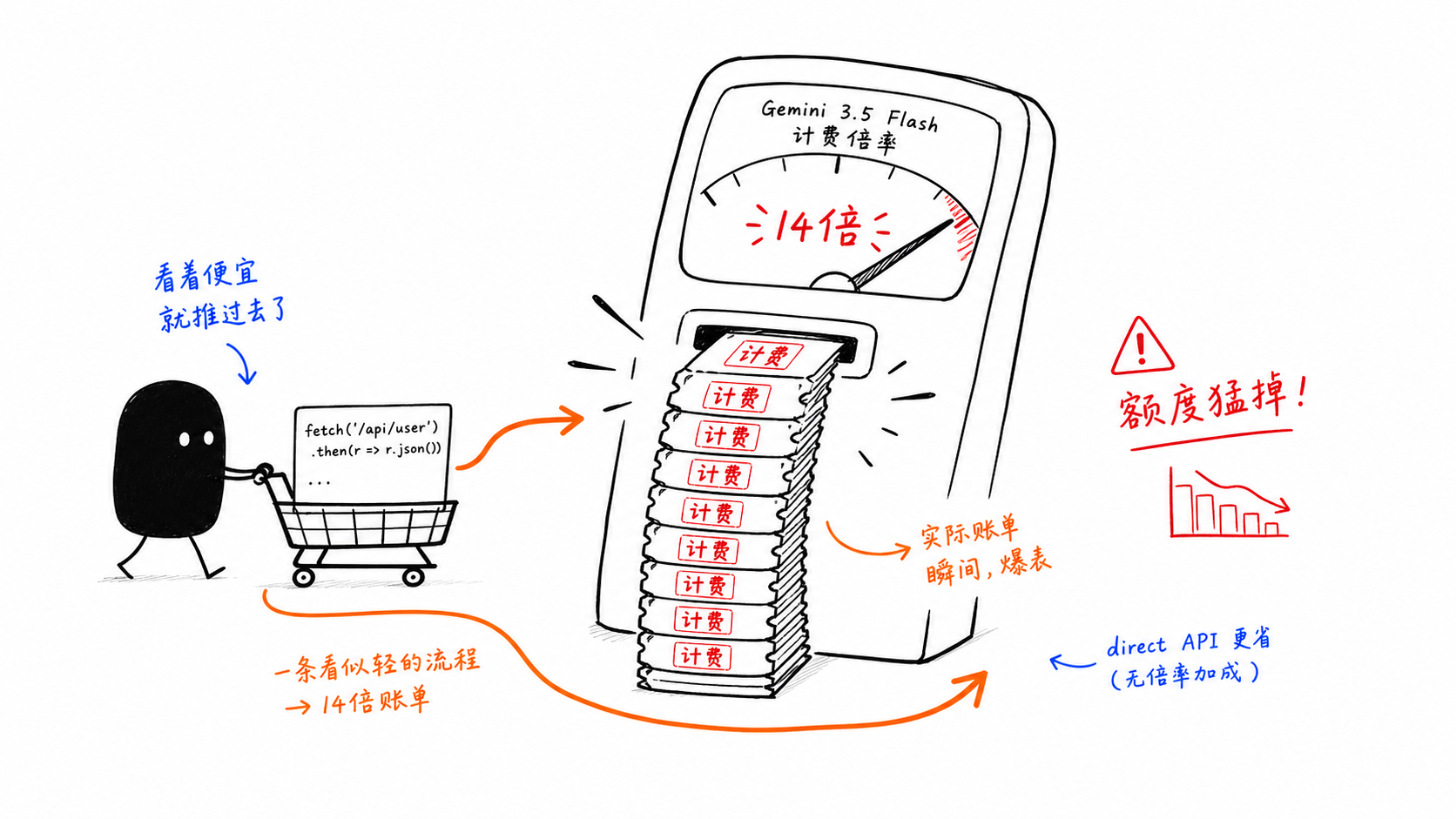
Piège 2 : GitHub Copilot facture Gemini 3.5 Flash à 14x
C’est le piège le plus coûteux de cet article.
Le problème n’est pas le prix catalogue du modèle. C’est le multiplicateur de requêtes premium au sein de GitHub Copilot. Dès que Flash est utilisé de manière agentique, la structure des coûts change rapidement.
C’est pourquoi de nombreuses équipes séparent le parcours :
l’usage interactif léger reste dans Copilot
les boucles lourdes et les workflows de type batch passent par l’API directe
L’architecture devient un moyen de contrôle des coûts.
Piège 3 : la préservation des pensées gonfle automatiquement les factures de tokens en multi-tours
Gemini 3.5 Flash conserve son raisonnement interne d’un tour à l’autre.
Cela améliore la cohérence, mais cela signifie aussi que ces pensées peuvent continuer à apparaître dans le calcul des tokens des tours suivants.
Pour les longues boucles d’agents, cela peut augmenter considérablement l’usage des tokens.
Mesures d’atténuation pratiques
réinitialiser les chats à des limites de phase nettes
résumer et ne conserver que ce qui compte
utiliser le cache de prompts pour les instructions stables et les définitions d’outils
surveiller dans le temps le ratio entre les tokens de pensées et les tokens de prompt
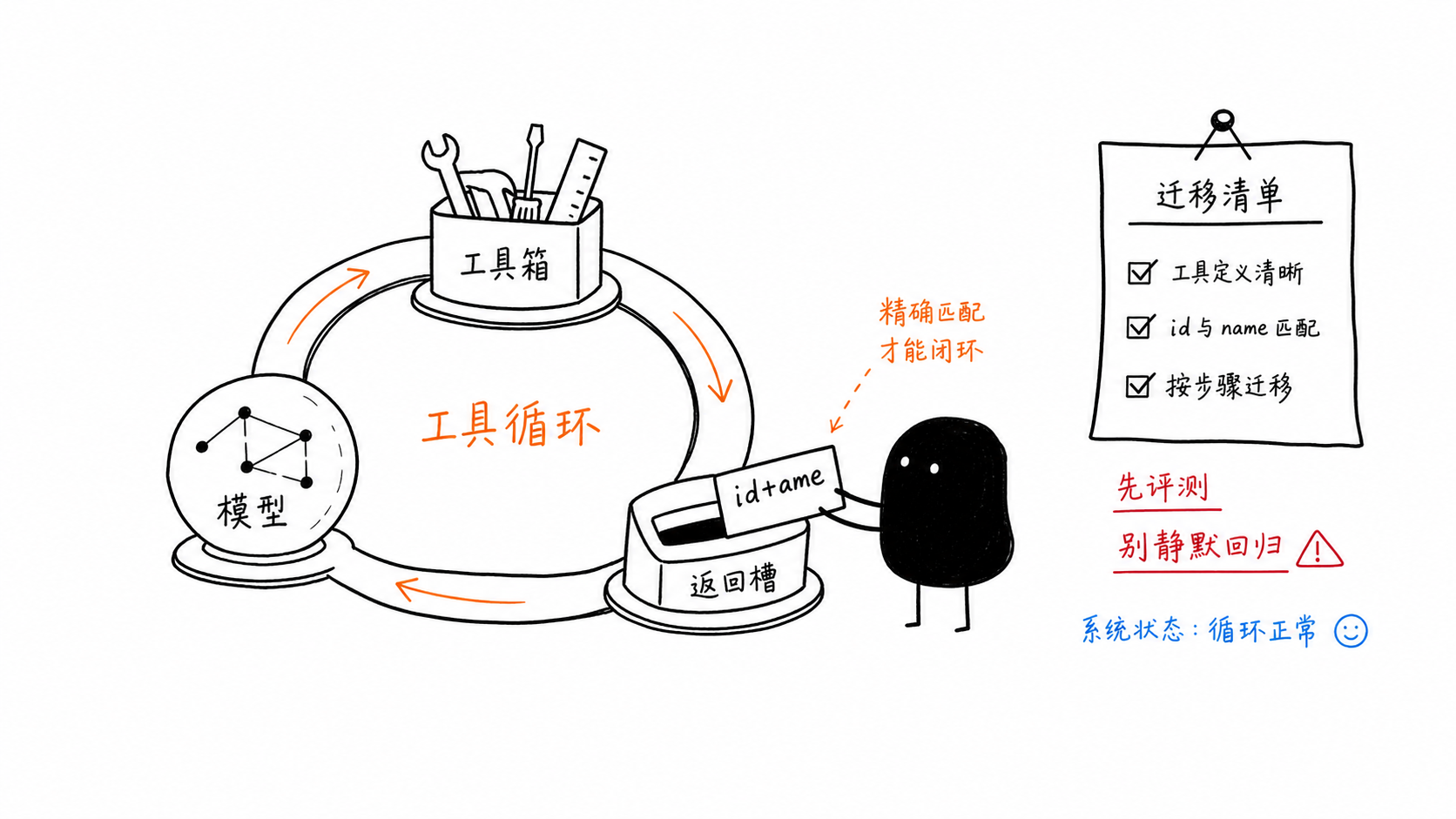
Un agent MCP fonctionnel sur Gemini 3.5 Flash
L’article source inclut un schéma de bout en bout très utile : un outil de lecture de fichier, un outil de récupération d’URL, une structure standard de déclaration de fonction et une boucle qui renvoie les réponses des outils au modèle.
Définitions des outils
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Modèle de boucle d’agent
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
history.append(types.Content(role="tool", parts=tool_results))La règle de migration, petite mais cruciale, est que votre réponse de fonction doit correspondre à la fois à id et à name de l’appel d’origine.
Quand préférer Antigravity à la place
Construire manuellement des boucles d’outils convient pour des prototypes. En production, on finit vite par reconstruire soi-même l’orchestration, le cache, le routage, les tentatives de reprise et l’observabilité.
C’est pourquoi la question la plus importante n’est pas seulement « puis-je intégrer ce modèle », mais « quelle quantité d’infrastructure agentique suis-je sur le point de devoir gérer moi-même ? »
Checklist rapide de migration
Si vous passez de gemini-3-flash-preview à gemini-3.5-flash, vérifiez explicitement ces points :
remplacez soigneusement l’identifiant du modèle
définissez
thinking_levelde manière intentionnellesupprimez les surcharges d’échantillonnage obsolètes, sauf si des évaluations les justifient
faire correspondre id et name dans les réponses des outils
inspectez
response.usage_metadata.thoughts_token_countconservez la preview pour les API non prises en charge dont vous dépendez encore
exécutez des évaluations avant/après
comparez la tarification de Copilot aux coûts directs de l’API
Essayez Gemini 3.5 Flash avec vos outils
Si votre objectif n’est pas seulement de tester des prompts, mais de connecter ensemble des fichiers, des dépôts, des API, de la documentation et des workflows agentiques, vous avez généralement besoin de plus qu’un simple endpoint de modèle.
Chez We0 AI, ce même principe va encore un cran plus loin : le workflow agentique ne représente que la moitié du travail. Le reste consiste à rendre le produit compréhensible, trouvable, recommandable et convertissable grâce à la documentation, aux FAQ, aux pages produit, au contenu de démonstration et aux surfaces SEO / GEO.
FAQ
Comment appeler Gemini 3.5 Flash depuis Python ?
L’appel lui-même est court. Ce qui compte, c’est de définir explicitement thinking_level afin que la migration ne dégrade pas silencieusement la qualité des résultats.
Quelles sont les valeurs de thinking_level ?
minimalpour les tâches très légèreslowpour le code et les workflows agentiquesmediumcomme valeur par défaut de style grand publichighpour un raisonnement plus difficile et une planification plus approfondie
Pourquoi Gemini 3.5 Flash coûte-t-il plus cher dans GitHub Copilot ?
Parce que le multiplicateur de tarification change l’économie du modèle. Pour un usage agentique intensif, cela peut peser davantage dans le coût global que le prix de base du modèle.
Qu’est-ce que la préservation de la pensée ?
Il s’agit du fait que le modèle conserve son raisonnement interne d’un tour à l’autre. Cela améliore la cohérence sur plusieurs tours, mais augmente aussi la probabilité que les coûts en tokens augmentent avec le temps.
Gemini 3.5 Flash est-il adapté au MCP ?
Oui, en particulier lorsque les schémas d’outils, la correspondance des réponses, thinking_level et la gestion du budget de jetons sont traités avec soin.


