
最近のCodexのログ記録問題により、静かなローカルデータベースが、驚くほど大量にSSDへ書き込む存在になっていました。元のGitHub報告によると、CodexのSQLiteフィードバックログは、報告された使用パターンでは年間およそ640TBを書き込む可能性がありました。書き込み耐久性が約600TBWとされる一般消費者向けSSDにとって、この数字は単に少し厄介という程度ではなく、ドライブの保証書き込み耐久性に近いものです。
奇妙なのは、そのログデータベースが見た目には巨大ではなかったことです。ファイルは約1ギガバイト程度に収まっている一方で、実際の過去の書き込みはバックグラウンドで積み重なり続けていました。だからこそ、このバグは大きな注目を集めました。ディスクを明らかな形で埋め尽くすわけではないのに、それでも書き込みサイクルを消耗させる可能性があったためです。

出典注記:この記事は、BAAI Hubによる新智元レポートの転載を基にし、公開されているGitHub IssueおよびHacker Newsでの議論と照合して作成しています。元ページに含まれていたブランドロゴ、QRコード、フォロー促進表示、関連性のない装飾画像は含めていません。
640TBのSSD書き込みはどのように起こり得るのか
この数字は最初は誇張のように聞こえるため、まず測定結果から見ると分かりやすいです。
GitHub Issueで報告者は、約21日間の稼働時間の後、メインSSDに約37TBが書き込まれていたと述べています。これを1年分に換算すると、およそ640TBになります。主な原因として疑われたのは、CodexのローカルSQLiteフィードバックログデータベースでした。
Codexはローカル設定ディレクトリ配下のファイルに書き込んでいました。
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shmその挙動は、単に「ログファイルが永遠に増え続ける」というものではありませんでした。むしろ、挿入と削除のループのように見えました。Codex は新しい行を挿入し、その後、保持する行数を安定させるために古い行を削除していました。見かけ上のファイルサイズは比較的落ち着いていましたが、それでもドライブは繰り返される書き込みを処理しなければなりませんでした。
レポートの15秒間のサンプルは、この問題をはっきりと示していました。
指標 | 前 | 後 |
保持された行数 | 681,774 | 681,774 |
最大行ID | 5,003,347,015 | 5,003,383,226 |
つまり、保持されている行数はまったく増えていなかったにもかかわらず、15秒間で約36,211行が挿入されたことになります。データベースは外部から見ると安定しているように見えましたが、その下では書き込みの churn が続いていました。
頻繁なログエントリも、すべてが価値の高いアプリケーションイベントだったわけではありません。例には、inotify イベントのような、ファイルシステムや依存関係レベルのノイズが繰り返し含まれていました。
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")その結果、何か異常が起きていることをユーザーにほとんど見せないまま、ストレージを書き換え続ける可能性のあるローカルログシステムになっていました。
1GBのファイルでも数百テラバイトの書き込みを発生させる可能性があります
このインシデントで最も直感に反する点は単純です。SSDの摩耗は現在のファイルサイズではなく、総書き込み量によって決まります。
ローカルデータベースは約1GBのままでありながら、アプリケーションがその一部を繰り返し書き込み、剪定し、インデックス化し、チェックポイントを作成し、書き換えることがあります。ストレージの健全性という観点で重要なのは、今日そのファイルがどれほど大きく見えるかだけではありません。時間の経過とともにどれだけのデータが書き込まれたかが重要です。
レポートには、このギャップをより分かりやすく示すスナップショットが1つ含まれていました。
指標 | 値 |
現在の | 1.2 GiB |
現在保持されている行数 | 506,149 |
割り当て済み行 ID の総数 | 5,543,677,486 |
現在のデータベースに保持されていたのは約 50 万行にすぎない一方で、自動増分された行 ID はすでに 55 億 を超えていました。これが書き込み増幅の話の核心です。古い行は現在のデータベース表示から消えることがありますが、それらを作成するためのディスク書き込みはすでに発生しています。
SQLite の WAL、つまり Write-Ahead Logging もここでは重要です。WAL モードでは、変更はメインデータベースにチェックポイントされて戻される前に、別の -wal ファイルへ追記されます。WAL は SQLite の通常かつ有用な仕組みですが、アプリケーションが非常に頻繁に挿入と削除を行う場合、裏側で発生するディスク活動の量を増大させる可能性があります。
わかりやすく言えば、ノート自体はまだ薄く見えるものの、同じページに何度も書かれ、消され、また書き直されてきたということです。
根本原因:ユーザーの期待どおりに動作しなかった RUST_LOG 設定
報告では、Codex のログ出力経路における特に重要な設定の詳細が指摘されていました。
Targets::new().with_default(Level::TRACE)Rust の tracing エコシステムでは、ログのフィルタリングは多くの場合、ターゲットとレベルによって制御されます。ユーザーは、RUST_LOG 環境変数によってログの冗長性を info、warn、またはそれ以下のようなレベルまで減らせると考えるのが自然です。
しかしこの経路では、SQLite のフィードバックログシンクがデフォルトで TRACE を使用していました。TRACE は最も詳細なレベルであり、低レベルの依存関係の詳細、生のプロトコル動作、その他のデバッグノイズを記録する可能性があります。この問題報告では、このデフォルト設定により、ローカルの永続ログデータベースが本来必要な範囲を大きく超えて保存し続けていたと主張していました。
保持されていたログの分布は、TRACE レベルの内容がいかに支配的であったかを示していました。
レベル | 推定 MiB | バイト比率 |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
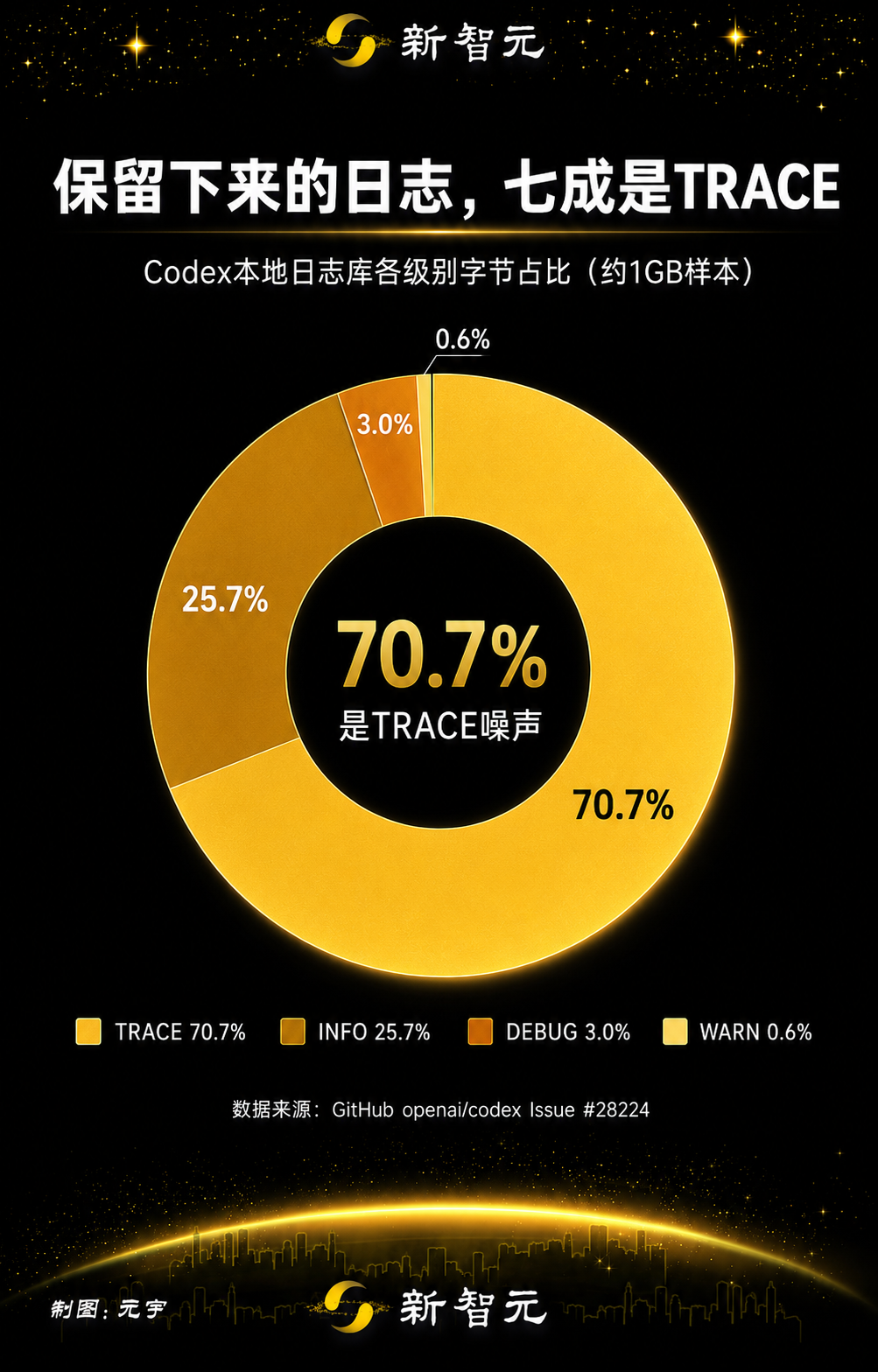
レポートではまた、OpenTelemetry 関連のミラーリングされた 2 つのログソースである codex_otel.log_only と codex_otel.trace_safe が、保持されたログバイトのかなりの部分を占めていたことも指摘されています。そのサンプルでは、報告者は、こうしたノイズの多いカテゴリをフィルタリングすれば、フィードバックログを完全に無効化しなくても、保持されるログ量の大半を削減できると推定していました。
だからこそ、このバグは開発者にとって非常に苛立たしいものに感じられました。単に「ログ設定を忘れていた」という話ではありませんでした。むしろ「ログを減らそうとしたのに、この経路では結局、詳細なログが永続化され続けていた」という状況に見えたのです。
これは関連する最初の問題ではなかった
レポートでは、これを単独の孤立した事故として扱っていませんでした。SQLite ログ、WAL の増大、大量のディスクアクティビティ、そして上限のない、あるいは過剰なローカルログに関する Codex の関連問題が複数挙げられていました。
レポートで言及されていた例には、次のようなものが含まれていました。
Issue | 報告されたテーマ |
|
|
| 通常使用時のデスクトップ版 |
| WAL ファイルが割り当てられたまま残る、または予期せず増大する |
| 十分な保持期間やローテーションがないことによるフィードバックログ SQLite の増大 |
| 小規模な SQLite データベースでの書き込み増幅 |
| アイドル状態の Codex プロセスによる大量の I/O |
| Windows / WSL2 でディスクのアクティブ時間が 100% |
AI コーディングツールは、常時稼働する開発パートナーのように扱われることが増えています。ファイルを読み取り、リポジトリを監視し、セッションを維持し、テレメトリを収集し、コンテキストを保持します。つまり、ローカルディスク、メモリ、CPU の予算は、トークン予算やモデル品質と同じくらい重要になります。
修正はマージされたが、議論は終わらなかった
GitHub の Issue には後に更新が追加され、3つのプルリクエストがマージされ、報告者自身の Codex フィードバックではログが推定で85% 削減されたことが示されたと記されています。
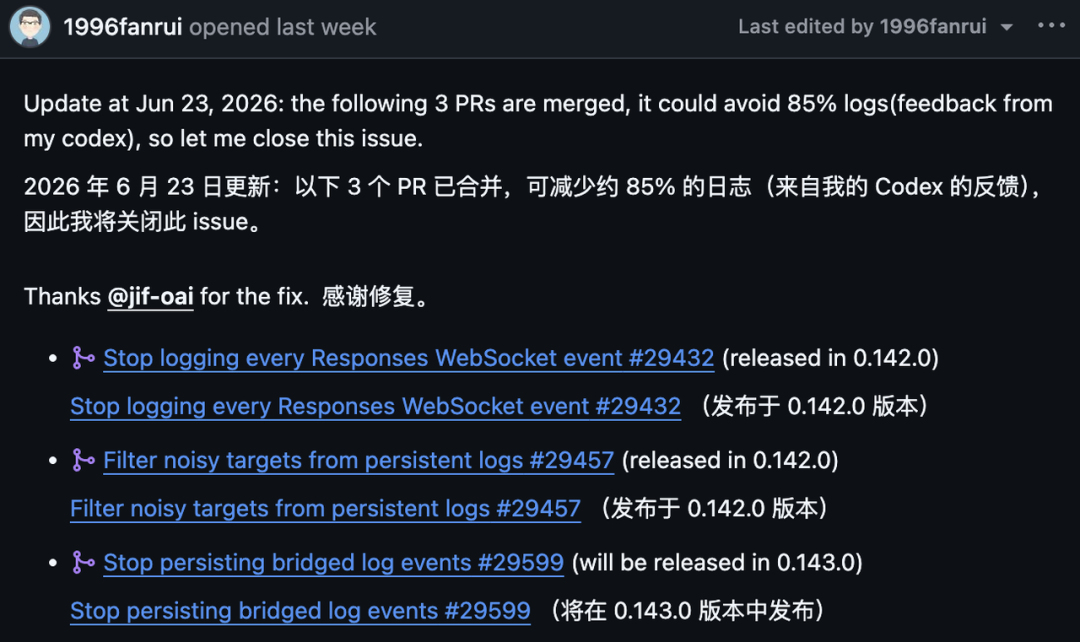
この Issue では、3つの修正が次のように列挙されていました。
プルリクエスト | 目的 | Issue のリリースノート |
| すべての Responses WebSocket イベントのログ記録を停止 |
|
| 永続ログからノイズの多いターゲットを除外 |
|
| ブリッジされたログイベントの永続化を停止 |
|
85%の削減は大きなものですが、それはローカルログに長期的な書き込み量の厳格な上限が設けられたことを証明するものではありません。この違いがあるため、議論は続きました。開発者たちは、この特定のバグが軽減されたかどうかだけでなく、AIコーディングエージェントの永続的なローカルテレメトリに、より明確な制限を設けるべきかどうかも問うていたのです。
GitHubのIssueには、コメント投稿者が共有した簡単な回避策も含まれていました。これはSQLiteトリガーを作成することで、logsテーブルへの挿入をブロックするものです。
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"このような回避策は慎重に使用してください。ローカルログへの書き込みを減らせる可能性はありますが、サポートチームや開発者が後で必要とする可能性のある診断データを削除してしまうこともあります。一般的には、トレードオフを理解しないままアプリケーションのデータベースを黙って変更するよりも、修正版に更新し、現在のログ動作を確認する方が安全です。
コーディングツール戦争はSSD以上のものを消耗している
議論はすぐにCodexだけにとどまらなくなりました。Hacker Newsでは、開発者たちがAIコーディングツールに関するより広範な不満も提起しました。高いGPU使用率、大きなメモリ消費、バックグラウンド活動、そして巨大なローカルデバッグログです。

その反応はもっともです。現代のAIコーディングアシスタントは、もはや単純なコマンドラインユーティリティではありません。その多くはローカルエージェントに近い振る舞いをします。プロジェクトを監視し、リモートモデルと通信し、コンテキストを管理し、コマンドを実行し、タスクをまたいで状態を保持します。その力は有用ですが、同時にエンジニアリング上の新たな責任のカテゴリも生み出します。
ツールはユーザーインターフェース上では「問題ない」ように見えても、バックグラウンドで静かにリソースを消費している場合があります。高速なCPU、大容量メモリ、最新のNVMeドライブは、長い間問題を隠してしまうことがあります。アプリはフリーズしないかもしれません。ディスク容量もいっぱいにならないかもしれません。ターミナルも引き続き応答するかもしれません。しかし、ハードウェアの健全性カウンターは別の状況を示していることがあります。
だからこそ、この事例はAI開発者向けツールにとって有用なケーススタディとなりました。モデルの能力は重要ですが、ローカルでの運用品質も同じく重要です。開発者のマシン上で動作するコーディングエージェントには、適切なデフォルト設定、保持期間の制限、ログローテーション、そしてユーザーがそれが何をしているのか理解できる手段が必要です。
FAQ
CodexのSQLiteログバグとは何でしたか?
これは、ローカルのSQLiteフィードバックログが非常に大量のディスク書き込みを発生させる可能性があると報告されたCodexのログ記録に関する問題でした。GitHubの報告では、報告者が測定した使用パターンにおいて、年間約640TBの書き込みが発生すると推定されていました。
小さなlogs_2.sqliteファイルでも、なぜSSDを消耗させる可能性があるのですか?
SSDの耐久性は、現在のファイルサイズだけでなく、時間の経過とともに書き込まれた総データ量に依存します。データベースは、ディスク上では小さく見えたままでも、挿入、削除、WALへの書き込み、チェックポイント処理、インデックス更新を繰り返すことがあります。
この文脈でSQLite WALとは何を意味しますか?
WAL は Write-Ahead Logging の略です。SQLite はまず変更を別の -wal ファイルに書き込み、その後チェックポイント処理によってメインデータベースへ反映します。これは通常の動作ですが、挿入や削除が非常に頻繁に発生すると、多くのアクティビティが生じる可能性があります。
TRACE ログはどのような役割を果たしましたか?
TRACE は最も詳細なログレベルです。報告されたサンプルでは、TRACE レベルの内容が保持されたログバイト数の約 70.7% を占めており、この問題では、詳細な依存関係ログやプロトコルログがデフォルトで永続化されていると指摘されていました。
OpenAI は Codex のログ問題を修正しましたか?
GitHub の issue 更新では、3 件の PR がマージされたとされ、報告者は自身の Codex 使用状況からのフィードバックに基づき、ログの約 85% を回避できる可能性があると見積もっていました。2 件の修正は 0.142.0 でリリース済みと記載され、3 件目は 0.143.0 向けに予定されていると記載されていました。
ユーザーは Codex のログを手動で削除またはブロックすべきですか?
手動での変更は、診断情報を削除してしまう可能性があり、副作用を伴う場合もあるため、慎重に扱うべきです。懸念がある場合は、まず Codex を更新し、ログファイルを確認し、SSD の書き込みカウンターを監視するのがより安全な第一歩です。
これは Codex だけの問題ですか?
この特定の報告は Codex に焦点を当てたものでした。しかし、より広い懸念はローカル AI エージェント全般に当てはまります。常時稼働するツールには、ディスク、CPU、メモリ、テレメトリ、保持されるログについて明確なリソース予算が必要です。
関連ツール
OpenAI Codex GitHub リポジトリ: Codex CLI および関連するソースコードの公開リポジトリ。
SQLite: 多くのローカルアプリケーションやツールで使用されている組み込みデータベースエンジン。
SQLite Write-Ahead Logging ドキュメント: WAL の仕組みとチェックポイント処理が重要な理由を説明する公式ドキュメント。
Rust tracing: Codex の Issue で取り上げられた、Rust の構造化ログおよび診断フレームワーク。
smartmontools: 対応ドライブの SSD 書き込みカウンターを含む、SMART ストレージ健全性データを確認するためのツールセット。
Hacker News: Codex のログ記録に関する報告が、より広範な開発者の注目を集めた議論プラットフォーム。
関連リンク
Codex SQLite フィードバックログの問題 #28224: 報告された年間 640TB の書き込み見積もりとその根拠を記録した主要な GitHub Issue。
Responses WebSocket イベントをすべてログに記録するのを停止 #29432: ログ削減作業の一環として挙げられた、マージ済み PR の一つ。
永続ログからノイズの多いターゲットをフィルタリング #29457: ノイズの多い永続ログ対象のフィルタリングに焦点を当てた PR。
ブリッジされたログイベントの永続化を停止 #29599: ブリッジされた依存関係のログイベントが永続化されるのを停止することを目的としたフォローアップ PR。
Hacker News の議論: Codex のログ記録、SSD 書き込み、AI コーディングツールの品質をめぐるコミュニティでの議論。
OpenAI Codex CLI README: Codex CLI のインストールと実行に関する公式リポジトリの README。
SQLite WAL ドキュメント: WAL ファイル、チェックポイント、パフォーマンス上の考慮事項に関する公式説明。


