
はじめに
AnthropicがClaude Fable 5を復帰させたばかりのタイミングで、また別のジェイルブレイク検証が公の場に現れた。
このタイミングにより、この話題は特にセンシティブなものとなった。Fable 5はすでに一度の論争、一時的なアクセス停止、そしてより強力なサイバーセキュリティ保護を備えた再展開を経験していた。その復帰直後、セキュリティ研究者のVitto Rivabellaは、防御を再び突破できたと述べた。
興味深いのは、この2度目のケースが単純な「モデルが壊れている」という話ではない点だ。実際にはそれよりも複雑である。試行には約20時間かかったとされ、ほとんどの試みは失敗し、最終的に得られた結果も限定的だったため、研究者自身が同種の情報を得るなら通常のウェブ検索のほうが速く安いと述べている。
本記事では、元の時系列に沿って、Fable 5の復帰、最初のジェイルブレイク、Anthropicの公開Cyber Jailbreak開示プログラム、2度目のジェイルブレイク検証、そしてその背後にあるより深い問い——いかなるフロンティアAIモデルも完全に封じ込めることができるのか——を追う。
出典について
本リライト記事は、智源社区 / 新智元による中国語の元記事に基づいている:https://hub.baai.ac.cn/view/56072。元記事では、X上の公開投稿、およびFable 5、その再展開、ジェイルブレイク枠組みに関するAnthropicの公式発表が引用されている。
元ページには複数の画像が含まれている。本版では、公開投稿、公式プログラムのスクリーンショット、堅牢性チャートなど、記事の主張に直接関係するスクリーンショットを残している。装飾的なブランド画像、プロモーション画像、過度に詳細な危険出力のサムネイルを含むと思われるスクリーンショットは省略した。
元記事には次の著作権に関する注記も含まれている。本文中の画像に著作権上の問題がある場合、権利者は削除のため発行者に連絡してほしい、というものだ。
Fable 5は復帰した——ただし条件付きで
Anthropicは、Fable 5が7月7日以降、一時的にサブスクリプションプランから外れることを確認したが、同社は同時に、容量が許すようになればFableを標準的なサブスクリプション機能として復活させる計画だとも述べた。
多くのユーザーにとって、それは朗報に聞こえた。Fable 5が永久に削除されるわけではない。利用制限と容量上の制約付きではあるが、戻ってくるということだった。

しかし、その安堵は長く続かなかった。
再展開の直後、Fable 5は再びジェイルブレイクされたと報じられた。これは、その防御が公に挑戦された2度目のケースだった。Vitto Rivabellaは突破に成功したと発表したが、最終的な結論は見出しが示すほど単純ではなかった。
Anthropicはすでに、Fable 5が以前制限された理由を説明していた。同社によれば、以前の問題は、Amazonの研究者がサイバーセキュリティの文脈でFable 5の保護策を迂回する方法を発見したという報告に関係していた。

この以前の出来事を受け、Anthropicは、再展開されたFable 5には、以前報告された挙動を標的とする強化された安全分類器が含まれていると述べた。
それでも、その「神話」は短期間しか持たなかった。
72時間:Fable 5の神話に入った最初の亀裂
Fable 5の最初の公的イメージは、極端な安全性テストを中心に築かれていた。
Anthropicが6月9日にモデルをリリースした際、同社は厳しい外部ストレステストを経たことを強調した。メッセージは明確だった。これは、はるかに高性能なモデルファミリーの中で、一般利用向けに高度に保護されたバージョンとして設計されたものだ、ということだ。
その後、最初の公開ジェイルブレイクが起きた。
著名なジェイルブレイク関係者であるPliny the Liberatorは、わずか数日でFable 5を本来意図された安全境界の外へ押し出せることを実演したとされている。元記事では、禁止された化学やソフトウェア悪用に関する内容を含む例が説明されているが、本リライト版では、実行可能な詳細を意図的に再現しない。
重要なのは具体的な内容ではない。重要なのは攻撃パターンである。
最初のジェイルブレイクの仕組み
最初のケースは、AIレッドチーム界隈で何年も議論されてきた2つの大まかな考え方に依拠していた。
- 文字と言語の混乱
一部のプロンプトでは、見た目が似た文字、特殊なUnicode形式、または非標準的なテキストパターンが使われていた。人間には意味が明らかに見える場合でも、分類器にとっては入力を安定して解釈するのが難しくなる可能性がある。 - 長い文脈による意図の希釈
有害な要求をモデルの目の前に直接置くのではなく、その意図を長く一見無害な会話全体に分散させることができる。その場合、分類器は単純な一文を評価するのではなく、多数のやり取りにわたって意味を追跡しなければならない。
これらの考え方は新しいものではない。重要なのは、それらが新しいモデルに対して再び機能したように見えたことだ。
Fable 5 の事例を注目すべきものにしたのは、Anthropic がこのモデルを異例なほど強固化されたものとして位置づけていたことだった。
Anthropic、公開のサイバー脱獄プログラムを開始
7月1日、Anthropic は Fable 5 の復帰を発表した。ほぼ同じ時期に、同社は Cyber Jailbreak という公開 HackerOne プログラムも開始した。
このプログラムは、Fable 5 が有害なサイバー用途を支援できるようにしてしまう可能性のある脱獄を、研究者や一般の人々が報告することを募っている。
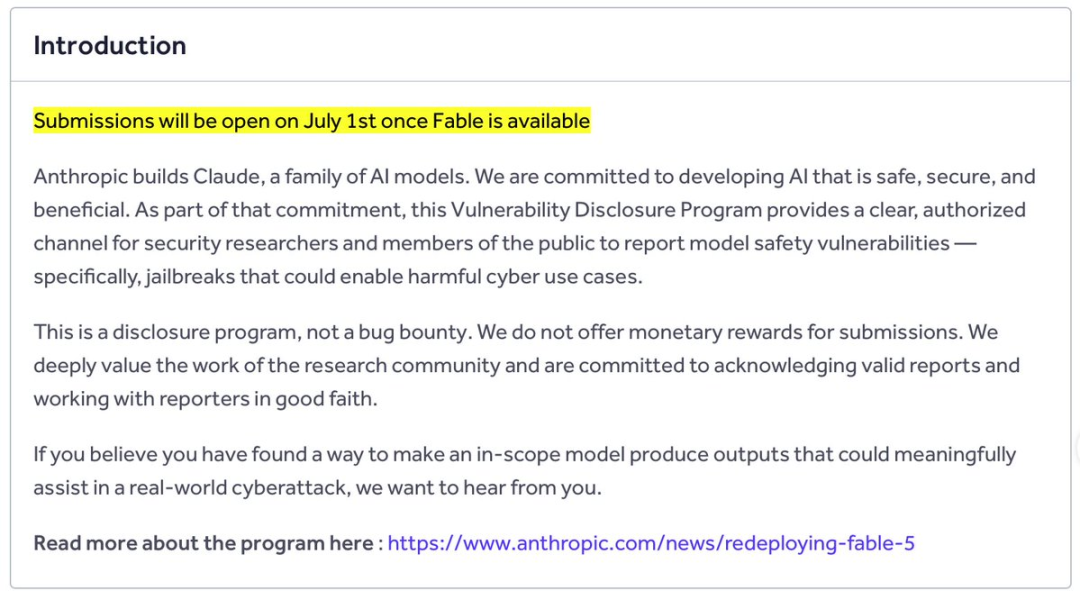
これは脆弱性開示プログラムであり、有償の報奨金プログラムではない。つまり、研究者は発見内容を提出できるが、このプログラムは金銭的報酬を提供しない。
この設計は興味深い。Anthropic は熟練した研究者から継続的な外部の敵対的テストを受けられる一方で、提出者にとっての主な報酬は認知と責任ある開示となる。
一部の観察者は、これを賢く低コストなレッドチーム戦略と見なした。一方で、弱点を指摘する声もあった。注目度の高い脱獄を発見する人々は、それを非公開の受信箱に静かに送ることを望まない場合が多い、という点だ。
公的なペルソナを持つ脱獄研究者にとって、可視性はイベントの一部である。脱獄が発見されれば、その結果を公開すること自体が目的の一部になり得る。
Fable 5 は再び脱獄された
報道によれば、Fable 5 は再び回避された。しかし、2回目の脱獄レビューのトーンは、最初のものとは大きく異なっていた。
今回の背後にいた研究者は Vitto Rivabella だった。約20時間のテストを経た彼の結論は、Fable 5 が弱いというものではなかった。実際、彼は Anthropic をある程度評価していた。

彼のレビューによれば、ほとんどの試みは失敗した。彼は Fable 5 を極めてよく保護されていると表現し、このモデルは単一の単純なフィルターではなく、多層的な防御を使用しているように見えると述べた。
異なる種類の事後分析
2回目の脱獄の話は、最初に聞こえるほど劇的なものではない。
Vitto の投稿は、Fable 5 の防御が実際に機能していたことを示唆していた。彼の見方では、このモデルには少なくとも3層の保護があるように見えた。
- リクエストにモデルが本格的に関与する前の 入力側の安全性チェック。
- 出力が形成されている最中に安全でない挙動を停止できる 生成時の中断メカニズム。
- モデルが自身の推論プロセスの一部として安全でない意図を認識しているように見える 内在化された安全性推論。
彼はまた、このシステムは単にキーワードをブロックしているわけではないとも述べた。言語をまたいで意図と意味を検出しているように見えたという。
これは重要である。キーワードフィルターは比較的だましやすいからだ。意図ベースの防御は、特に複数のチェックポイントと組み合わされると、回避がより難しくなる。
90% のブロック率が重要な理由
元の記事では、Fable 5 がテストされたリクエストのおよそ90%をブロックしたように見えたと記している。正確な数値は正式なベンチマークではなく研究者の観察に基づくものだが、独立したテストの全体的な傾向とは一致している。
イタリア人工知能研究所の AI Security Lab も Fable 5 と Opus 4.8 を調査した。その報告書では、最も強力な適応型攻撃が Fable 5 に対して 6.1%、Opus 4.8 に対して 11.5% の確認済み成功率を達成した。

これは、そのモデルが無敵であることを意味しない。残された弱点に到達するのがより難しくなっている、ということだ。
数分で紹介サイトを作り、リード獲得を伸ばす
アイデアを一文で入力するだけで、We0 AI が紹介サイト、ページ、CMS を生成し、公開後の顧客獲得と流入拡大を支援します。
静的なトリックは効果が薄れつつある。残された攻撃面は、適応的で反復的な試みに有利であるように見える。つまり、人間または自動化されたレッドチームシステムが、狭い突破口が現れるまで試行し、調整し、探り続けるようなタイプの攻撃である。
最終的に機能した組み合わせ
Vitto の成功した試みは、ひとつの巧妙なフレーズに基づくものではなかった。
元の記事では、それを古いレッドチームのアイデアを複雑に組み合わせたものとして説明している。テキストの難読化、学術的な枠組みづけ、長い助走、タスクの分解と再結合、さらにある程度のランダム性である。
これらの概念はいずれも新しいものではない。難しいのは、これらが存在することを知っていることではない。
カテゴリは存在する。難しいのは、不審な意図を検知するとリアルタイムで反応し、やり取りをリセットするシステムに対して、それらを何度も試し続けることだ。
言い換えれば、これはきれいな一発成功のジェイルブレイクではなかった。むしろ、長く疲れる試行錯誤のプロセスに近かった。
低リソース言語は依然として弱点
レビューの一部は誤解されやすい。
報道によると、Vittoは、あまり知られていない言語や低リソース言語が、より一貫した弱点であり続けていると指摘したという。元の記事では、サンタル語やアムハラ語などが例として挙げられている。
![画像は、Claude Fable 5がジェイルブレイクされた後に生成したテキスト内容を示している。上部には「HUMAN RESPONSE
- APPROXIMATE HUMAN-TYPED [HISTORICAL RECONSTRUCTION
- FOR EDUCATIONAL PURPOSES ONLY]」という文字がある。下部のテキスト内容は、1919〜1928年の「DISORDERS ENQUIRY COMMITTEE」に関する議論で、「SANTALI」や「AMHARIC」などの言語についての議論を含み、「NIMR
- 1」から「NIMR
- 6」までの6つの質問も列挙されている。内容は歴史的事件や人物などに関係している。この画像は、文書内でClaude Fable 5がジェイルブレイク後に生成したテキストについて説明している部分に関連しており、生成テキストの具体的な内容を示している。](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/0252dc52-aa7a-4498-849e-4355e3eebc38-08-5fa346f7-c790-4f3d-8f1a-1869bc22d5f0.png)
これは「Fable 5には特別なバックドアがある」という意味に読むべきではない。これは大規模言語モデル全般にまたがる、より広い問題である。
安全性トレーニングデータは通常、英語やその他の高リソース言語で最も充実している。低リソース言語は、カバー範囲が狭く、安全性に関する例も少なく、評価も弱いことが多い。その結果、言語によってガードレールにばらつきが生じる。
研究者たちは以前からこの問題について警鐘を鳴らしてきた。多言語におけるジェイルブレイク耐性はClaudeだけの問題ではなく、より広範なAI安全性の問題である。
ジェイルブレイクは実際に何を生み出したのか?
それだけの労力をかけた後でも、結果は「中核的な秘密」の劇的な流出ではなかった。
元の記事では、出力は低品質または限定的な有害断片の混合だったと説明されている。いくらかの誤情報、散発的な有害コンテンツ、侮辱的な言葉、部分的な化学関連情報、そして軽度の脆弱性関連資料などである。このバージョンでは詳細の再現は避けている。
重要なのは、その出力が安定しておらず、完全でもなく、長期的な有害タスクに特に役立つようにも見えなかったという点だ。
だからこそ、Vitto自身の要約には意味があった。彼は、現在の保護レベルでは、モデルをガードレールの向こう側へ押し出そうとして約20時間費やすよりも、ウェブ検索のほうがはるかに速く安価だと述べた。

彼はまた、安全システムを作動させることなく、長期的なタスクに対して完全なジェイルブレイクを安定して維持することには成功していないとも述べた。
これはAnthropic自身の公開上の位置づけとも一致している。再デプロイに関する投稿で、Anthropicはこれまでに知られているジェイルブレイクを軽微なものと説明した。それらは安全マージンに入り込む可能性はあるが、同社が最も強く阻止しようとしている、より深刻なカテゴリに必ずしも到達するわけではないという。

完璧な封印というパラドックス
2つのジェイルブレイク。2つの異なる教訓。
1つ目は、Anthropicを自信過剰に見せた。Fable 5は徹底的にテストされたものとして提示されていたが、ローンチ直後に公然と回避された。元の記事では、同社が極端な制限によってリスクを管理しようとしたものの、非常に目立つジェイルブレイクによって面目を失った事例として説明されている。
2つ目が明らかにしたのは別のことだった。傲慢さではなく、盲点である。
より強力な分類器、多層防御、公開されたレッドチーミング経路があっても、言語そのものは依然として捉えどころがない。意味は隠され、引き延ばされ、翻訳され、偽装され、あるいは文脈の中に分割されうる。安全システムは改善できるが、攻撃対象領域は動き続ける。
それがAI安全性にとって不都合な教訓である。
人間は、言語をまたいで翻訳し、膨大な文脈をまたいで推論できるモデルを作り上げた。しかし私たちは、隠れた人間の意図をすべて、明確な安全性判断へ完全に翻訳することはまだできない。
完全なAI封じ込めはパラドックスなのかもしれない。モデルの能力が高まるほど、安全な行動と危険な行動の境界はより微妙になっていく。
FAQ
Claude Fable 5とは何か?
Claude Fable 5はAnthropicの高度なClaudeモデルであり、制限の少ない対応モデルであるClaude Mythos 5よりも強力な安全対策を備えた、高性能な汎用モデルとして位置づけられている。AnthropicはFable 5について、危険なサイバー悪用を制限しながら、フロンティアレベルの能力をより広く利用可能にするために設計されたモデルだと説明している。
AIジェイルブレイクとは何か?
AIジェイルブレイクとは、モデルの安全ガードレールを回避しようとするプロンプト手法または対話パターンのことだ。ジェイルブレイクは、それがどのような挙動を解放するか、またどれほど広範に機能するかによって、軽微なもの、限定的なもの、深刻なものになりうる。
Fable 5は2回目のジェイルブレイクで完全に破られたのか?
元の記事で説明されている公開レビューに基づけば、答えはノーである。研究者は、ほとんどの試みが失敗し、プロセスには約20時間かかり、最終的な出力は限定的だったと述べている。これは、このモデルが
たとえ完璧ではなかったとしても、なお意味のある防御は備えていた。
Anthropic はなぜ HackerOne で Cyber Jailbreak プログラムを開始したのか?
Anthropic は、有害なサイバー利用を可能にし得るジェイルブレイクを研究者が報告するための明確な窓口を提供する目的で、Cyber Jailbreak プログラムを開始した。これは有償のバグバウンティではなく脆弱性開示プログラムであるため、金銭的報酬よりも責任ある報告に重点を置いている。
AI 安全性において低リソース言語が重要なのはなぜか?
低リソース言語は、多くの場合、学習データが少なく、安全性に関する事例も少なく、ベンチマークのカバレッジも弱い。そのため、言語間でガードレールの一貫性が低下する可能性があり、多言語での安全性テストが重要な研究分野となっている。
6.1% のジェイルブレイク成功率は、Fable 5 が安全ではないことを意味するのか?
それだけではない。確認された成功率が低くても、フロンティアモデルは非常に大規模に展開される可能性があり、執拗な攻撃者は反復的な試行を自動化できるため、重要な意味を持ち得る。同時に、この数値は AI4I の評価において、Fable 5 がテストされた攻撃の大半に耐えたことも示している。
どの AI モデルもジェイルブレイクから完全に保護できるのか?
Anthropic や多くの研究者は、完全な免疫を実現することは難しいと示唆している。実践的な目標は、ジェイルブレイクが決して存在し得ないことを証明することではなく、深刻度を下げ、リスクのある挙動を早期に検出し、重大な弱点が広く悪用される前に修正することである。
関連ツール
- Claude: Claude モデルをユーザーに提供する Anthropic の AI アシスタントプラットフォーム。
- Claude API: Claude モデルを使ってアプリケーションを構築するための Anthropic の開発者プラットフォーム。
- Anthropic: Claude、Fable 5、Mythos 5、および関連する AI 安全性研究を手がける企業。
- HackerOne: 研究者からセキュリティ報告を受け取るために組織が利用する脆弱性調整プラットフォーム。
- AI4I: AI システムに関する研究やレポートを公開しているイタリア人工知能研究所。
- CVSS: ソフトウェア脆弱性の深刻度を評価するために広く使われているフレームワークであり、AI ジェイルブレイクの深刻度フレームワークに関する広範な議論にも関連している。
関連リンク
- 智源社区の元記事: この Markdown 版の元になった中国語のソース記事。
- Fable 5 の再デプロイ: Fable 5 の再デプロイと更新された安全策に関する Anthropic の公式投稿。
- Fable 5 のサイバー安全策の詳細: Fable 5 の安全性分類器と提案されたジェイルブレイク深刻度フレームワークに関する Anthropic の説明。
- Claude Fable 5 と Claude Mythos 5: Fable 5 と Mythos 5 に関する Anthropic の発表投稿。
- Anthropic Cyber Jailbreak Program: サイバー関連のジェイルブレイクを報告するための HackerOne 上の開示ページ。
- AI4I のジェイルブレイクとフロンティアモデルに関するレポート: Fable 5 と Opus 4.8 に関するレッドチーム調査についての AI4I による概要。
- Anthropic Fable 5 および Opus 4.8 モデルのレッドチーム研究: AI4I のレッドチーム研究に関する arXiv ページ。
- 低リソース言語を用いた LLM の多言語ジェイルブレイク: 低リソース言語がジェイルブレイク耐性にどのような影響を与え得るかを論じた研究論文。
まとめ
2 度目の Fable 5 ジェイルブレイクは、完全な失敗という単純な話ではない。Anthropic の多層的な防御は、直接的な試みの大半を阻止しているように見える一方で、十分な時間、反復、創造性があれば、執拗なレッドチーム担当者はなお狭い抜け穴を見つけられることを示している。
より深い問題は、AI 安全性が単にキーワードをブロックするだけのものではないという点にある。言語、長いコンテキスト、曖昧なサイバーセキュリティ課題、敵対的なフレーミングをまたいで意図を解釈しなければならない。これは静的なフィルターを構築するよりもはるかに難しい。
Fable 5 の事例は、フロンティア AI 安全性の将来を示している。すなわち、より強力な分類器、公開された開示窓口、より優れた多言語評価、共有された深刻度フレームワークである。
教訓は明確だ。フロンティアモデルはジェイルブレイクをはるかに困難にすることはできるが、「完全に封じ込められた」AI は依然として未解決の問題である。


