
The clearest signal in this release
The most striking thing about Claude Opus 4.8 is not only that it arrived, but that it arrived very quickly.
Only 43 days passed between Opus 4.7 and Opus 4.8. For a frontier-model vendor like Anthropic, that is not a routine rhythm. The signal is pretty clear: the previous version may have tested well, but real-world feedback was not strong enough, so Anthropic needed to respond fast.

Article lead image for Claude Opus 4.8
This is not a theatrical upgrade, and that matters
Based on the source article, Anthropic is not positioning Opus 4.8 as a dramatic architectural leap. It looks much more like a reinforcement release shaped by real usage feedback.
The emphasis is very concentrated:
more reliable
more honest
more efficient
better for agentic workflows
Why Anthropic moved so quickly
The source article gives a practical explanation, and it comes down to two forces.
The first is that Opus 4.7 did not land cleanly in real usage. Even if official results looked solid, some developers were unhappy with overly verbose code comments, weak tool-calling stability, and decision-making that felt shaky in harder tasks.
The second is straightforward: competition is accelerating. OpenAI, Google, and others are pushing harder into AI coding and agentic products, which means Anthropic cannot afford to move slowly.
So in plain terms, Opus 4.8 feels like a release with both defensive urgency and offensive intent.

Backlash and market pressure around Opus 4.7
Yes, benchmark numbers improved, but that is not the most important part
The benchmark story is still there.
Terminal-Bench 2.1:74.2%, up 8.4% from Opus 4.7
SWE-Bench Pro:up 4.9% from the prior version
gains also appeared in Computer Use and financial analysis tasks
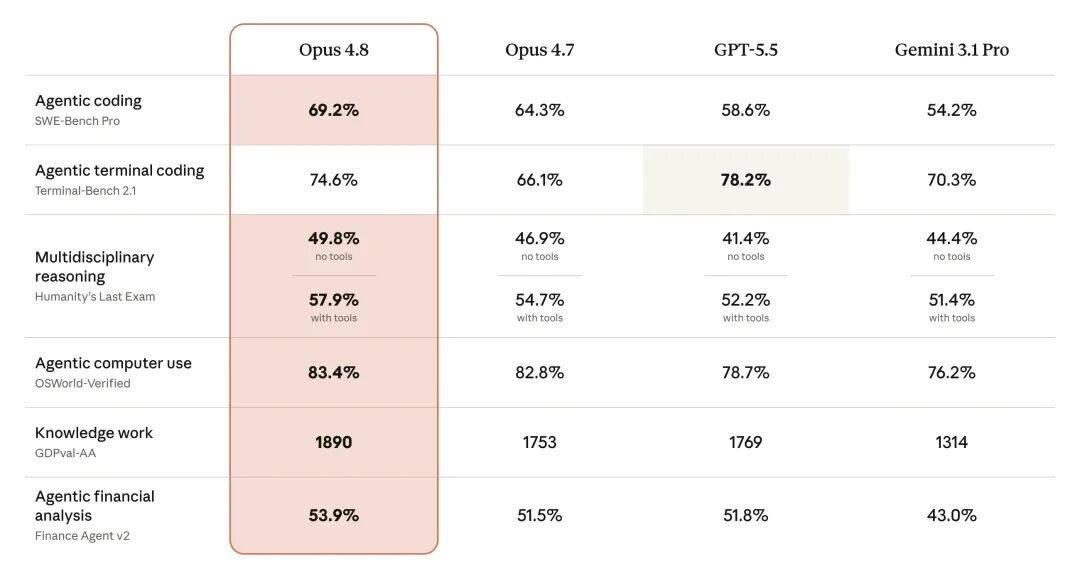
Benchmark image for Claude Opus 4.8
But if you only focus on those numbers, you miss the deeper shift. The more interesting change is not simply that the model became stronger. It is that it became less likely to bluff.
The biggest upgrade may be honesty
One of the most persistent large-model problems is simple: even when evidence is weak, the model often speaks as if it is certain.
That is especially dangerous in coding, debugging, and long tasks. If the model declares success too early, or presents unverified conclusions as fact, the repair cost lands on the human team later.
Anthropic appears to have targeted exactly that failure mode.
The source article highlights several important claims:
the model is more willing to state uncertainty
it marks risk more proactively when evidence is thin
the rate of missing code defects or failing to report vulnerabilities dropped to one quarter of the prior version
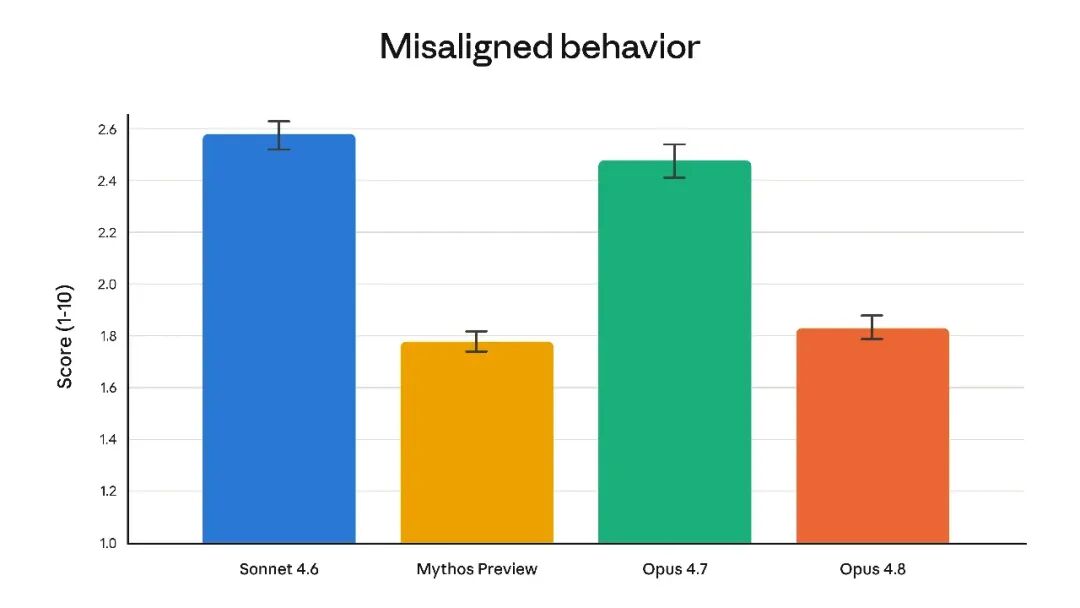
Image about honesty and defect reporting
For casual users that may just feel like “the model seems steadier.” For enterprises, it is much more important than that. A production-grade model does not only need to be smart. It needs to admit uncertainty when uncertainty is real.
Dynamic Workflows are the other half of the story
If Opus 4.8 improves the stability of the main model, Dynamic Workflows improve how complex work gets organized and executed.
The source article describes the feature in very simple terms: Claude is no longer just a single worker. It can act more like a project manager, splitting complicated jobs across many coordinated subagents in parallel.
The workflow includes:
planning execution steps
creating subagents
assigning different tasks
running work in parallel
validating results
merging the final output
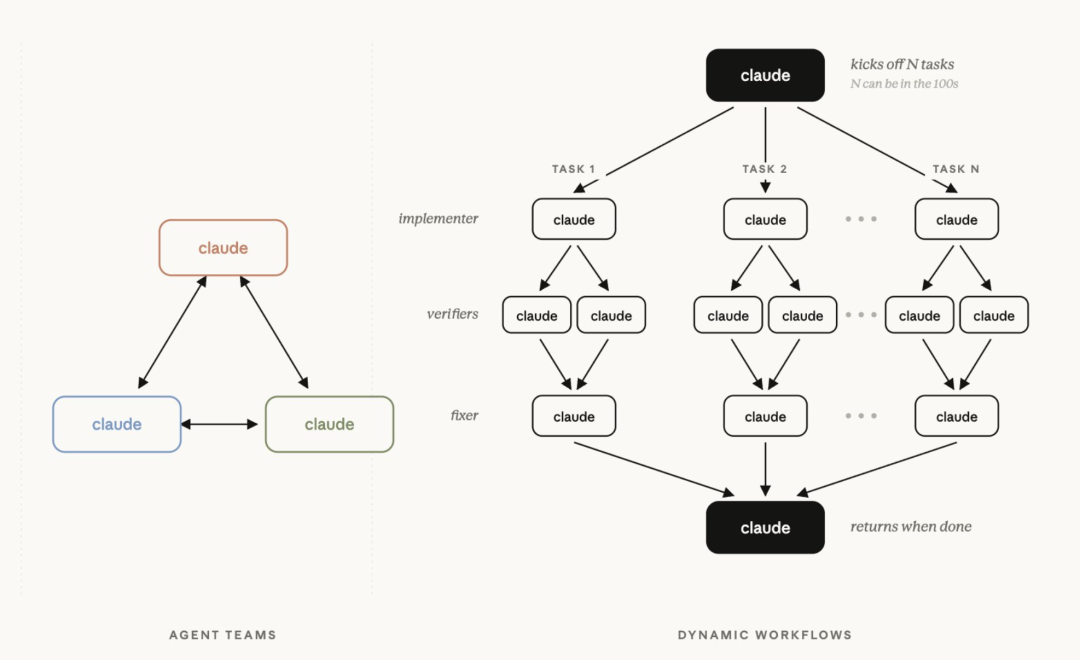
Dynamic Workflows overview image
The most eye-catching claim is that a single task can coordinate hundreds of parallel AI agents.
That changes the frame. Large codebase migration, long unattended runs, and broad engineering checks are no longer just about asking a smarter model for advice. They begin to look like multi-agent engineering execution systems.
Why this feature is getting so much attention
Because it pushes Claude Code into a different product category.
For a long time, AI coding discussions centered on whether a model could write code well. Dynamic Workflows force a bigger question: can the system break down work, allocate effort, validate output, and keep a complex engineering process moving?
The article points to a powerful example: in a migration involving hundreds of thousands of lines of code, Claude can handle requirement analysis, code edits, testing, and final merging with much less frequent human intervention.
If that direction holds, the competitive logic of AI coding changes. The next important question is not only who writes a function better. It is who moves entire engineering tasks forward more reliably.
Another understated change: effort controls
Anthropic also introduced new Effort Controls.
That is more important than it may look. It signals that Anthropic is explicitly acknowledging a real truth: not every task deserves the same reasoning budget.
At higher settings, Claude spends more time and more tokens to improve answer quality. At lower settings, it returns faster and costs less. For complex programming tasks and long-running workflows, that kind of controllability is going to matter a lot.
The API changes matter too
Anthropic also updated the Messages API.
The new interface supports inserting system instructions directly inside the message array, which makes it easier to modify permissions, resource quotas, and runtime behavior dynamically without breaking prompt caching.
That may sound like a detail, but for teams building more complex agent systems, it matters a lot. As workflows become longer and more structured, dynamic control over model behavior becomes more important.
Claude Mythos was also teased again
Another attention-grabbing part of the article is that Claude Mythos is already on the horizon.
For now it remains in limited preview with a small number of partners. Anthropic says stronger autonomous and cybersecurity capabilities require stronger safety protections before a wider release.
In other words, Opus 4.8 may not be the climax itself. It may be part of the setup for what comes next.
The fact that pricing did not change is not a side note
At a time when model quality is rising but cost sensitivity is rising too, unchanged pricing is information.
The source article lists:
standard mode:$5 per million input tokens, $25 per million output tokens
fast mode:$10 per million input tokens, $50 per million output tokens
That means Anthropic is not translating better capabilities directly into higher prices. Instead, it is trying to compete with more practical value at the same pricing level.
The most useful takeaway is not the leaderboard
The article quotes an interesting judgment from X user @JUMPERZ, and it gets to the real point.
The core idea is that debating “whether Opus 4.8 or GPT-5.5 is smarter” is becoming less useful. The better question is what kind of work you want the model to do.
Their rough split is:
Claude Opus 4.8 fits large codebase maintenance, long unattended agent tasks, self-correcting work, and Computer Use scenarios
GPT-5.5 / Codex fit terminal-heavy workflows, web research, high-throughput task processing, and speed-sensitive use cases
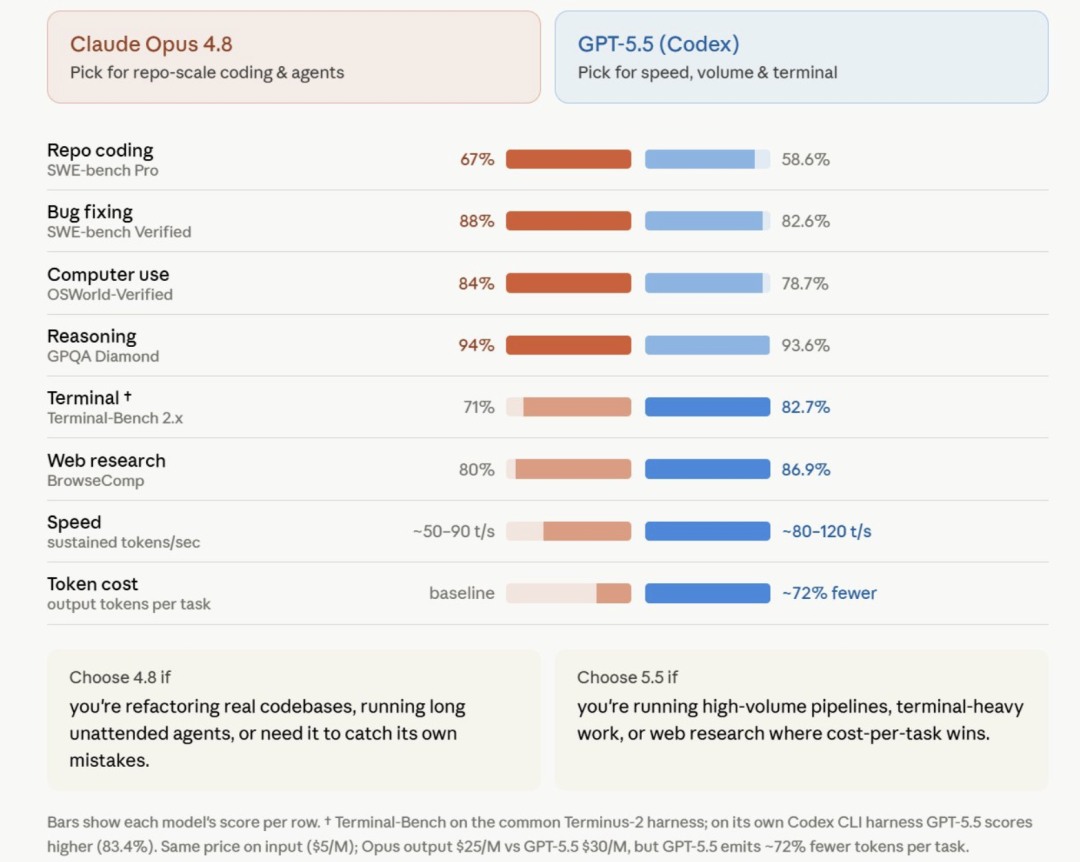
Workload-fit comparison image
That reflects a larger shift: model competition is slowly moving away from “who is smarter in the abstract” and toward who fits which engineering tasks better.
Final take
If I had to summarize this release in one sentence, it would be this:
Claude Opus 4.8 may not be the most dramatic model upgrade, but it may be one of Anthropic's most important steps toward something more usable, more trustworthy, and more system-like.
It is more honest, more suitable for long-running tasks, and more willing to expose uncertainty. Dynamic Workflows then push Claude Code much further into multi-agent engineering execution. Add the Mythos preview on top, and this is no longer just a version update. It looks more like Anthropic repositioning its whole product stack.
References
https://mp.weixin.qq.com/s/YoZBAxrK5WAMfxgmR_1WMw
https://www.anthropic.com/news/claude-opus-4-8


