
はじめに
「Loop Engineering」という言葉を耳にするようになったものの、どこから始めればよいのかまだ分からないという方に向けて、このガイドでは実践的な入り口を紹介します。
プロンプトを何度も書き、各ステップを手作業で確認する代わりに、ループを使うと AI エージェントが小さな目標に向かってスケジュールに沿って作業できます。システムはタスクを割り当て、現在の状態を読み取り、エージェントを実行し、結果を検証し、判断が必要なときには人間を再び介入させることができます。
元の記事では、Cobus Greyling によるオープンソースの Loop Engineering フレームワークが紹介されていました。記事公開時点で、このプロジェクトは GitHub で約 4.5k のスターを獲得していました。その後も成長を続けているため、現在リポジトリに表示されるスター数は異なる可能性があります。
要するに、重要なのはもはや「より良いプロンプトを書くこと」だけではありません。重要なのは、明確な境界を持ち、プロンプトを出し、確認し、反復できる信頼性の高いループを設計することです。

Loop Engineering とは何か?
Loop Engineering とは、繰り返し実行できる AI エージェントのワークフローを設計する方法です。ループは単なる 1 つのプロンプトではありません。エージェントを取り巻く小さなオペレーティングシステムのようなものであり、エージェントがいつ実行されるか、どのコンテキストを読むか、何を変更してよいか、結果をどのように確認するか、そして人間がいつ結果をレビューする必要があるかを定義します。
典型的なループは、次のようなタスクに使用できます。
- 日次のプロジェクトトリアージ
- プルリクエストの監視
- CI 失敗の整理
- 依存関係のスキャン
- Issue の分類
- マージ後の後片付け
- 変更履歴の下書き作成
これらは必ずしも難しいタスクではありませんが、反復的です。注意力、コンテキスト、そして一貫した基準が求められます。まさにそのような作業こそ、よく設計されたループが役立つ領域です。
なぜこのフレームワークが注目されているのか
元の記事で説明されているオープンソースフレームワークは、実用的なループパターン、スターターテンプレート、コマンドラインツールをまとめたものです。AI コーディングエージェント向けに設計されており、Claude Code、Codex、Grok、OpenCode などのツールを中心としたワークフローをサポートしています。
このフレームワークには、次のものが含まれています。
- すぐに使える 7 種類のループパターン
- よくあるシナリオ向けのスターターテンプレート
- ループのひな形を作成する
loop-init - トークンコストを見積もる
loop-cost - ループの準備状況を確認する
loop-audit - 長時間実行されるワークフロー向けの状態ファイルと予算ファイル
- より安全な人間によるレビューと段階的なロールアウトのサポート
中心となるメッセージはシンプルです。
プロンプトをやめよう。ループを設計しよう。
これは、プロンプトがなくなるという意味ではありません。プロンプトが、作業を繰り返し、状態を追跡し、結果を検証できる、より大きなシステムの一部になるという意味です。
すぐに始める:1つのコマンド
最も早く始める方法は、Git プロジェクト内で loop-init を実行することです。
注意:元記事を転載した一部のバージョンでは、コマンドラインフラグが長いダッシュで表示されている場合があります。実際のターミナルでは、以下に示す標準のダブルハイフン
--を使用してください。
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
このコマンドは、現在のプロジェクト内にループ構造のひな形を作成します。試したいワークフローに応じて、claude を grok、codex、opencode など他の対応ツールに置き換えることもできます。
daily-triage パターンは、高頻度の自動化よりもリスクが低いため、初心者にとってよい出発点です。自動変更を許可する前に、現在のプロジェクト状態をスキャンし、レポートを生成することに重点を置いています。
初心者向け Loop Engineering チュートリアル
Loop Engineering は最初は抽象的に聞こえるかもしれませんが、このフレームワークはそれをいくつかの具体的な構成要素に分解しています。
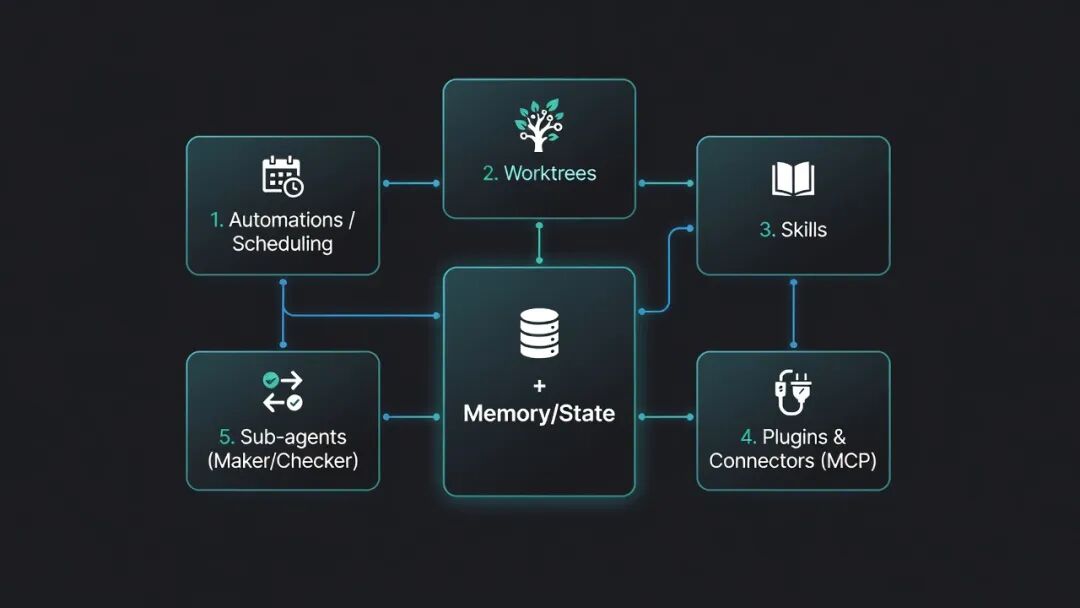
5つの構成要素とメモリ
基本的なレベルでは、ループは主に 5 つの部分と、メモリおよび状態から構成されます。
| 構成要素 | ループ内での役割 |
|---|---|
| 自動化/スケジューリング | 日次、時間ごと、数分ごとなど、一定の周期でループを実行します。 |
| ワークツリー | 複数のエージェントが互いに上書きしないよう、分離された作業環境を作成します。 |
| スキル | 再利用可能なプロジェクト知識、ルール、タスク指示を保存します。 |
| プラグインとコネクタ | MCP、GitHub、Linear、Slack などのシステムを通じて、ループを実際のツールに接続します。 |
| サブエージェント | 作成者の役割と確認者の役割を分離し、同じエージェントが自分の作業を承認しないようにします。 |
| メモリ/状態 | ループの外部に永続的なコンテキストを保持します。 |
チャット。通常は STATE.md などのファイルを通じて行われます。 |
この構造により、ループを理解しやすくなります。モデルに「すべてを適当に処理して」と頼むのではありません。定義済みの環境、スケジュール、状態ファイル、検証パス、そして人間への引き継ぎルールを与えるのです。
すぐに使える7つの本番向けパターン
このフレームワークには、本番利用を想定した7つのパターンも含まれています。各パターンは、実行頻度、リスクレベル、最適なユースケースが異なります。

| パターン | 典型的なユースケース | 推奨される開始モード |
|---|---|---|
| Daily Triage | プロジェクトの状態、Issue、CI、コミットをスキャンする。 | L1 report-only |
| PR Babysitter | レビュー、CI、リベース、マージまでプルリクエストを監視する。 | L1 watch |
| CI Sweeper | 失敗しているチェックを監視し、小さな修正を提案または適用する。 | L2 cautious |
| Dependency Sweeper | 古くなった依存関係やセキュリティ更新を確認する。 | L2 patch-only |
| Issue Triage | 新しく入ってくるIssueを重複排除し、スコア付けし、ラベル付けする。 | L1 propose-only |
| Post-Merge Cleanup | マージ後のTODO、軽微な技術的負債、フォローアップ作業を整理する。 | L1 off-peak |
| Changelog Drafter | コミットやマージ済み変更からリリースノートの下書きを作成する。 | L1 draft |
実践的なアドバイスとしては、低リスクのループから始めることです。Daily triageは、すぐにコードを変更する必要がないため、通常は信頼しやすいパターンです。
対話式パターンピッカー
このプロジェクトには、対話式ピッカーも用意されています。パターンを手動で選ぶ代わりに、「PRがなかなか進まない」「CIが失敗し続ける」「Issueのノイズが多すぎる」といった悩みから始められます。
ピッカーはその後、ループパターンを推奨し、開始用のコマンドを提示します。問題は分かっているものの、どのループに処理させるべきか分からない場合に便利です。
最初のループを実行する
リスクを抑えながら最初のループを実行する、初心者向けの方法を紹介します。
ステップ1: パターンを選ぶ
初めての場合は daily-triage から始めてください。これは低リスクのパターンであり、ループがプロジェクトの状態を読み取り、メモを書き、人間のために作業を準備する流れを理解するのに適しています。
ステップ2: ループをスキャフォールドする
Gitプロジェクトのルートディレクトリで初期化コマンドを実行します。
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
別のAIコーディングエージェントを使っている場合は、ツール名を置き換えることができます。
npx @cobusgreyling/loop-init . --pattern daily-triage --tool grok
npx @cobusgreyling/loop-init . --pattern daily-triage --tool codex
npx @cobusgreyling/loop-init . --pattern daily-triage --tool opencode
基本的な流れを理解したら、daily-triage を別の対応パターンに置き換えることもできます。
ステップ3: トークンコストを見積もる
高頻度のループは、特にサブエージェント、長いコンテキスト、反復的な検証を使用する場合、多くのトークンを消費する可能性があります。ループを頻繁に実行しすぎる前に、コストを見積もってください。
npx @cobusgreyling/loop-cost --pattern daily-triage --level L1
初期テストでは、ループをL1にとどめ、積極的すぎるスケジュールは避けてください。
ステップ4: ループの準備状況を監査する
ループを信頼する前に、監査を実行します。監査では、プロジェクトに0〜100の準備スコアを付け、改善案を提示します。
npx @cobusgreyling/loop-audit . --suggest
プロジェクトの準備が整っていない場合は、不足している要素を先に修正してください。よくある不足には、状態ファイルがない、検証ステップがない、スコープが不明確、予算上限がない、人間への引き継ぎルールが弱い、などがあります。
プロジェクトが十分な準備レベルに達した場合は、README用のLoop Readyバッジを生成することもできます。
npx @cobusgreyling/loop-audit . --badge
ステップ5: レポート専用モードで開始する
数分で紹介サイトを作り、リード獲得を伸ばす
アイデアを一文で入力するだけで、We0 AI が紹介サイト、ページ、CMS を生成し、公開後の顧客獲得と流入拡大を支援します。
初日にループが本番コードを変更できるようにしてはいけません。レポート専用モードから始め、その出力を手動で確認してください。
Grok形式のループコマンドでは、最初の実行は次のようになります。
/loop 1d Run loop-triage. Update STATE.md. No auto-fix in week one.
これは、ループにトリアージを行い、状態を書き込み、最初の1週間は自動修正を避けるよう指示します。
ステップ6: 出力を読む
STATE.md を開き、ループが何を見つけたか確認します。このファイルは会話の外部にあるメモリとして機能します。ループが何を見たのか、何を行ったのか、何をスキップしたのか、人間の注意が必要なものは何かが示されている必要があります。
出力にノイズが多い、または誤っている場合は、自律性を高める前にループを調整してください。有用なループは、退屈で、予測可能で、検査可能なものになっていくべきです。
ループ成熟度: L1からL3へ
Loop Engineeringは段階的に導入すべきです。成熟度レベルは、早すぎる段階で過度の自由を与えることを避けるのに役立ちます。
| レベル | 意味 | 推奨される用途 |
|---|---|---|
| L1 | ループは発見事項を報告し、状態を更新するが、コードは変更しない。 | 初回実行や低リスクな導入に最適。 |
| L2 | ループは検証器と人間のレビューを伴って、小さな変更を行うことができる。 | チームがループの出力を信頼した後に有用。 |
| L3 | ループは、限定的な無人実行を伴いながら、より長時間実行できる。 | スコープ、安全性、コスト、検証が成熟している場合にのみ適している。 |
最初の良い目標は、完全な自律性ではありません。最初の良い目標は、コードを変更せずに有用な情報を提供する、信頼できるL1ループです。
追加のクリーンアップ作業を生み出してしまいます。
標準的なループプロセス
完全なループには明確な順序があります。元の記事では、これを8つのステップからなるプロセスとして説明していました。
- スケジュールされたトリガー
- タスクのトリアージ
- 現在の状態を読み取る
- 隔離されたワークスペースを作成する
- エージェントに実行させる
- 検証チェックを実行する
- Git またはチケットシステムに接続する
- 必要に応じて人間の確認を求める
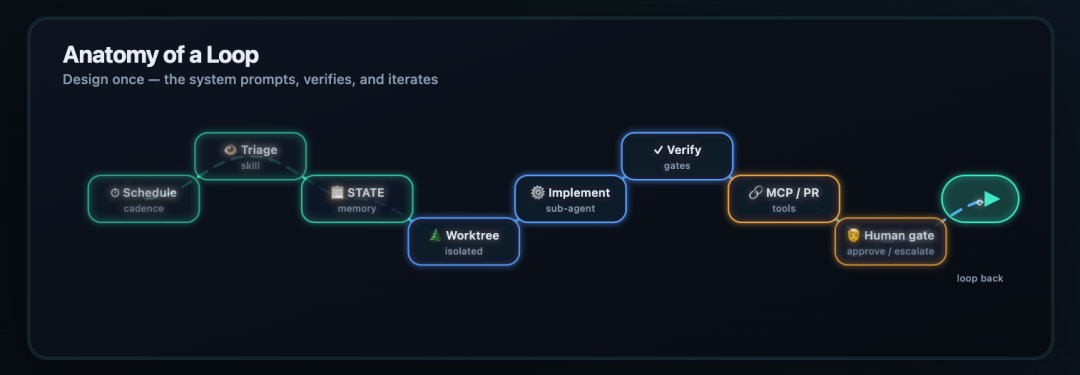
これが、気軽なプロンプトと本物のループの主な違いです。エージェントは単に「何かをしている」わけではありません。状態、隔離、チェック、引き継ぎを備えた、制御されたプロセスの中で動作しているのです。
Andrew Ng:プロダクト開発には3つのループが必要
元の記事では、Loop Engineering を Andrew Ng によるプロダクト開発の議論にも結び付けていました。重要なポイントは、AI でソフトウェアを構築することは、単一のループではないということです。実際のプロダクトでは、複数のループが異なる速度で動いています。

- エージェント型コーディングループ
最も内側のループはコーディングループです。人間がエージェントにプロダクト仕様と評価基準を与えます。エージェントはコードを書き、テストし、問題を修正し、反復を続けます。
このループは高速に回せます。場合によっては、数分ごとに新しいバージョンを生成することもあります。
- 開発者フィードバックループ
次の層は開発者フィードバックループです。エージェントはテストと修正を行えますが、その結果が適切に感じられるか、プロダクトの方向性に合っているか、実際のユーザー課題を解決しているかは、依然として開発者が確認します。
このループはより遅くなります。プロダクトや変更の複雑さに応じて、数十分ごと、または数時間ごとに実行されることがあります。
- 外部フィードバックループ
外側の層はユーザーフィードバックループです。プロダクトが友人、アルファテスター、または実際のユーザーに届くと、チームはフィードバック、利用データ、実験から学び始めます。
このループはさらに遅くなります。数時間、数日、あるいは数週間かかることもあります。

3つのループが組み合わさることで、実用的なプロダクト構築の連鎖が生まれます。エージェントはバージョンを素早く作るのを助け、開発者はプロダクトがどうあるべきかを判断し、ユーザーはその方向性を続ける価値があるかどうかを証明します。
なぜ人間の審美眼がなお重要なのか
Loop Engineering は、ソフトウェア開発から人間を排除するものではありません。人間の役割を変えるものです。
エージェントは反復的な実行を処理できますが、それでも明確な境界、強力な検証、プロダクト判断を必要とします。人間は依然として文脈を理解しています。ユーザーが何を必要としているのか、どのトレードオフが重要なのか、何を自動化すべきでないのか、そして「十分に良い」とは本当のところ何を意味するのかを理解しています。
だからこそ、ループは1つのコマンドでインストールできても、「完了」の定義は依然としてプロダクトを作る人々のものなのです。
出典について
元の出典:BAAI Hub article、QbitAI / WeChat からの転載。この記事では、Loop Engineering GitHub repository と Andrew Ng の X 上での公開投稿にも言及しています。
画像について:元ページにあった冒頭のミーム画像と最後のQRコード/連絡先プロモーションバナーは、このチュートリアルを理解するうえで必須ではないため除外しました。残りの画像は、技術的な説明を補助する場合にのみ含めています。
FAQ
Loop Engineering とは何ですか?
Loop Engineering とは、AIエージェントのために反復可能なワークフローを設計する方法です。小さなタスクごとに手動でエージェントへプロンプトを与えるのではなく、スケジューリング、状態、ツール、検証、人間への引き継ぎを備えたループを定義します。
Loop Engineering プロジェクトを始めるにはどうすればよいですか?
最も早い開始方法は、Git プロジェクト内で npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude を実行することです。初心者には通常、高頻度ループよりも daily-triage の方が安全です。レポートのみのモードで開始できるためです。
なぜ Loop Engineering は STATE.md を使うのですか?
STATE.md は、チャットセッションの外側にループの永続的な記憶を提供します。これにより、ループは過去の発見、直近のアクション、未解決項目、人間による上書きを記憶しやすくなります。
Loop Ready スコアとは何ですか?
Loop Ready スコアは、loop-audit によって生成される監査結果です。プロジェクトに、ループを責任ある形で実行するために十分な構造、状態、検証、コスト上限、安全制御があるかどうかをチェックします。
AIエージェントのループは無人で実行できますか?
それは
可能ですが、そのように始めるべきではありません。より安全な進め方は、まず L1 のレポート専用から始め、次に検証付きの L2 支援修正へ進み、スコープ、安全性、コスト管理が十分に成熟してから L3 の無人実行に移行することです。
ループを実行する前にトークンコストを見積もるべきなのはなぜですか?
ループは、頻繁に実行されたり、長いコンテキストを使用したり、複数のサブエージェントを起動したりすると、高額になる可能性があります。loop-cost は、高頻度のワークフローが予算を使い切ってしまう前に、使用量を見積もるのに役立ちます。
Andrew Ng の「3 つのループ」という考え方は、これとどう関係しますか?
エンジニアリングループは、エージェントがソフトウェアをすばやく構築し、修正するのに役立ちます。開発者フィードバックとユーザーフィードバックはより遅いループであり、そのプロダクトが有用で、使いやすく、継続する価値があるかどうかを判断します。
関連ツール
- Loop Engineering: AI エージェントループを設計するためのオープンソースのパターン、スターター、CLI ツール。
- Loop Engineering Showcase: パターン、プリミティブ、準備状況シミュレーターを備えたインタラクティブな概要。
- Node.js:
npxベースの CLI ツールを使用するために必要なランタイム。 - npm:
npxを通じて Loop Engineering CLI コマンドを実行するために使われるパッケージエコシステム。 - Git: リポジトリや worktree ベースの分離実行に使用されるバージョン管理システム。
- GitHub Actions: スケジュールされたチェックやループ検証ワークフローをサポートできる自動化プラットフォーム。
- Model Context Protocol: AI システムを外部ツールやデータソースに接続するためのプロトコル。
関連リンク
- Original BAAI Hub Article: 初心者向けの Loop Engineering チュートリアルを紹介する元記事。
- Loop Engineering GitHub Repository: パターン、スターター、ドキュメント、CLI ツールのメインリポジトリ。
- Loop Engineering Showcase: フレームワークを探索するための公式インタラクティブページ。
- Five Primitives + Memory: コアループの構成要素に関する公式説明。
- Loop Design Checklist: ループが本番利用に対応できるかを判断するためのチェックリスト。
- Loop Safety Guide: 自動化、拒否リストのパス、人間によるレビュー、リスク管理に関する安全上の注意。
- Operating Loops: コスト、ログ、実行履歴、運用規律に関するメモ。
- Loop Patterns README: 利用可能な本番向けループパターンの概要。
まとめ
このガイドでは、Loop Engineering が単発の AI プロンプトを、繰り返し実行可能なエージェントワークフローへと変える方法を説明します。基本的な考え方は、エージェントが繰り返し行動することを信頼する前に、スケジュール、状態、ツール、検証、人間によるレビューのプロセスを定義することです。
初回実行には、daily-triage が最も安全な出発点です。ループをスキャフォールドし、トークンコストを見積もり、準備状況を監査し、最初の 1 週間はレポート専用モードにしておきます。
より大きな教訓は、人間が開発から消えるということではありません。エージェントはループ内でより速く動けますが、プロダクトに関する判断、安全境界、「完了」の定義は、依然として人間に依存しています。
最初に作るべき最良のループは、最も自律的なものではありません。点検でき、信頼でき、改善できるループです。


