
Ключевые выводы
Самые дорогие ошибки в Gemini 3.5 Flash — это не синтаксические ошибки, а незаметные настройки по умолчанию.
Для многих агентных сценариев программирования
lowоказывается лучшим значением по умолчанию, чем ожидают люди.Тяжёлые агентные циклы через GitHub Copilot могут стать намного дороже из-за тарификации 14x.
В We0 AI выбор модели — лишь часть рабочего процесса. Всё остальное — это то, как продукт объясняется, показывается и обнаруживается пользователями.
gemini-3.5-flash кажется простым для вызова.
Именно поэтому его легко недооценить. Даже небольшая миграция с кода эпохи preview всё ещё может привести к худшим результатам, другому профилю затрат и более дорогим многошаговым циклам без единой видимой ошибки.
Это руководство сосредоточено на трёх самых важных ловушках, форме кода, которая позволяет их избежать, и практическом агентном цикле в стиле MCP, который можно быстро адаптировать.
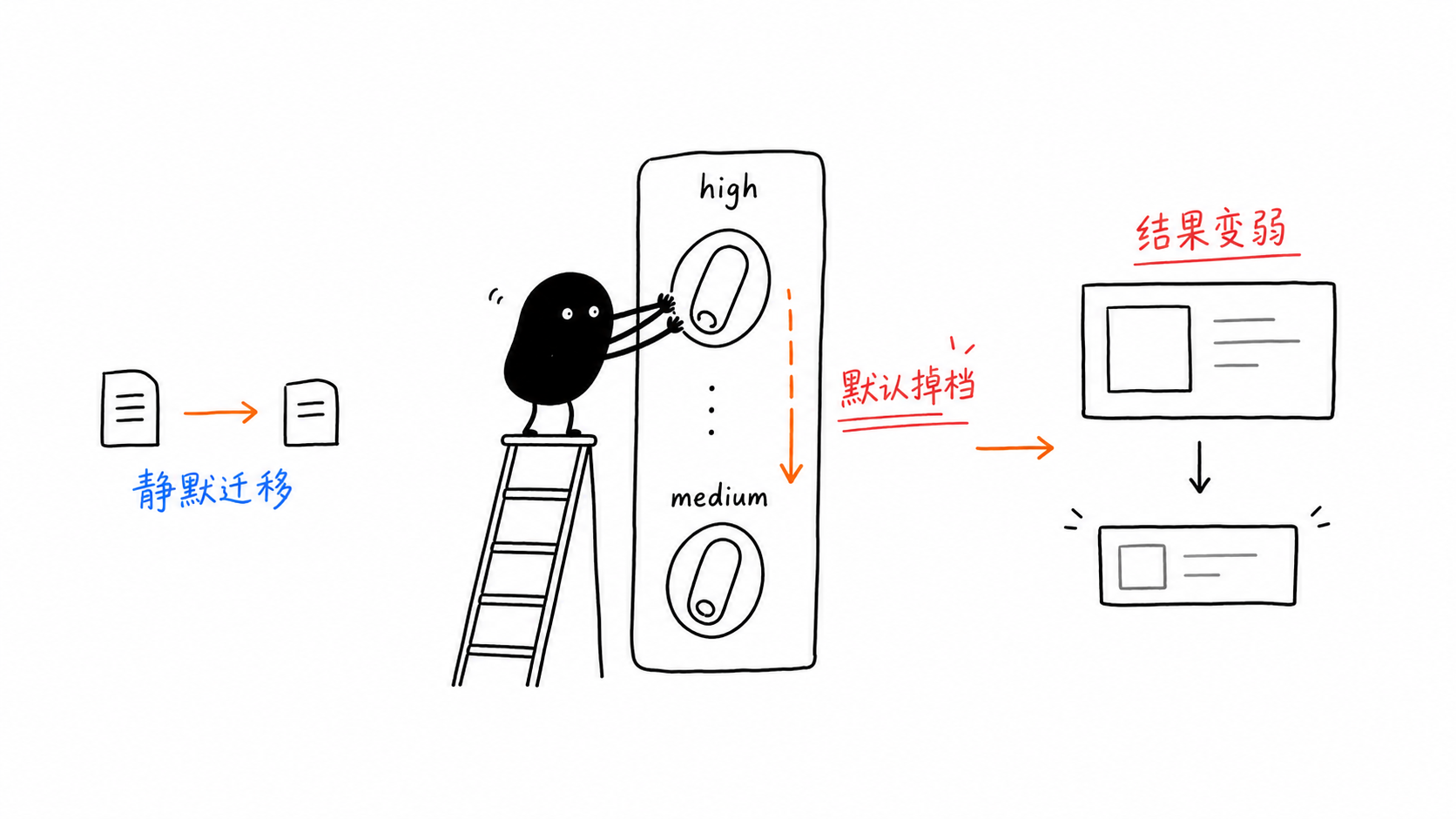
Ловушка 1: значение по умолчанию для thinking_level снизилось с high до medium
Это опасно, потому что ничего не ломается.
Вы переносите старый код, запрос по-прежнему возвращает результат, но модель уже рассуждает не на том уровне, который вы предполагали.
Старая и новая ментальная модель
Значение
Что делает
Когда использовать
minimal
Минимально необходимое рассуждение
Автодополнение, классификация, одношаговые завершения
low
Перенастроено для кода и агентных задач
Кодовые агенты, циклы инструментов MCP, многошаговые рабочие процессы
medium
Новое значение по умолчанию — сбалансированное
Потребительский чат, общие вопросы и ответы
high
Максимальное усилие рассуждения
Сложные рассуждения, отладка новых проблем, математика, планирование
Лёгкая ошибка
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)Второй фрагмент выполняется, но значения по умолчанию уже не те же самые.
Более безопасный перенос
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)Неочевидная рекомендация
Для многих рабочих процессов с кодовыми агентами лучше начинать с low, а не с high.
Практическая причина проста:
быстрее
дешевле
часто достаточно хорошо или сопоставимо для циклов программирования с активным использованием инструментов
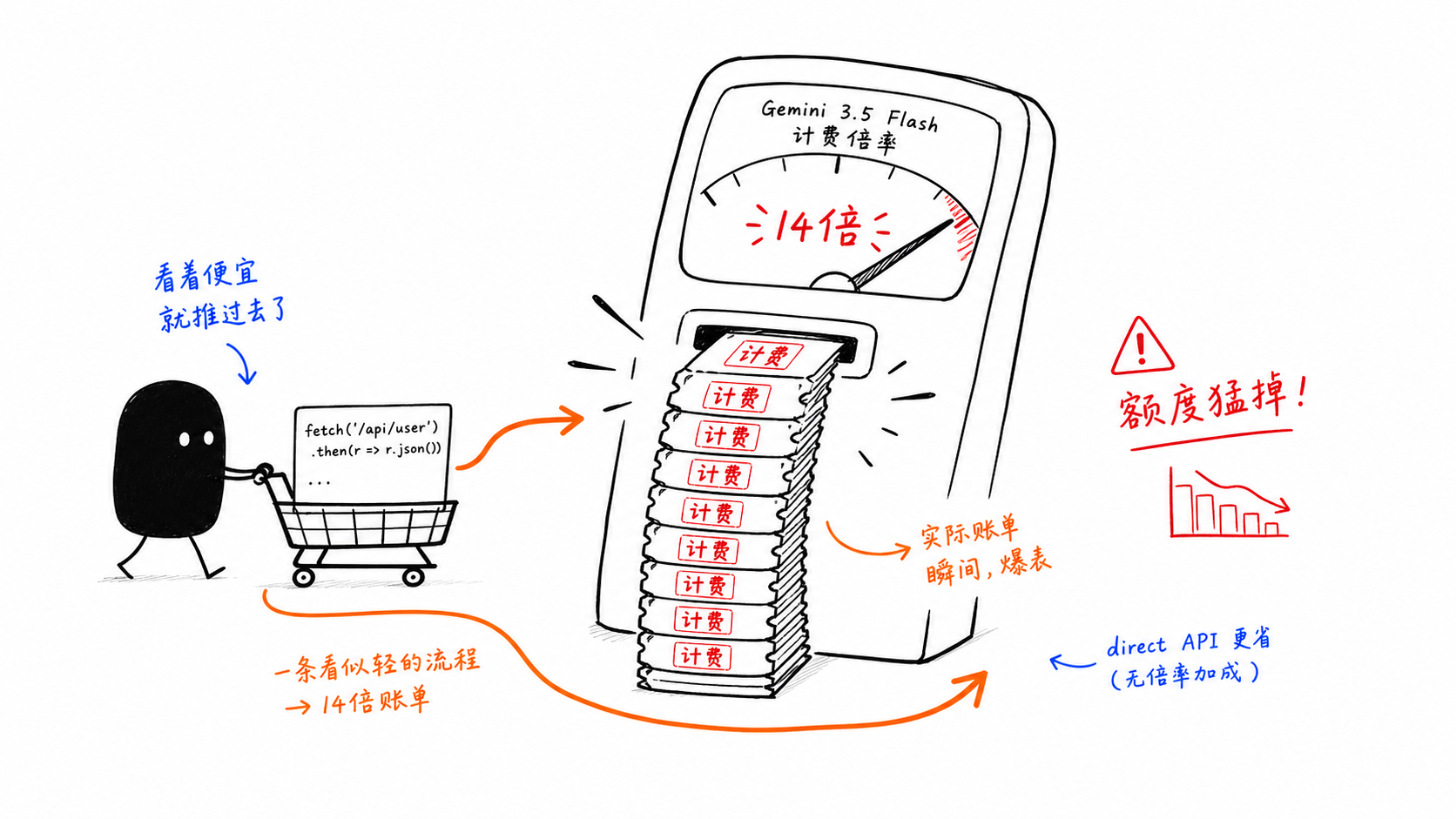
Ловушка 2: GitHub Copilot тарифицирует Gemini 3.5 Flash с коэффициентом 14x
Это самая дорогая ловушка в статье.
Проблема не в базовой цене модели. Проблема в множителе premium-request внутри GitHub Copilot. Как только Flash начинает использоваться агентно, структура затрат быстро меняется.
Именно поэтому многие команды разделяют путь:
лёгкое интерактивное использование остаётся внутри Copilot
тяжёлые циклы и пакетные рабочие процессы идут через прямой API
Архитектура становится инструментом контроля затрат.
Ловушка 3: сохранение мыслительного процесса автоматически раздувает счета за токены в многошаговых диалогах
Gemini 3.5 Flash переносит внутренние рассуждения между ходами диалога.
Это повышает согласованность, но также означает, что эти мысли могут продолжать появляться в учёте токенов на последующих шагах.
Для длинных агентных циклов это может существенно увеличить расход токенов.
Практические способы смягчения
сбрасывайте чаты на чистых границах этапов
резюмируйте и переносите дальше только действительно важное
используйте кэширование промптов для стабильных инструкций и определений инструментов
следите за соотношением токенов мыслей к токенам промпта с течением времени
Рабочий MCP-агент на Gemini 3.5 Flash
Исходная статья включает очень полезный сквозной шаблон: один инструмент для чтения файлов, один инструмент для получения данных по URL, стандартную форму объявления функций и цикл, который отправляет ответы инструментов обратно в модель.
Определения инструментов
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Шаблон цикла агента
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
history.append(types.Content(role="tool", parts=tool_results))Небольшое, но критически важное правило миграции заключается в том, что ответ вашей функции должен соответствовать и id, и name из исходного вызова.
Когда вместо этого стоит использовать Antigravity
Вручную строить циклы инструментов нормально для прототипов. Но в продакшене вы быстро приходите к тому, что заново создаёте оркестрацию, кэширование, маршрутизацию, повторные попытки и наблюдаемость.
Именно поэтому более важный вопрос заключается не только в том, «могу ли я подключить эту модель», но и в том, «какой объём агентной инфраструктуры мне придётся поддерживать самостоятельно?»
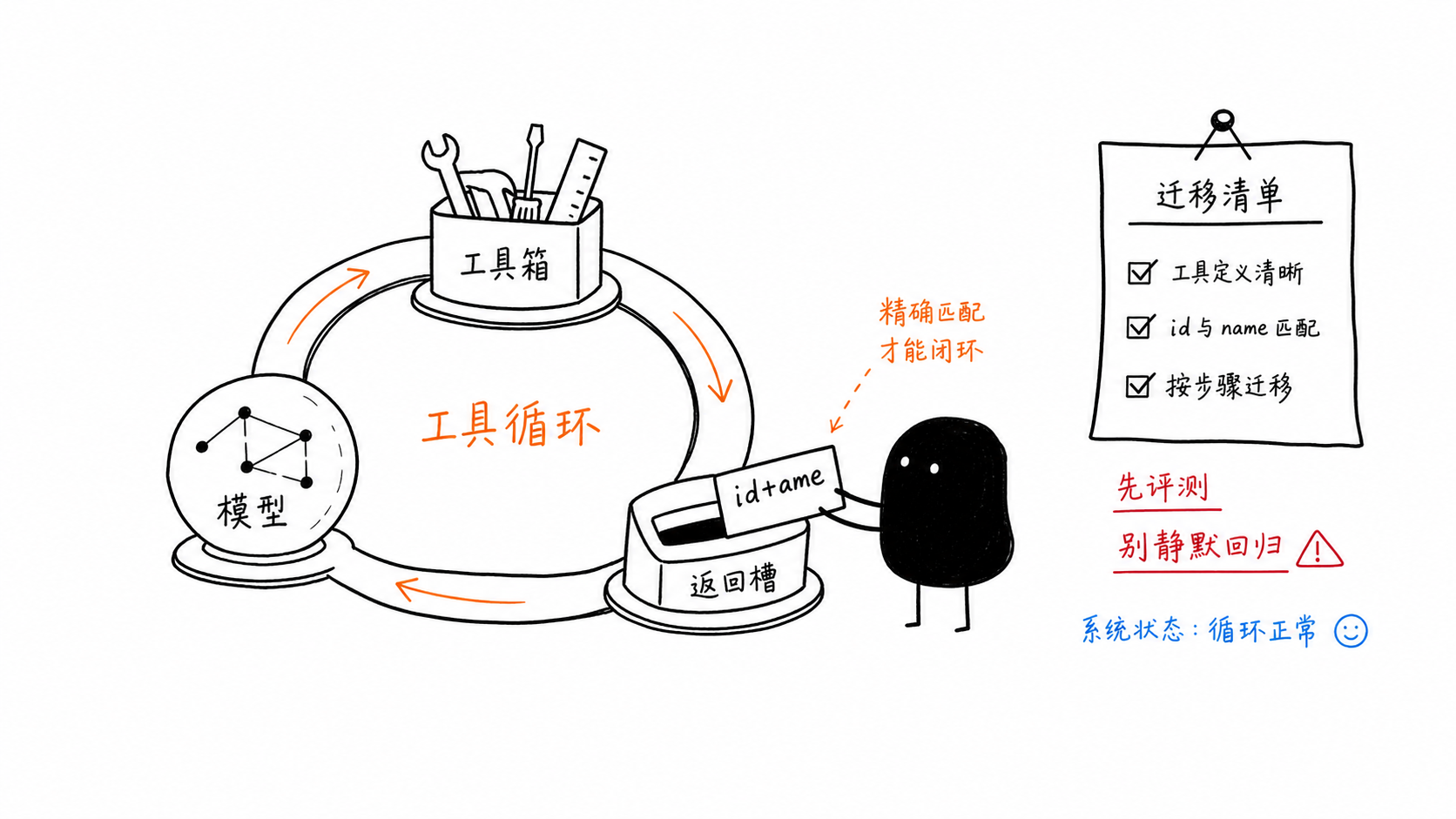
Краткий чеклист миграции
Если вы переходите с gemini-3-flash-preview на gemini-3.5-flash, явно проверьте следующие пункты:
внимательно замените идентификатор модели
осознанно задайте
thinking_levelудалите устаревшие переопределения сэмплирования, если только оценки не подтверждают их необходимость
сопоставляйте id и name в ответах инструментов
проверяйте
response.usage_metadata.thoughts_token_countоставьте preview для неподдерживаемых API, от которых вы всё ещё зависите
проводите оценки до и после
сравнивайте тарификацию Copilot с прямыми затратами на API
Попробуйте Gemini 3.5 Flash со своими инструментами
Если ваша цель — не только тестировать промпты, но и связывать вместе файлы, репозитории, API, документы и агентные рабочие процессы, вам обычно нужно нечто большее, чем просто конечная точка модели.
В We0 AI этот же принцип идёт ещё на шаг дальше: рабочий процесс агента — это лишь половина дела. Остальное — сделать продукт понятным, доступным для поиска, рекомендованным и конверсионным с помощью документации, FAQ, страниц продукта, демонстрационного контента и поверхностей SEO / GEO.
FAQ
Как вызвать Gemini 3.5 Flash из Python?
Сам вызов короткий. Важная часть — явно задать thinking_level, чтобы миграция не привела незаметно к ухудшению качества вывода.
Какие значения есть у thinking_level?
minimalдля очень лёгких задачlowдля программирования и агентных рабочих процессовmediumкак стильный по умолчанию вариант для потребительских сценариевhighдля более сложных рассуждений и более глубокого планирования
Почему Gemini 3.5 Flash стоит дороже внутри GitHub Copilot?
Потому что множитель тарификации меняет экономику использования. При интенсивном использовании агентом это может влиять на общую стоимость сильнее, чем базовая цена модели.
Что такое сохранение мыслительного контекста?
Это когда модель переносит внутреннее рассуждение между ходами диалога. Это помогает сохранять связность в многошаговых взаимодействиях, но также увеличивает вероятность того, что со временем стоимость токенов будет расти.
Подходит ли Gemini 3.5 Flash для MCP?
Да, особенно когда схемы инструментов, сопоставление ответов, thinking_level и распределение токенов обрабатываются тщательно.


