

Key Takeaways
The most expensive Gemini 3.5 Flash mistakes are silent defaults, not syntax errors.
For many coding agents,
lowis the better default than people expect.Heavy agent loops through GitHub Copilot can become much more expensive because of 14x metering.
At We0 AI, model choice is only part of the workflow. The rest is how the product gets explained, surfaced, and discovered.
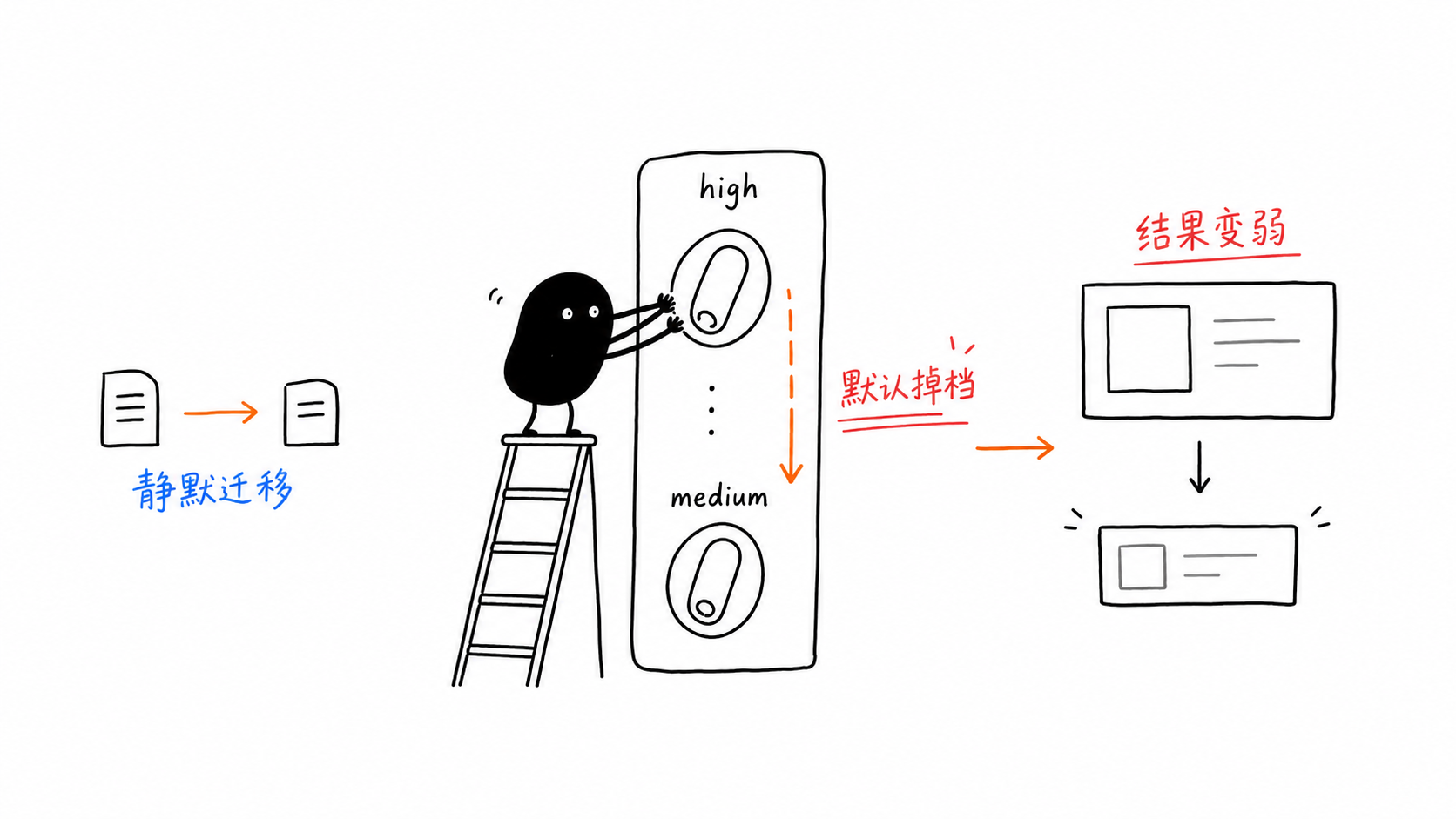
gemini-3.5-flash looks easy to call.
That is exactly why it is easy to underestimate. A small migration from preview-era code can still produce worse outputs, a different cost profile, and more expensive multi-turn loops without ever throwing a visible error.
This guide focuses on the three traps that matter most, the code shape that avoids them, and a practical MCP-style agent loop you can adapt quickly.
Trap 1: The thinking_level Default Dropped From High to Medium
This is dangerous because nothing crashes.
You port the old code, the request still returns, but the model is no longer reasoning at the level you assumed.
Old vs new mental model
Value
What it does
When to use
minimal
Bare-minimum reasoning
Autocomplete, classification, single-shot completions
low
Retuned for code and agentic tasks
Coding agents, MCP tool loops, multi-step workflows
medium
New default — balanced
Consumer chat, general Q&A
high
Maximum reasoning effort
Hard reasoning, debugging novel issues, math, planning
The easy mistake
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)The second snippet runs, but the defaults are no longer the same.
A safer port
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)The counter-intuitive recommendation
For many coding-agent workflows, start with low, not high.
The practical reason is simple:
faster
cheaper
often good enough or comparable for tool-heavy coding loops
Trap 2: GitHub Copilot Bills Gemini 3.5 Flash at 14x
This is the costliest trap in the article.
The issue is not the model list price. It is the premium-request multiplier inside GitHub Copilot. Once Flash is used agentically, the cost shape changes fast.
That is why many teams split the path:
lightweight interactive usage stays inside Copilot
heavy loops and batch-style workflows go through the direct API
Architecture becomes cost control.
Trap 3: Thought Preservation Auto-Inflates Multi-Turn Token Bills
Gemini 3.5 Flash carries forward internal reasoning across turns.
That improves coherence, but it also means those thoughts can keep showing up inside later-token accounting.
For long agent loops, that can lift token usage substantially.
Practical mitigations
reset chats at clean phase boundaries
summarize and carry forward only what matters
use prompt caching for stable instructions and tool definitions
watch the ratio of thoughts tokens to prompt tokens over time
A Working MCP Agent on Gemini 3.5 Flash
The source article includes a very useful end-to-end pattern: one file-reading tool, one URL-fetching tool, a standard function declaration shape, and a loop that sends tool responses back to the model.
Tool definitions
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Agent loop pattern
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
history.append(types.Content(role="tool", parts=tool_results))The small but crucial migration rule is that your function response needs to match both id and name from the original call.
When to Reach for Antigravity Instead
Manually building tool loops is fine for prototypes. In production, you quickly end up rebuilding orchestration, caching, routing, retries, and observability.
That is why the more important question is not only “can I wire this model in,” but “how much agent infrastructure am I about to own myself?”
Quick Migration Checklist
If you are moving from gemini-3-flash-preview to gemini-3.5-flash, check these items explicitly:
replace the model id carefully
set
thinking_levelon purposeremove stale sampling overrides unless evals justify them
match id and name in tool responses
inspect
response.usage_metadata.thoughts_token_countkeep preview for unsupported APIs you still depend on
run before/after evals
compare Copilot metering against direct API costs
Try Gemini 3.5 Flash With Your Tools
If your goal is not only testing prompts but connecting files, repos, APIs, docs, and agent workflows together, you usually need more than a raw model endpoint.
At We0 AI, that same principle extends one step further: the agent workflow is only half the work. The rest is making the product understandable, searchable, recommendable, and convertible through docs, FAQs, product pages, showcase content, and SEO / GEO surfaces.
FAQ
How do I call Gemini 3.5 Flash from Python?
The call itself is short. The part that matters is setting thinking_level explicitly so the migration does not silently degrade output quality.
What are the thinking_level values?
minimalfor very light taskslowfor coding and agentic workflowsmediumas the consumer-style default
high for harder reasoning and deeper planning
Why does Gemini 3.5 Flash cost more inside GitHub Copilot?
Because the metering multiplier changes the economics. For heavy agent use, that can dominate the cost story more than the base model price.
What is thought preservation?
It is the model carrying internal reasoning forward across turns. That helps multi-turn coherence, but it also increases the chance that token costs rise over time.
Is Gemini 3.5 Flash good for MCP?
Yes, especially when tool schemas, response matching, thinking_level, and token budgeting are handled with care.


