
Introdução
Se você tem ouvido pessoas falando sobre “Engenharia de Loops”, mas ainda não sabe bem por onde começar, este guia oferece um ponto de entrada prático.
Em vez de escrever prompts repetidamente e verificar cada etapa manualmente, um loop permite que um agente de IA trabalhe em direção a um pequeno objetivo seguindo uma programação. O sistema pode atribuir a tarefa, ler o estado atual, executar o agente, verificar o resultado e chamar um humano de volta quando for necessário julgamento.
O relatório original apresentou um framework open source de Engenharia de Loops criado por Cobus Greyling. Na época do relatório, o projeto tinha alcançado cerca de 4,5 mil estrelas no GitHub. O repositório pode exibir uma contagem diferente agora, pois continuou crescendo.
Em resumo: o objetivo já não é apenas escrever prompts melhores. O objetivo é projetar um loop confiável que possa gerar prompts, verificar e iterar com limites claros.

O que é Engenharia de Loops?
Engenharia de Loops é uma forma de projetar fluxos de trabalho repetíveis para agentes de IA. Um loop não é apenas um prompt. É um pequeno sistema operacional em torno de um agente: ele define quando o agente é executado, qual contexto ele lê, o que ele tem permissão para alterar, como o resultado é verificado e quando um humano precisa revisar o resultado.
Um loop típico pode ser usado para tarefas como:
- triagem diária de projetos;
- monitoramento de pull requests;
- correção de falhas de CI;
- verificação de dependências;
- classificação de issues;
- limpeza após merges;
- elaboração de changelogs.
Essas tarefas nem sempre são difíceis, mas são repetitivas. Elas exigem atenção, contexto e um padrão consistente. Esse é exatamente o tipo de trabalho em que um loop bem projetado pode ajudar.
Por que este framework está chamando atenção
O framework open source descrito no artigo original reúne padrões práticos de loops, templates iniciais e ferramentas de linha de comando. Ele foi projetado para agentes de codificação com IA e oferece suporte a fluxos de trabalho com ferramentas como Claude Code, Codex, Grok e OpenCode.
O framework inclui:
- sete padrões de loop prontos para uso;
- templates iniciais para cenários comuns;
loop-initpara criar a estrutura inicial de um loop;loop-costpara estimar o custo em tokens;loop-auditpara verificar se o loop está pronto;- arquivos de estado e orçamento para fluxos de trabalho de execução mais longa;
- suporte a revisão humana mais segura e implantação em fases.
A mensagem central é simples:
Pare de apenas criar prompts. Projete o loop.
Isso não significa que os prompts desaparecem. Significa que os prompts passam a fazer parte de um sistema maior, capaz de repetir trabalho, rastrear estado e verificar resultados.
Comece rápido: um comando
A forma mais rápida de começar é executar loop-init dentro de um projeto Git.
Observação: algumas versões republicadas do artigo original exibem flags de linha de comando com um travessão longo. Em um terminal real, use o hífen duplo padrão
--mostrado abaixo.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
Esse comando cria a estrutura inicial do loop no seu projeto atual. Você pode substituir claude por outra ferramenta compatível, como grok, codex ou opencode, dependendo do fluxo de trabalho que deseja testar.
O padrão daily-triage é um bom ponto de partida para iniciantes porque oferece menos risco do que automações de alta frequência. Ele se concentra em examinar o estado atual do projeto e produzir um relatório antes de permitir qualquer alteração automática.
Tutorial de Loops para iniciantes
Engenharia de Loops pode parecer abstrata no começo, mas o framework a divide em alguns blocos de construção concretos.
Os cinco blocos de construção mais a memória
Em um nível básico, um loop é construído a partir de cinco partes principais, além de memória e estado.
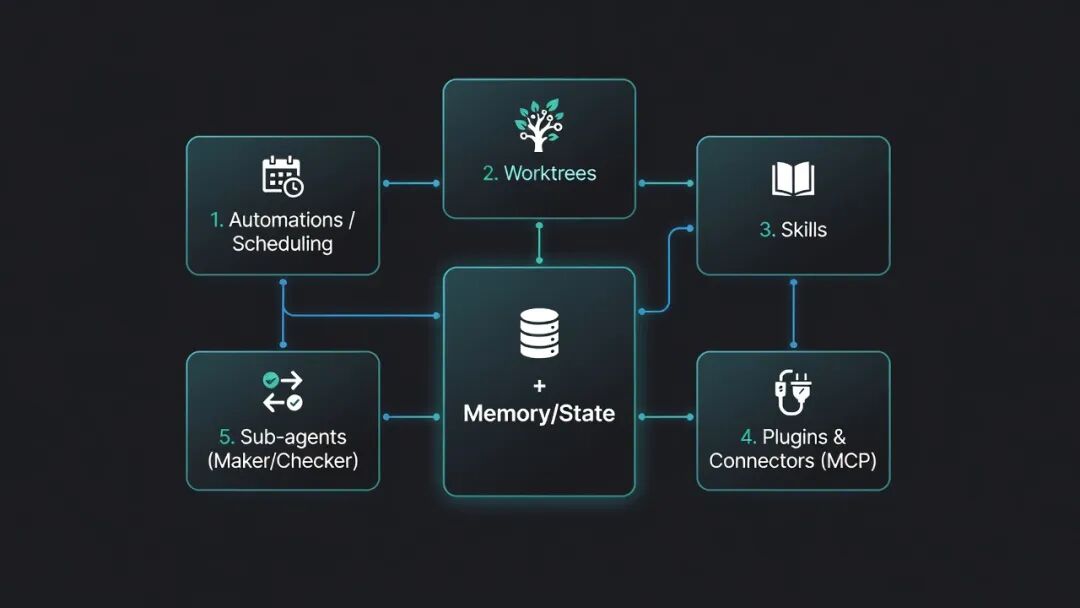
| Bloco de construção | O que faz no loop |
|---|---|
| Automação / Agendamento | Executa o loop em uma cadência, como diariamente, a cada hora ou a cada poucos minutos. |
| Worktrees | Cria ambientes de trabalho isolados para que vários agentes não sobrescrevam o trabalho uns dos outros. |
| Habilidades | Armazena conhecimento reutilizável do projeto, regras e instruções de tarefas. |
| Plugins e conectores | Conecta o loop a ferramentas reais por meio de sistemas como MCP, GitHub, Linear ou Slack. |
| Subagentes | Separa o papel de criador do papel de verificador, para que o mesmo agente não aprove o próprio trabalho. |
| Memória / Estado | Mantém contexto durável fora do |
chat, geralmente por meio de arquivos como STATE.md. |
Essa estrutura torna o loop mais fácil de entender e avaliar. Você não está pedindo ao modelo para “simplesmente lidar com tudo”. Você está oferecendo a ele um ambiente definido, uma programação, um arquivo de estado, um caminho de verificação e uma regra de encaminhamento para humanos.
Sete padrões de produção prontos para uso
O framework também inclui sete padrões orientados à produção. Cada padrão tem uma cadência, um nível de risco e um melhor caso de uso diferentes.

| Padrão | Caso de uso típico | Modo inicial sugerido |
|---|---|---|
| Daily Triage | Verificar o status do projeto, issues, CI e commits. | L1 report-only |
| PR Babysitter | Acompanhar pull requests durante revisão, CI, rebase e merge. | L1 watch |
| CI Sweeper | Acompanhar verificações com falha e propor ou aplicar pequenas correções. | L2 cautious |
| Dependency Sweeper | Verificar dependências desatualizadas e atualizações de segurança. | L2 patch-only |
| Issue Triage | Deduplicar, pontuar e rotular issues recebidas. | L1 propose-only |
| Post-Merge Cleanup | Limpar TODOs, pequenas dívidas técnicas e trabalhos de acompanhamento após merges. | L1 off-peak |
| Changelog Drafter | Rascunhar notas de lançamento a partir de commits e alterações mescladas. | L1 draft |
O conselho prático é começar com um loop de baixo risco. A triagem diária costuma ser mais fácil de confiar porque não precisa alterar código imediatamente.
Seletor interativo de padrões
O projeto também oferece um seletor interativo. Em vez de escolher um padrão manualmente, você pode partir de um ponto de dor, como “PRs continuam ficando travados”, “CI continua falhando” ou “as issues estão muito ruidosas”.
O seletor então recomenda um padrão de loop e fornece um comando inicial. Isso é útil quando você conhece o problema, mas não tem certeza de qual loop deve lidar com ele.
Execute seu primeiro loop
Aqui está uma forma amigável para iniciantes de executar o primeiro loop mantendo o risco sob controle.
Etapa 1: Escolha um padrão
Comece com daily-triage se esta for sua primeira vez. É um padrão de baixo risco e uma boa maneira de entender como o loop lê o estado do projeto, escreve notas e prepara trabalho para uma pessoa.
Etapa 2: Estruture o loop
Execute o comando de inicialização no diretório raiz do seu projeto Git.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
Você pode trocar o nome da ferramenta se estiver usando um agente de codificação de IA diferente.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool grok
npx @cobusgreyling/loop-init . --pattern daily-triage --tool codex
npx @cobusgreyling/loop-init . --pattern daily-triage --tool opencode
Você também pode substituir daily-triage por outro padrão compatível depois de entender o fluxo básico.
Etapa 3: Estime o custo de tokens
Loops de alta frequência podem consumir muitos tokens, especialmente se usarem subagentes, contexto longo ou verificação repetida. Estime o custo antes de executar um loop com muita frequência.
npx @cobusgreyling/loop-cost --pattern daily-triage --level L1
Para testes iniciais, mantenha o loop em L1 e evite programações agressivas.
Etapa 4: Audite a prontidão do loop
Antes de confiar no loop, execute uma auditoria. A auditoria atribui ao projeto uma pontuação de prontidão de 0 a 100 e sugere melhorias.
npx @cobusgreyling/loop-audit . --suggest
Se o seu projeto não estiver pronto, corrija primeiro as partes ausentes. Lacunas comuns incluem ausência de arquivo de estado, ausência de etapa de verificação, escopo pouco claro, limites de orçamento ausentes ou regras fracas de encaminhamento para humanos.
Se o projeto atingir um bom nível de prontidão, você também pode gerar um selo Loop Ready para o seu README.
npx @cobusgreyling/loop-audit . --badge
Etapa 5: Comece em modo somente relatório
Crie um site de apresentacao e gere leads em minutos
Descreva sua ideia uma vez e o We0 AI pode gerar um site de apresentacao, paginas e CMS, alem de ajudar a atrair clientes e trafego apos o lancamento.
Não permita que o loop modifique código de produção no primeiro dia. Comece com o modo somente relatório e depois revise a saída manualmente.
Para um comando de loop no estilo Grok, a primeira execução pode ser assim:
/loop 1d Run loop-triage. Update STATE.md. No auto-fix in week one.
Isso instrui o loop a fazer a triagem, escrever o estado e evitar correções automáticas durante a primeira semana.
Etapa 6: Leia a saída
Abra STATE.md e verifique o que o loop encontrou. Esse arquivo funciona como memória fora da conversa. Ele deve mostrar o que o loop viu, o que fez, o que ignorou e o que precisa de atenção humana.
Se a saída estiver ruidosa ou incorreta, ajuste o loop antes de aumentar a autonomia. Um loop útil deve se tornar entediante, previsível e inspecionável.
Maturidade do loop: L1 a L3
A Engenharia de Loop deve ser implementada gradualmente. Os níveis de maturidade ajudam você a evitar conceder liberdade demais cedo demais.
| Nível | Significado | Uso recomendado |
|---|---|---|
| L1 | O loop relata descobertas e atualiza o estado, mas não altera código. | Melhor para primeiras execuções e adoção de baixo risco. |
| L2 | O loop pode fazer pequenas alterações com um verificador e revisão humana. | Útil depois que a equipe confia na saída do loop. |
| L3 | O loop pode ser executado por períodos mais longos com execução limitada sem supervisão. | Adequado apenas quando escopo, segurança, custo e verificação estão maduros. |
Um bom primeiro objetivo não é autonomia total. Um bom primeiro objetivo é um loop L1 confiável que forneça informações úteis sem
criando trabalho extra de limpeza.
O Processo Padrão de Loop
Um loop completo tem uma sequência clara. O artigo original o descreveu como um processo de oito etapas:
- gatilho agendado;
- triagem de tarefas;
- leitura do estado atual;
- criação de um espaço de trabalho isolado;
- permitir que o agente execute;
- executar verificações de validação;
- conectar-se ao Git ou a sistemas de tickets;
- pedir confirmação humana quando necessário.
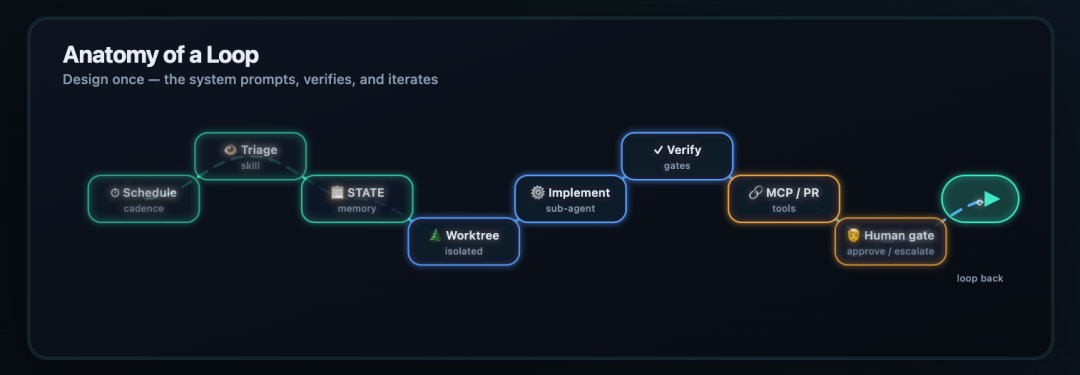
Esta é a principal diferença entre um prompt casual e um loop real. O agente não está simplesmente “fazendo coisas”. Ele está trabalhando dentro de um processo controlado, com estado, isolamento, verificações e transferência de responsabilidade.
Andrew Ng: O Desenvolvimento de Produtos Precisa de Três Loops
O artigo original também conectou a Loop Engineering à discussão de Andrew Ng sobre desenvolvimento de produtos. O ponto principal é que criar software com IA não envolve apenas um loop. Para um produto real, há vários loops funcionando em velocidades diferentes.

- Loop de Codificação Agêntica
O loop mais interno é o loop de codificação. Um humano fornece ao agente uma especificação do produto e critérios de avaliação. O agente escreve código, testa, corrige problemas e continua iterando.
Esse loop pode ser rápido. Em alguns casos, pode produzir uma nova versão a cada poucos minutos.
- Loop de Feedback do Desenvolvedor
A próxima camada é o loop de feedback do desenvolvedor. O agente pode testar e revisar, mas o desenvolvedor ainda verifica se o resultado parece adequado, se está alinhado à direção do produto e se resolve o problema real do usuário.
Esse loop é mais lento. Ele pode rodar a cada algumas dezenas de minutos ou a cada algumas horas, dependendo do produto e da complexidade das mudanças.
- Loop de Feedback Externo
A camada externa é o loop de feedback do usuário. Quando o produto chega a amigos, testadores alfa ou usuários reais, a equipe começa a aprender com feedback, dados de uso e experimentos.
Esse loop é ainda mais lento. Pode levar horas, dias ou semanas.

Juntos, os três loops criam uma cadeia prática de construção de produtos: o agente ajuda a produzir versões rapidamente, o desenvolvedor decide no que o produto deve se tornar, e os usuários comprovam se vale a pena continuar naquela direção.
Por Que o Gosto Humano Ainda Importa
A Loop Engineering não remove os humanos do desenvolvimento de software. Ela muda o papel humano.
O agente pode lidar com a execução repetida, mas ainda precisa de limites claros, verificação robusta e julgamento de produto. O humano ainda entende o contexto: do que os usuários precisam, quais trade-offs importam, o que não deve ser automatizado e o que “bom o suficiente” realmente significa.
É por isso que um loop pode ser instalado com um único comando, mas a definição de “concluído” ainda pertence às pessoas que estão construindo o produto.
Nota da Fonte
Fonte original: artigo do BAAI Hub, republicado a partir de QbitAI / WeChat. O artigo também fez referência ao repositório Loop Engineering no GitHub e à publicação pública de Andrew Ng no X.
Nota sobre imagens: a imagem de meme de abertura e o banner promocional final com QR/contato da página de origem foram excluídos porque não são necessários para entender o tutorial. As imagens restantes são incluídas apenas quando apoiam a explicação técnica.
FAQ
O que é Loop Engineering?
Loop Engineering é uma forma de projetar fluxos de trabalho repetíveis para agentes de IA. Em vez de solicitar manualmente ao agente cada pequena tarefa, você define um loop com agendamento, estado, ferramentas, verificação e transferência para humanos.
Como começo um projeto de Loop Engineering?
O ponto de partida mais rápido é executar npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude dentro de um projeto Git. Para iniciantes, daily-triage geralmente é mais seguro do que loops de alta frequência, pois pode começar em modo somente relatório.
Por que a Loop Engineering usa STATE.md?
STATE.md dá ao loop uma memória durável fora da sessão de chat. Ele ajuda o loop a lembrar descobertas anteriores, últimas ações, itens não resolvidos e substituições feitas por humanos.
O que é a pontuação Loop Ready?
A pontuação Loop Ready é um resultado de auditoria produzido por loop-audit. Ela verifica se o projeto tem estrutura, estado, verificação, limites de custo e controles de segurança suficientes para executar um loop de forma responsável.
Um loop de agente de IA pode rodar sem supervisão?
Ele
pode, mas não deve começar dessa forma. Um caminho mais seguro é primeiro o L1 em modo somente relatório, depois correções assistidas no L2 com verificação e, só mais tarde, execuções L3 sem supervisão quando o escopo, a segurança e os controles de custo estiverem maduros.
Por que devo estimar o custo em tokens antes de executar um loop?
Loops podem ficar caros se forem executados com frequência, usarem contexto longo ou acionarem vários subagentes. loop-cost ajuda você a estimar o uso antes que um fluxo de trabalho de alta frequência consuma o orçamento.
Como a ideia dos três loops de Andrew Ng se relaciona com isso?
O loop de engenharia ajuda agentes a criar e revisar software rapidamente. O feedback dos desenvolvedores e o feedback dos usuários são loops mais lentos que determinam se o produto é útil, fácil de usar e se vale a pena continuar.
Ferramentas relacionadas
- Loop Engineering: Padrões, modelos iniciais e ferramentas CLI de código aberto para projetar loops de agentes de IA.
- Loop Engineering Showcase: Visão geral interativa com padrões, primitivas e um simulador de prontidão.
- Node.js: Runtime necessário para usar ferramentas CLI baseadas em
npx. - npm: Ecossistema de pacotes usado para executar os comandos da CLI do Loop Engineering por meio de
npx. - Git: Sistema de controle de versão usado para repositórios e execução isolada baseada em worktrees.
- GitHub Actions: Plataforma de automação que pode oferecer suporte a verificações agendadas e fluxos de validação de loops.
- Model Context Protocol: Protocolo para conectar sistemas de IA a ferramentas externas e fontes de dados.
Links relacionados
- Artigo original no BAAI Hub: Artigo-fonte que apresenta o tutorial de Loop Engineering voltado para iniciantes.
- Repositório do Loop Engineering no GitHub: Repositório principal para padrões, modelos iniciais, documentação e ferramentas CLI.
- Loop Engineering Showcase: Página interativa oficial para explorar o framework.
- Five Primitives + Memory: Explicação oficial dos blocos básicos centrais dos loops.
- Loop Design Checklist: Checklist para decidir se um loop está pronto para uso em produção.
- Loop Safety Guide: Observações de segurança para automação, caminhos em denylist, revisão humana e controle de riscos.
- Operating Loops: Notas sobre custo, logs, histórico de execuções e disciplina operacional.
- Loop Patterns README: Visão geral dos padrões de loops de produção disponíveis.
Resumo
Este guia explica como o Loop Engineering transforma prompts de IA pontuais em fluxos de trabalho de agentes repetíveis. A ideia básica é definir a agenda, o estado, as ferramentas, a verificação e o processo de revisão humana antes de confiar que um agente aja repetidamente.
Para uma primeira execução, daily-triage é o ponto de partida mais seguro. Crie a estrutura do loop, estime o custo em tokens, audite a prontidão e mantenha a primeira semana em modo somente relatório.
A lição mais ampla não é que os humanos desaparecem do desenvolvimento. Agentes podem se mover mais rápido dentro de loops, mas o julgamento de produto, os limites de segurança e a definição de “concluído” ainda dependem das pessoas.
O melhor primeiro loop não é o mais autônomo. É aquele que você consegue inspecionar, confiar e melhorar.


