Um problema recente de registo do Codex transformou uma base de dados local discreta numa fonte surpreendentemente intensa de gravações no SSD. De acordo com o relatório original no GitHub, os logs de feedback SQLite do Codex podiam gravar cerca de 640 TB por ano no padrão de utilização relatado. Para um SSD de consumidor classificado em torno de 600 TBW, esse número não é apenas um pequeno transtorno; está próximo da resistência de gravação garantida da unidade.
O mais estranho é que a base de dados de logs não parecia enorme. O ficheiro podia ficar em torno de um gigabyte, enquanto as gravações históricas reais continuavam a acumular-se em segundo plano. Foi por isso que este bug atraiu tanta atenção: ele não enchia o disco de uma forma óbvia, mas ainda assim podia consumir ciclos de gravação.

Nota sobre a fonte: Este artigo baseia-se na republicação do BAAI Hub do relatório da Xinzhiyuan e foi verificado com a issue pública do GitHub e a discussão no Hacker News. Logótipos de marcas, códigos QR, chamadas para seguir e imagens decorativas não relacionadas da página original não foram incluídos.
Como podem acontecer 640 TB de gravações no SSD
O número parece exagerado à primeira vista, por isso é útil começar pela medição.
Na issue do GitHub, o autor do relatório disse que, após cerca de 21 dias de uptime, o SSD principal tinha gravado cerca de 37 TB. Extrapolado para um ano completo, isso corresponde a aproximadamente 640 TB. A principal origem suspeita era a base de dados local de logs de feedback SQLite do Codex.
O Codex estava a gravar ficheiros no diretório de configuração local:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shm
O comportamento não era simplesmente “o arquivo de log continua crescendo para sempre”. Em vez disso, parecia mais um ciclo de inserção e poda: o Codex inseria novas linhas e depois excluía linhas antigas para manter estável a contagem de linhas retidas. O tamanho visível do arquivo permanecia relativamente controlado, mas a unidade ainda precisava processar as gravações repetidas.
Uma amostra de 15 segundos do relatório mostrou claramente o problema:
Métrica | Antes | Depois |
Linhas retidas | 681,774 | 681,774 |
ID máximo da linha | 5,003,347,015 | 5,003,383,226 |
Isso significa que cerca de 36.211 linhas foram inseridas em 15 segundos, embora a contagem de linhas retidas não tenha aumentado em nada. O banco de dados parecia estável visto de fora, mas a rotatividade de gravações continuava por baixo.
As entradas frequentes de log também não eram todas eventos de aplicação de alto valor. Os exemplos incluíam ruído repetido no nível do sistema de arquivos e das dependências, como eventos inotify:
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")
O resultado foi um sistema de logs local que podia continuar reescrevendo o armazenamento enquanto dava aos usuários pouquíssimos sinais visíveis de que algo incomum estava acontecendo.
Um arquivo de 1 GB ainda pode produzir centenas de terabytes de gravações
A parte mais contraintuitiva deste incidente é simples: o desgaste de SSDs depende do total de gravações, não do tamanho atual do arquivo.
Um banco de dados local pode permanecer em torno de 1 GB enquanto a aplicação grava, remove, indexa, cria checkpoints e reescreve partes dele repetidamente. Do ponto de vista da saúde do armazenamento, o que importa não é apenas o tamanho que o arquivo parece ter hoje. O que importa é a quantidade de dados que foi gravada ao longo do tempo.
O relatório incluía uma captura que tornava a diferença mais fácil de ver:
Métrica | Valor |
Tamanho atual do arquivo logs_2.sqlite | 1,2 GiB |
Linhas atualmente retidas | 506.149 |
Total de IDs de linha alocados | 5.543.677.486 |
O banco de dados atual mantinha apenas cerca de meio milhão de linhas, enquanto o ID de linha autoincrementado já havia ultrapassado 5,5 bilhões. Esse é o ponto central da história da amplificação de escrita: linhas antigas podem desaparecer da visualização atual do banco de dados, mas as gravações em disco que as criaram já ocorreram.
O WAL do SQLite, ou Write-Ahead Logging, também é importante aqui. Com o modo WAL, as alterações são acrescentadas a um arquivo -wal separado antes de serem consolidadas de volta no banco de dados principal por meio de checkpoint. O WAL é um mecanismo normal e útil do SQLite, mas quando uma aplicação realiza inserções e exclusões com muita frequência, ele pode multiplicar a quantidade de atividade em disco que acontece nos bastidores.
Em linguagem simples: o caderno ainda parece fino, mas as mesmas páginas foram escritas, apagadas e reescritas muitas vezes.
Causa raiz: uma configuração RUST_LOG que não se comportou como os usuários esperavam
O relatório apontou para um detalhe de configuração especialmente importante no caminho de registro do Codex:
Targets::new().with_default(Level::TRACE)
No ecossistema tracing do Rust, a filtragem de logs costuma ser controlada por meio de alvos e níveis. Os usuários podem esperar, razoavelmente, que a variável de ambiente RUST_LOG ajude a reduzir a verbosidade dos logs para algo como info, warn ou inferior.
Mas, nesse caminho, o coletor de logs de feedback do SQLite usava um padrão de TRACE. TRACE é o nível mais verboso e pode capturar detalhes de baixo nível de dependências, atividade bruta de protocolo e outros ruídos de depuração. O relatório do problema argumentou que esse padrão fazia com que o banco de dados local persistente de logs continuasse armazenando muito mais do que deveria.
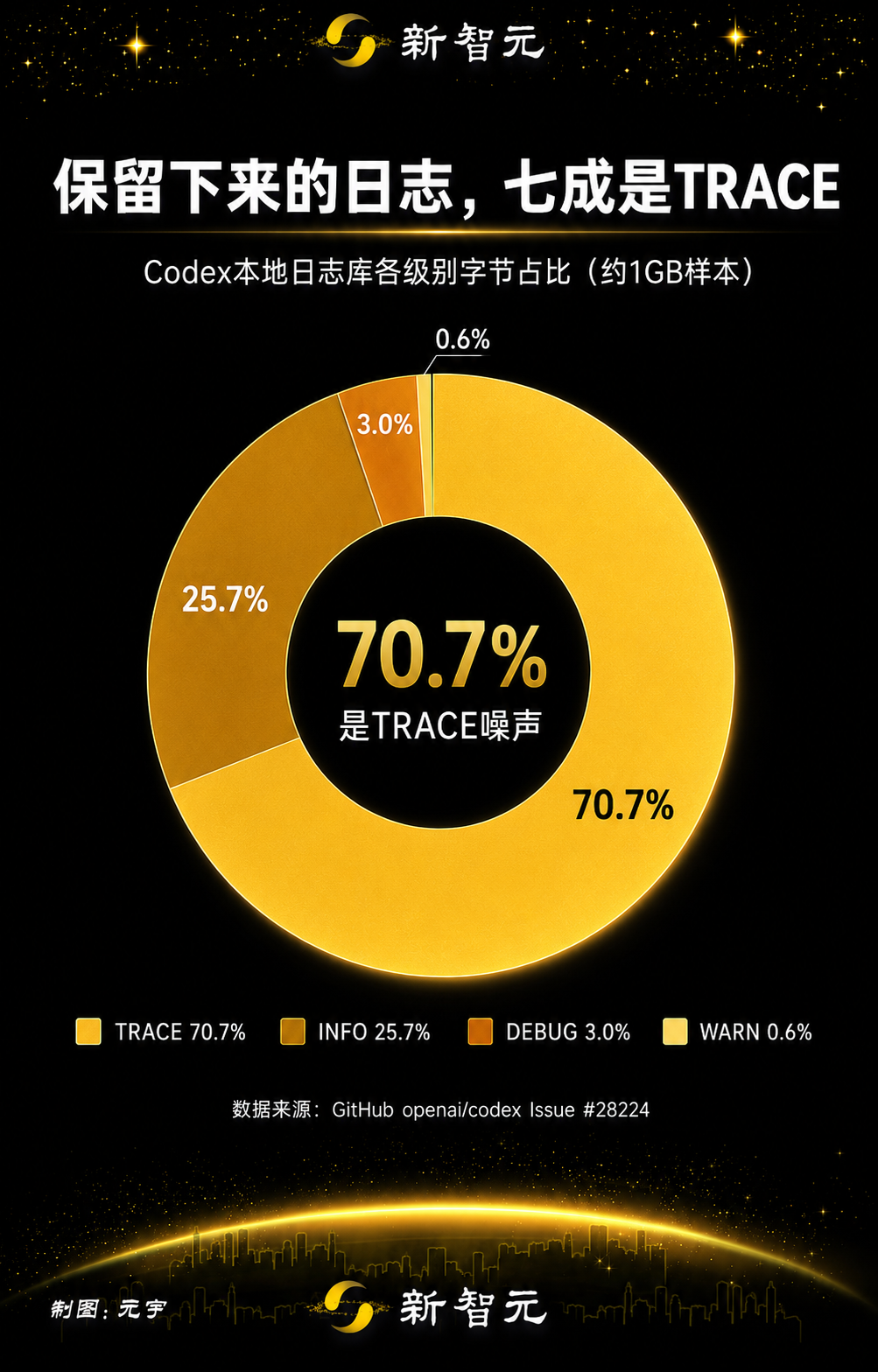
A distribuição dos logs retidos mostrou o quão dominante era o conteúdo em nível TRACE:
Nível | MiB estimado | Participação em bytes |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
O relatório também observou que duas fontes de logs espelhadas relacionadas ao OpenTelemetry, codex_otel.log_only e codex_otel.trace_safe, representavam outra grande parte dos bytes de log retidos. Nessa amostra, o relator estimou que filtrar essas categorias ruidosas poderia remover a maior parte do volume de logs retidos sem desativar completamente os logs de feedback.
É por isso que o bug pareceu tão frustrante para os desenvolvedores. Não era apenas “você esqueceu de configurar o registro de logs”. Parecia mais com “você tentou reduzir o registro de logs, mas esse caminho ainda persistia logs detalhados mesmo assim”.
Este não foi o primeiro problema relacionado
O relatório não tratou isso como um único acidente isolado. Ele listou um conjunto de problemas relacionados ao Codex envolvendo logs do SQLite, crescimento do WAL, atividade intensa em disco e registro local de logs ilimitado ou excessivo.
Alguns exemplos mencionados no relatório incluíam:
Problema | Tema relatado |
#17320
| Gravações WAL excessivas do SQLite durante o streaming porque os logs TRACE ignoravam RUST_LOG |
#24275
| Crescimento do logs_2.sqlite / WAL no desktop durante o uso normal |
#22444
| Arquivos WAL permanecendo alocados ou crescendo inesperadamente |
#26374
| Crescimento do log de feedback do SQLite sem retenção ou rotação suficientes |
#27911
| Amplificação de gravação em um banco de dados SQLite minúsculo |
border-border px-3 py-2 align-top" colspan="1" rowspan="1">#20563
E/S intensa de processos Codex ociosos |
#27020
| 100% de tempo de atividade do disco no Windows / WSL2 |
As ferramentas de programação com IA são cada vez mais tratadas como parceiros de desenvolvimento sempre ativos. Elas leem arquivos, monitoram repositórios, mantêm sessões ativas, coletam telemetria e preservam contexto. Isso torna os orçamentos locais de disco, memória e CPU tão importantes quanto os orçamentos de tokens e a qualidade do modelo.
As correções foram mescladas, mas o debate não terminou
A issue do GitHub posteriormente adicionou uma atualização dizendo que três pull requests haviam sido mesclados e que o próprio feedback do Codex do autor do relatório sugeria uma redução estimada de 85% nos logs.
A issue listou as três correções assim:
Pull Request | Objetivo | Nota de lançamento na issue |
#29432
| Parar de registrar todos os eventos WebSocket de Responses | Lançado na 0.142.0 |
#29457
| Filtrar destinos ruidosos dos logs persistentes | Lançado na 0.142.0 |
#29599
| Parar de persistir eventos de log encaminhados | Planejado para 0.143.0 |
Uma redução de 85% é significativa, mas não é o mesmo que provar que o registro local agora tem um limite rígido de gravação de longo prazo. Essa distinção é o motivo pelo qual a discussão continuou. Os desenvolvedores não estavam apenas perguntando se esse bug específico havia sido reduzido; eles estavam perguntando se os agentes de codificação de IA deveriam ter limites mais claros para a telemetria local persistente.
A issue do GitHub também incluía uma solução alternativa simples compartilhada por um comentarista. Ela bloqueia inserções na tabela logs criando um gatilho SQLite:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"
Use soluções alternativas como esta com cuidado. Elas podem reduzir as gravações de logs locais, mas também podem remover dados de diagnóstico de que as equipes de suporte ou os desenvolvedores talvez precisem mais tarde. Em geral, atualizar para uma versão corrigida e verificar o comportamento atual dos logs é mais seguro do que modificar silenciosamente um banco de dados de aplicativo sem entender a contrapartida.
A batalha das ferramentas de codificação está queimando mais do que SSDs
A discussão rapidamente foi além do Codex. No Hacker News, desenvolvedores também levantaram reclamações mais amplas sobre ferramentas de codificação de IA: alto uso de GPU, grande consumo de memória, atividade em segundo plano e grandes logs de depuração locais.

Essa reação faz sentido. Os assistentes modernos de codificação com IA já não são simples utilitários de linha de comando. Muitos deles se comportam mais como agentes locais: monitoram projetos, conversam com modelos remotos, gerenciam contexto, executam comandos e mantêm estado entre tarefas. Esse poder é útil, mas também cria uma nova categoria de responsabilidade de engenharia.
Uma ferramenta pode parecer “boa” na interface do usuário enquanto continua consumindo recursos silenciosamente em segundo plano. CPUs rápidas, muita memória e unidades NVMe modernas podem ocultar problemas por muito tempo. O aplicativo pode não travar. O disco pode não ficar cheio. O terminal pode continuar respondendo. Mas os contadores de integridade do hardware podem contar uma história diferente.
É por isso que esse incidente se tornou um estudo de caso útil para ferramentas de desenvolvimento com IA. A capacidade do modelo importa, mas a qualidade operacional local também importa. Um agente de codificação que vive na máquina de um desenvolvedor precisa de padrões sensatos, limites de retenção, rotação de logs e uma forma de os usuários entenderem o que ele está fazendo.
FAQ
Qual era o bug de log SQLite do Codex?
Foi um problema relatado de registro do Codex em que logs locais de feedback em SQLite podiam gerar quantidades muito grandes de gravações em disco. O relatório no GitHub estimou cerca de 640 TB de gravações por ano sob o padrão de uso medido pelo autor do relato.
Por que um pequeno arquivo logs_2.sqlite ainda poderia desgastar um SSD?
A durabilidade de um SSD depende do total de dados gravados ao longo do tempo, não apenas do tamanho atual do arquivo. Um banco de dados pode inserir, excluir, gravar no WAL, fazer checkpoint e atualizar índices repetidamente, enquanto ainda parece pequeno no disco.
O que significa SQLite WAL neste contexto?
WAL significa Write-Ahead Logging. O SQLite grava primeiro as alterações em um arquivo -wal separado e, mais tarde, as consolida de volta no banco de dados principal, o que é um comportamento normal, mas pode gerar muita atividade quando inserções e exclusões ocorrem com muita frequência.
Qual foi o papel do registro TRACE?
TRACE é o nível de log mais detalhado. No exemplo relatado, o conteúdo em nível TRACE representava cerca de 70,7% dos bytes de log retidos, e a questão argumentava que logs detalhados de dependências e protocolos estavam sendo persistidos por padrão.
A OpenAI corrigiu o problema de logs do Codex?
A atualização da issue no GitHub informou que três PRs foram mesclados, com o relator estimando que eles poderiam evitar cerca de 85% dos logs com base no feedback do uso do Codex. Duas correções foram listadas como lançadas na versão 0.142.0, enquanto a terceira foi listada como planejada para a versão 0.143.0.
Os usuários devem excluir ou bloquear manualmente os logs do Codex?
Alterações manuais devem ser tratadas com cuidado, pois podem remover informações de diagnóstico e ter efeitos colaterais. Um primeiro passo mais seguro é atualizar o Codex, inspecionar os arquivos de log e monitorar os contadores de gravação do SSD se você estiver preocupado.
Isso é apenas um problema do Codex?
Este relatório específico se concentrou no Codex. No entanto, a preocupação mais ampla se aplica a agentes de IA locais em geral: ferramentas sempre ativas precisam de orçamentos de recursos claros para disco, CPU, memória, telemetria e logs retidos.
Ferramentas relacionadas
Repositório GitHub do OpenAI Codex: O repositório público do Codex CLI e do código-fonte relacionado.
SQLite: O mecanismo de banco de dados incorporado usado por muitas aplicações e ferramentas locais.
Documentação do registro Write-Ahead do SQLite: Documentação oficial que explica como o WAL funciona e por que o checkpointing é importante.
tracing do Rust: O framework de logging estruturado e diagnóstico do Rust discutido na issue do Codex.
smartmontools: Um conjunto de ferramentas para verificar dados de integridade de armazenamento SMART, incluindo contadores de gravação de SSDs em unidades compatíveis.
Hacker News: A plataforma de discussão onde o relatório de logging do Codex recebeu maior atenção dos desenvolvedores.
Links relacionados



