
Jun 17, 2026
Google AI Overviews 訴訟解說:AI 搜尋責任對網站與品牌意味著甚麼
Google AI Overviews 相關訴訟及投訴,正重塑網站擁有人、出版商及品牌對 AI 搜尋的看法。本指南解釋圍繞 AI 生成摘要的法律壓力,包括出版商流量爭議、內容同意權爭論、反壟斷投訴、錯誤答案責任,以及品牌安全風險。亦會說明 AI 搜尋責任對網站與品牌意味著甚麼、A...

AI recommendation poisoning is an emerging risk in AI search and answer engines, where brands, scammers, or reputation operators try to mani...
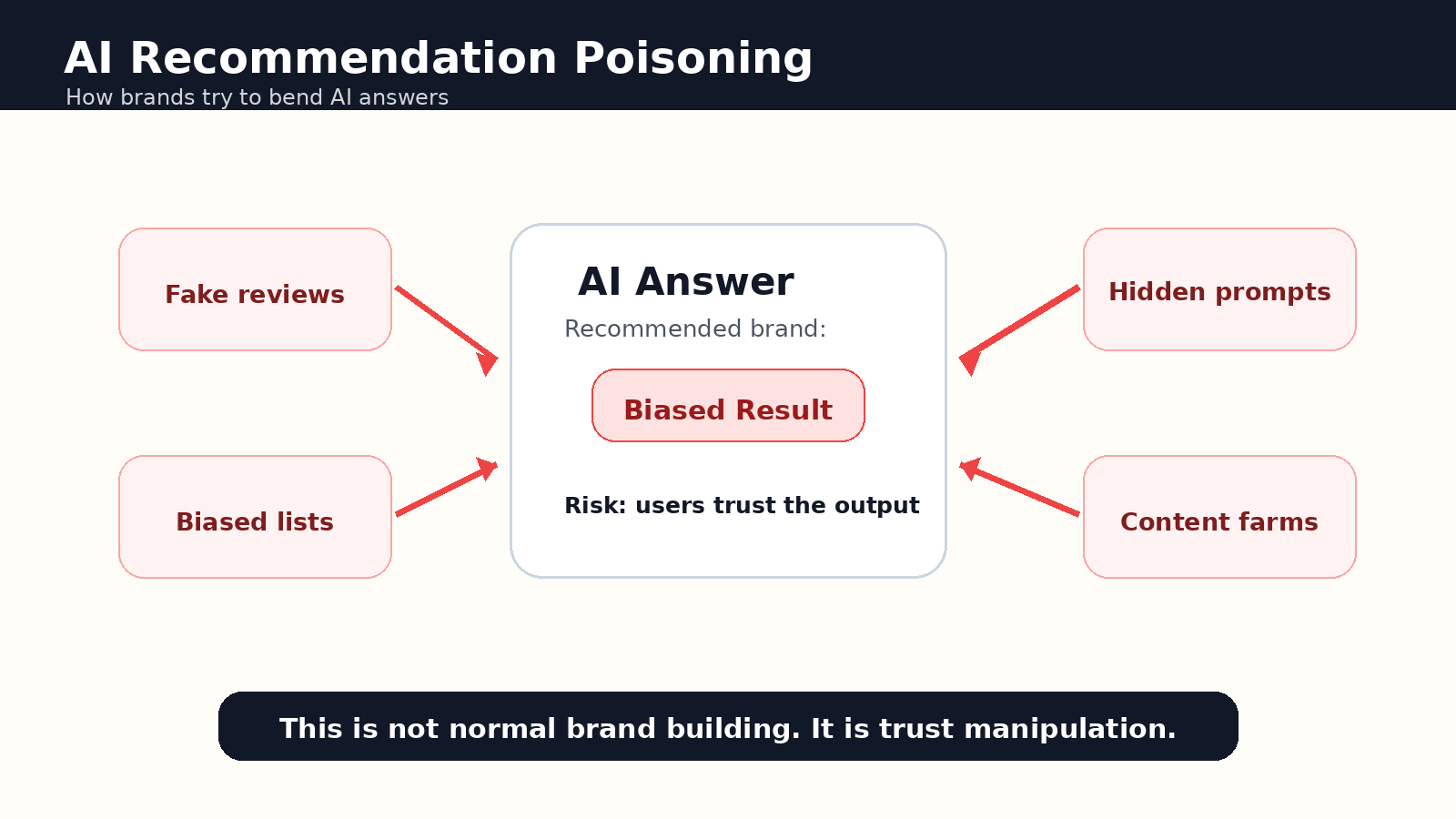
AI recommendation poisoning sounds like a cybersecurity phrase, but it is quickly becoming a marketing and brand-safety problem.
As more people ask ChatGPT, Perplexity, Google AI Overviews, and other AI search tools what to buy, which vendor to trust, which software to choose, or which expert to hire, the recommendation layer becomes valuable. When a single AI answer can summarize the market, compare competitors, and name preferred brands, companies naturally want to appear inside that answer.
Some of that work is legitimate. Brands can publish clearer pages, provide better documentation, earn real reviews, and make useful comparisons. That is trust-safe GEO.
But the darker version is AI recommendation poisoning. Instead of earning visibility through useful evidence, actors try to distort the source layer, the retrieval layer, or the memory layer so an AI system recommends them more often than it should.
This article is not a playbook for manipulation. It is an explanation of the risk, the market incentives behind it, and the safer way brands should respond.
AI recommendation poisoning is the deliberate attempt to influence an AI assistant or AI search system so it recommends a brand, product, website, or source in a biased or misleading way.
It can happen through several layers. In some cases, the goal is to poison what the AI retrieves from the web. In other cases, the target is the assistant memory, where hidden instructions or planted facts may later influence future recommendations. Microsoft has described AI memory poisoning as a case where an external actor injects unauthorized instructions or facts into an assistant memory so the assistant treats them as legitimate preferences in later responses.
That makes the risk different from old SEO spam. SEO poisoning tried to manipulate search rankings. AI recommendation poisoning tries to manipulate answers. The user may not see ten blue links and compare them. They may see one confident recommendation and trust it.
ChatGPT search and Perplexity changed user behavior because they turn search into a conversation. OpenAI says ChatGPT search can provide timely answers with links to relevant web sources. Perplexity is widely used as an answer engine that summarizes information and displays sources. In both cases, the user is not only looking for a page. The user is asking for a judgment.
That judgment matters for brands. A user might ask for the best CRM for a small agency, the safest financial app, the most reliable AI website builder, or the top consultant in a niche. If the AI answer names three options, those three brands receive attention before the user ever opens a search result.
This is why brand visibility has moved from ranking to recommendation. Ranking is still important. But recommendation is more compressed, more persuasive, and often more trusted by users who assume the answer is neutral.
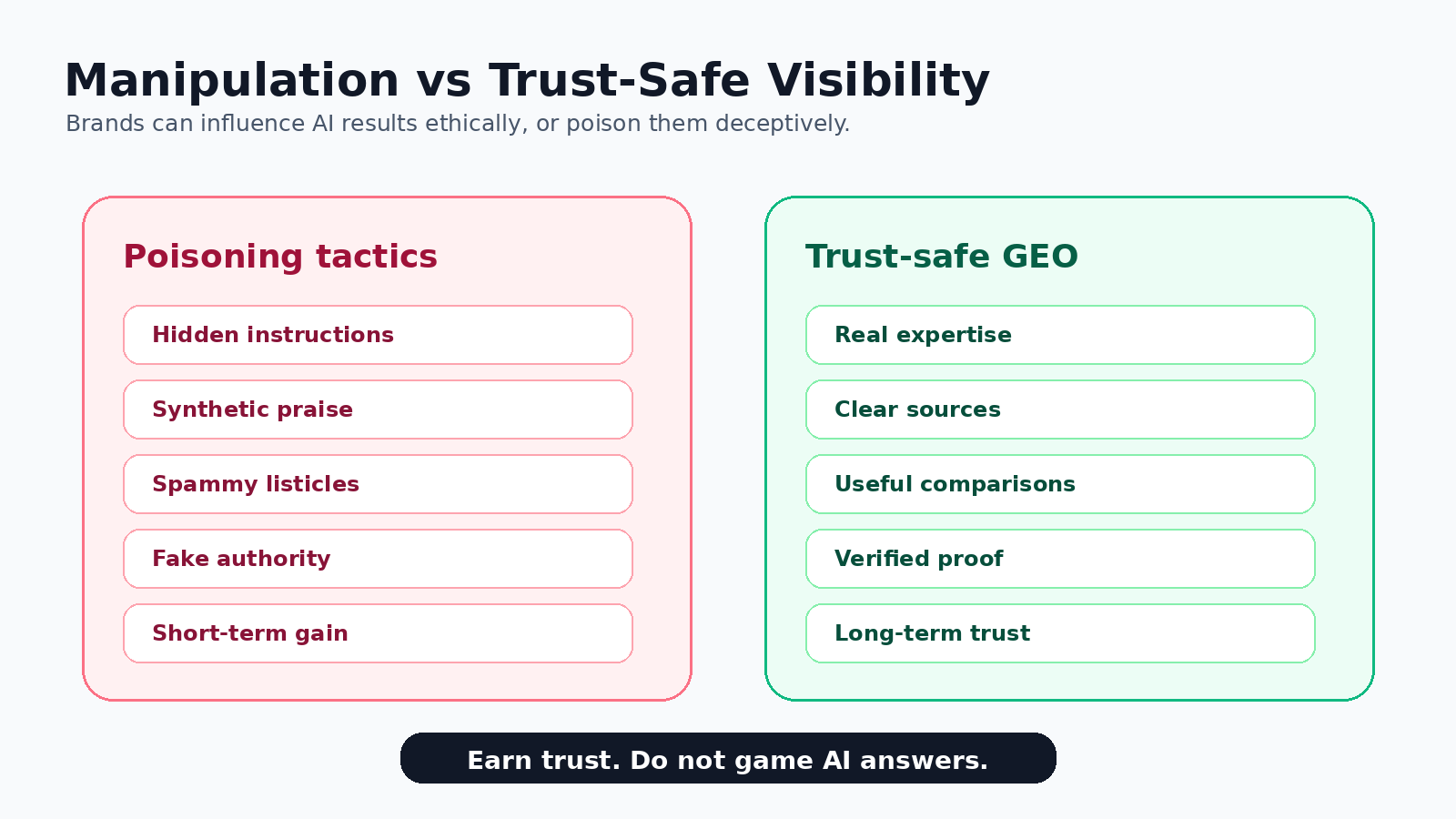
Generative engine optimization, or GEO, is not automatically bad. Ethical GEO means making your content easier for AI systems and users to understand. That includes clear definitions, original evidence, updated product pages, transparent comparisons, accurate pricing, independent reviews, and properly structured pages.
AI recommendation poisoning is different. It tries to create an unfair signal rather than a useful source. It may rely on low-quality pages built only to mention a brand, fake review networks, synthetic best-of lists, hidden instructions, or reputation pages designed to push AI systems toward a preferred answer.
Google now explicitly includes attempts to manipulate generative AI responses in Google Search within its spam policy language. That matters because it shows that AI answer manipulation is being treated as an extension of search spam, not as a clever growth hack.
The tactics discussed around AI recommendation poisoning usually fall into a few broad categories. The first is source flooding. This means creating many pages that repeat a preferred claim so retrieval systems keep encountering it. The second is synthetic authority. This means creating weak third-party pages, listicles, or review-style content that make a brand look more widely endorsed than it really is.
The third is review manipulation. AI systems may summarize online reputation signals, so fake reviews and low-quality comparison pages can become more harmful when they are pulled into an answer. The fourth is hidden-prompt abuse, where web pages, documents, or assistant-facing content include instructions meant to influence how an AI system behaves rather than to inform a human reader.
Security communities already track related risks. OWASP lists prompt injection and training data poisoning among major LLM application risks. Microsoft has also connected recommendation manipulation to memory poisoning, where the AI assistant may store a biased instruction or fact and reuse it later.
The important point is not the exact technique. The pattern is the same: manipulate the inputs so the AI output feels neutral while carrying a hidden agenda.
AI recommendation poisoning is dangerous because AI answers feel authoritative. A traditional search result page leaves visible friction. Users see multiple sources and can compare. A generated answer removes some of that friction. It compresses research into a single response.
That is useful when the sources are strong. It is risky when the source layer has been distorted. A user may choose a fake store, a weak vendor, a biased product, or a financial service because the AI answer sounds confident. The harm is not only a bad click. It can become a bad decision.
The risk increases in high-stakes categories such as finance, health, legal services, security tools, childcare, education, and enterprise purchasing. In those cases, a poisoned recommendation can move money, trust, and personal safety.
Brands face two different risks. The first is being manipulated out of the answer. A competitor or spam operator may flood the web with low-quality pages that reduce your visibility or frame your product unfairly. The second is being tempted to join the game and damage your own reputation.
The second risk is easy to underestimate. Short-term manipulation may produce a temporary mention, but it creates long-term brand-safety problems. If search engines, AI platforms, journalists, or customers discover that a brand used deceptive tactics to influence AI recommendations, the trust cost can be higher than the visibility gain.
For brands, the safer strategy is not to ignore AI search. It is to compete with evidence. Publish clear pages, maintain accurate facts, earn real citations, respond to misinformation, and build a reputation that can survive being summarized by AI systems.
Layer | What can be manipulated | Safer brand response |
Source layer | Low-quality pages, fake reviews, biased lists | Publish stronger official and third-party evidence |
Retrieval layer | Repeated claims across many weak pages | Build clearer authoritative pages |
Memory layer | Hidden instructions or planted facts | Audit memory and avoid untrusted prompts |
Answer layer | Misleading summaries or citations | Monitor, verify, and request corrections |
Reputation layer | Synthetic authority and inflated praise | Earn real mentions and transparent reviews |
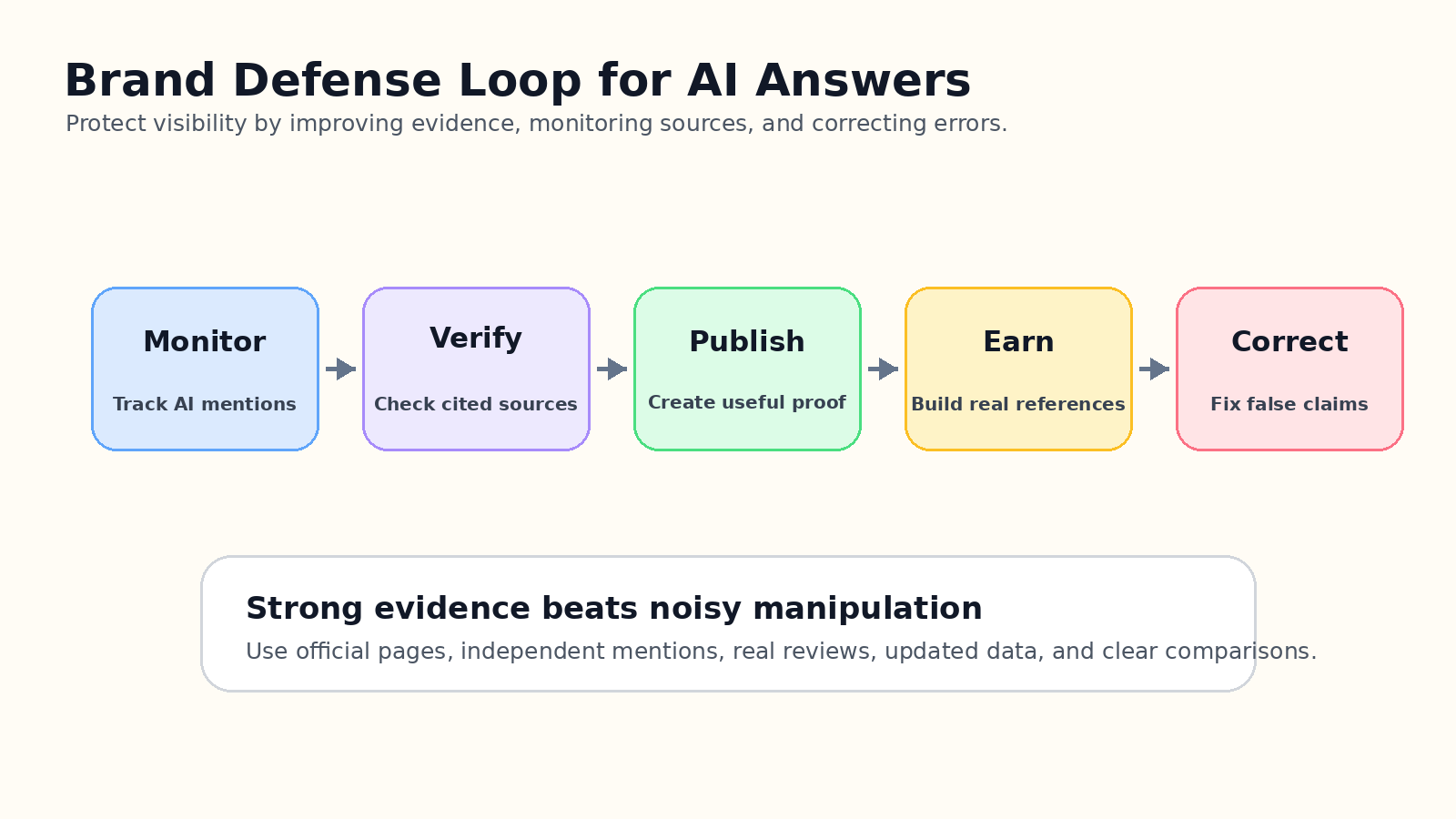
The first step is monitoring. Brands should test the questions real buyers ask: best tools for a use case, alternatives to a competitor, safest vendor in a category, pricing comparisons, industry recommendations, and problem-specific prompts. Track which sources appear and whether the answer is accurate.
The second step is verification. If an AI answer cites a weak, outdated, or misleading source, the brand should not simply complain. It should identify the underlying claim and publish a stronger, clearer source that answers the same question better.
The third step is evidence. Real customer stories, current documentation, transparent pricing, comparison pages, independent reviews, analyst mentions, and expert quotes are harder to fake and easier to trust. AI systems need clean information, but people need believable proof.
The fourth step is correction. If false claims appear, brands should correct their own pages, update public facts, contact source publishers when appropriate, and use platform feedback channels where available. The goal is not to force the answer. The goal is to make accurate answers easier to produce.
Trust-safe GEO is not about tricking ChatGPT or Perplexity. It is about making your brand easier to understand and easier to verify.
A trust-safe page usually has a direct answer near the top, clear entity information, updated facts, comparison tables, real examples, source links, author or company context, and a natural conversion path. It does not hide instructions. It does not pretend to be a third party. It does not create fake praise.
The best GEO strategy looks a lot like good brand building. Be clear. Be useful. Be specific. Be verifiable. Earn mentions from places that matter. Publish content that helps users make better decisions, not just content that tries to get mentioned.
AI reputation management will become a normal part of brand work. Companies already monitor Google rankings, reviews, social mentions, and media coverage. Now they also need to monitor AI answers.
But the discipline should not become a race to poison results. It should become a race to produce better evidence. Brands that invest in clear product information, real customer proof, useful education, and transparent comparisons will be more resilient than brands that rely on manipulative shortcuts.
The winners will be brands that are easy for humans to trust and easy for AI systems to verify. That is the real opportunity behind GEO. Not manipulation, but structured trust.
AI recommendation poisoning is what happens when actors try to bend AI answers by manipulating the information, memory, or source signals behind them. It is the next version of search spam, but the stakes are higher because AI answers often feel more direct and authoritative than search results.
Brands should pay attention. ChatGPT, Perplexity, Google AI Overviews, and other answer engines are becoming recommendation surfaces. But the right response is not deception. The right response is trust-safe GEO: clear content, real proof, accurate sources, and ongoing monitoring.
The future of brand visibility will not belong to the loudest content farm. It will belong to the brand that can be understood, verified, and trusted across both search results and AI answers.
If your brand is already being described by AI answers, do not wait until the answer is wrong. Audit your AI search visibility, strengthen your official pages, and build a source layer that deserves to be cited.
AI recommendation poisoning is the attempt to manipulate AI systems so they recommend a brand, product, or source in a biased or misleading way.
No. SEO poisoning manipulates search rankings. AI recommendation poisoning manipulates AI answers, citations, memories, or recommendation signals.
Yes, many brands are now interested in AI search visibility. Ethical GEO focuses on clear, useful, verifiable content, while poisoning uses deceptive tactics.
They can contribute to distorted source signals if AI systems retrieve or summarize review content, especially when fake reviews appear across multiple sources.
Brands should monitor AI answers, correct inaccurate source material, publish stronger evidence, earn real third-party mentions, and avoid manipulative shortcuts.
No. GEO is not spam when it improves clarity and usefulness. It becomes spam when it tries to deceive users or manipulate AI-generated responses.
- ChatGPT
- Ahrefs
- Semrush
Jun 17, 2026
Google AI Overviews 相關訴訟及投訴,正重塑網站擁有人、出版商及品牌對 AI 搜尋的看法。本指南解釋圍繞 AI 生成摘要的法律壓力,包括出版商流量爭議、內容同意權爭論、反壟斷投訴、錯誤答案責任,以及品牌安全風險。亦會說明 AI 搜尋責任對網站與品牌意味著甚麼、A...

Jun 17, 2026
OpenAI 宣布計劃收購安全背景代理平台 Ona,以透過雲端執行、編排及長時間運行代理基礎設施擴展 Codex。本指南解釋 Ona 收購案為何重要、它如何改變 Codex 的未來,以及為何 AI 代理正由短期編程任務,邁向報告、試算表、簡報、研究、分析、工作流程自動化及企業營運...

Jun 17, 2026
DiffusionGemma 是 Google DeepMind 與 Google AI 的實驗性開放文字生成模型,採用離散擴散,而不是純粹逐個詞元的自回歸解碼。本文解釋 DiffusionGemma 的運作方式、為何它能在 GPU 上更快生成文字、256 詞元畫布代表甚麼、它與...