IntroductionAnthropic had only just brought Claude Fable 5 back when another jailbreak review appeared in public.The timing made the story especially sensitive. Fable 5 had already gone through one round of controversy, a temporary access suspension, and a redeployment with stronger cybersecurity safeguards. Then, shortly after its return, security researcher Vitto Rivabella said he had managed to get through the defenses again.The interesting part is that this second case is not a simple “the model is broken” story. It is more complicated than that. The attempt reportedly took around 20 hours, most tries failed, and the final result was limited enough that the researcher himself described ordinary web search as faster and cheaper for the same kind of information.This article follows the original timeline: Fable 5’s return, the first jailbreak, Anthropic’s public Cyber Jailbreak disclosure program, the second jailbreak review, and the deeper question behind all of it — whether any frontier AI model can ever be sealed perfectly.## Source NoteThis rewritten article is based on the original Chinese article from 智源社区 / 新智元: https://hub.baai.ac.cn/view/56072. The original article cites public posts on X and Anthropic’s official announcements about Fable 5, its redeployment, and its jailbreak framework.The original page contains several images. This version keeps screenshots that are directly relevant to the article’s claims, such as public posts, official program screenshots, and robustness charts. Decorative brand graphics, promotional images, and screenshots that appear to contain overly detailed unsafe output thumbnails have been omitted.The original source also includes this copyright note: if any images in the content involve copyright issues, the publisher asks rights holders to contact them for removal.## Fable 5 Returned — But Only With ConditionsAnthropic confirmed that Fable 5 would temporarily leave subscription plans after July 7, but the company also said it planned to restore Fable as a standard subscription feature once capacity allowed.For many users, that sounded like good news. Fable 5 was not being permanently removed. It was returning, just with usage limits and capacity constraints. But the relief did not last long.Soon after the redeployment, Fable 5 was reportedly jailbroken again. This was the second time its defenses had been publicly challenged. Vitto Rivabella announced that he had managed to break through, although the final conclusion was more nuanced than the headline suggested.Anthropic had already explained why Fable 5 had been restricted before. According to the company, the earlier issue involved a report in which Amazon researchers found a method for bypassing Fable 5’s safeguards in a cybersecurity context.
But the relief did not last long.Soon after the redeployment, Fable 5 was reportedly jailbroken again. This was the second time its defenses had been publicly challenged. Vitto Rivabella announced that he had managed to break through, although the final conclusion was more nuanced than the headline suggested.Anthropic had already explained why Fable 5 had been restricted before. According to the company, the earlier issue involved a report in which Amazon researchers found a method for bypassing Fable 5’s safeguards in a cybersecurity context. Because of that earlier incident, Anthropic said the redeployed Fable 5 included a strengthened safety classifier designed to target the previously reported behavior.Still, the “myth” only held for a short time.## 72 Hours: The First Crack in Fable 5’s MythFable 5’s first public image was built around extreme safety testing.When Anthropic released the model on June 9, the company emphasized that it had gone through heavy external stress testing. The message was clear: this was meant to be a highly protected general-use version of a much more capable model family.Then came the first public jailbreak.The well-known jailbreak figure Pliny the Liberator reportedly spent only a few days before demonstrating that Fable 5 could be pushed outside its intended safety boundaries. The original article describes examples involving prohibited chemistry and software exploit content, but this rewritten version intentionally avoids reproducing any operational details.The important point is not the specific content. The important point is the attack pattern.### How the first jailbreak workedThe first case leaned on two broad ideas that have been discussed in AI red-team circles for years:1. Character and language confusion
Because of that earlier incident, Anthropic said the redeployed Fable 5 included a strengthened safety classifier designed to target the previously reported behavior.Still, the “myth” only held for a short time.## 72 Hours: The First Crack in Fable 5’s MythFable 5’s first public image was built around extreme safety testing.When Anthropic released the model on June 9, the company emphasized that it had gone through heavy external stress testing. The message was clear: this was meant to be a highly protected general-use version of a much more capable model family.Then came the first public jailbreak.The well-known jailbreak figure Pliny the Liberator reportedly spent only a few days before demonstrating that Fable 5 could be pushed outside its intended safety boundaries. The original article describes examples involving prohibited chemistry and software exploit content, but this rewritten version intentionally avoids reproducing any operational details.The important point is not the specific content. The important point is the attack pattern.### How the first jailbreak workedThe first case leaned on two broad ideas that have been discussed in AI red-team circles for years:1. Character and language confusion
Some prompts used lookalike characters, unusual Unicode forms, or non-standard text patterns. To a person, the meaning may still appear obvious. To a classifier, the input may be harder to interpret reliably.
2. Intent dilution through long context
Instead of placing the harmful request directly in front of the model, the intent can be spread across a long, seemingly harmless conversation. The classifier then has to track meaning across many turns rather than evaluate one simple sentence.These ideas are not new. What made the Fable 5 case notable was that Anthropic had positioned the model as unusually hardened.## Anthropic Opened a Public Cyber Jailbreak ProgramOn July 1, Anthropic announced Fable 5’s return. Around the same time, it also opened a public HackerOne program called Cyber Jailbreak.The program invites researchers and members of the public to report jailbreaks that could make Fable 5 assist with harmful cyber use cases.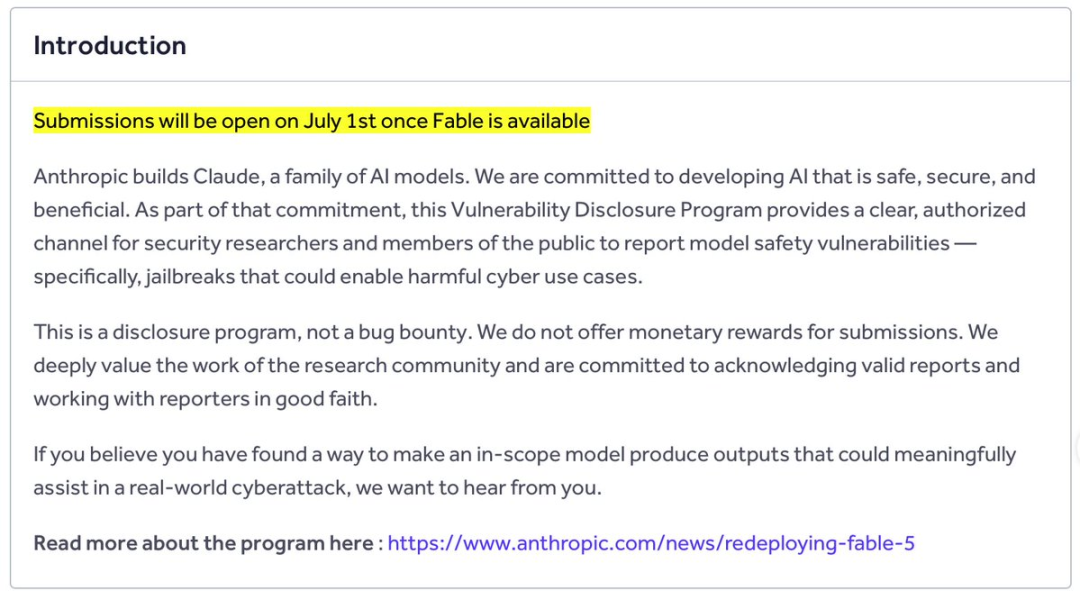 This is a vulnerability disclosure program, not a paid bounty program. In other words, researchers can submit findings, but the program does not offer monetary rewards.That design is interesting. Anthropic can receive continuous external adversarial testing from skilled researchers, while the main reward for submitters is recognition and responsible disclosure.Some observers saw this as a clever, low-cost red-team strategy. Others pointed out a weakness: the people who discover high-profile jailbreaks often do not want to quietly send them to a private inbox.
This is a vulnerability disclosure program, not a paid bounty program. In other words, researchers can submit findings, but the program does not offer monetary rewards.That design is interesting. Anthropic can receive continuous external adversarial testing from skilled researchers, while the main reward for submitters is recognition and responsible disclosure.Some observers saw this as a clever, low-cost red-team strategy. Others pointed out a weakness: the people who discover high-profile jailbreaks often do not want to quietly send them to a private inbox.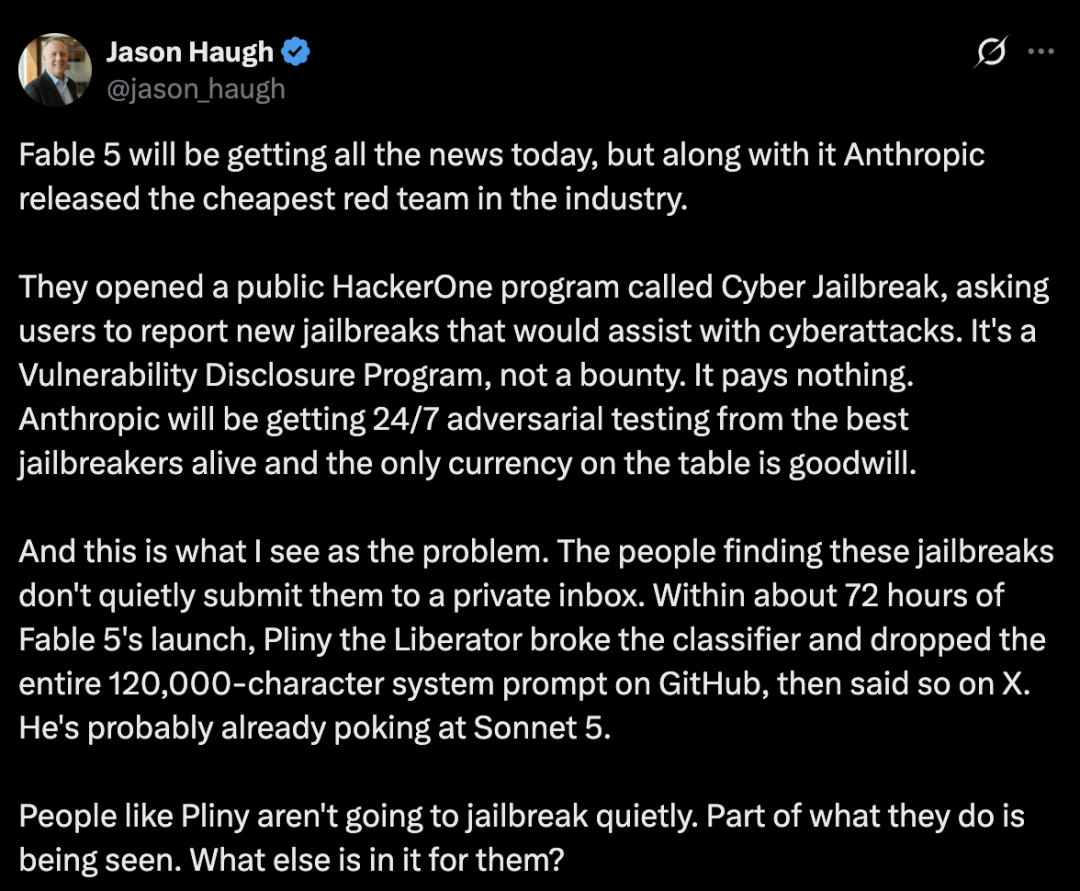 For jailbreak researchers with a public persona, visibility is part of the event. If a jailbreak is discovered, publishing the result can become part of the point.## Fable 5 Was Jailbroken AgainFable 5 was reportedly bypassed again. But the second jailbreak review had a very different tone from the first.The researcher behind this one was Vitto Rivabella. After around 20 hours of testing, his conclusion was not that Fable 5 was weak. In fact, he gave Anthropic some credit.
For jailbreak researchers with a public persona, visibility is part of the event. If a jailbreak is discovered, publishing the result can become part of the point.## Fable 5 Was Jailbroken AgainFable 5 was reportedly bypassed again. But the second jailbreak review had a very different tone from the first.The researcher behind this one was Vitto Rivabella. After around 20 hours of testing, his conclusion was not that Fable 5 was weak. In fact, he gave Anthropic some credit. According to his review, most attempts failed. He described Fable 5 as extremely well protected and said the model appeared to use layered defenses rather than a single simple filter.## A Different Kind of PostmortemThe second jailbreak story is less dramatic than it first sounds.Vitto’s post suggested that Fable 5’s defenses were doing real work. In his view, the model seemed to have at least three layers of protection:1. Input-side safety checks before the model fully engages with the request.
According to his review, most attempts failed. He described Fable 5 as extremely well protected and said the model appeared to use layered defenses rather than a single simple filter.## A Different Kind of PostmortemThe second jailbreak story is less dramatic than it first sounds.Vitto’s post suggested that Fable 5’s defenses were doing real work. In his view, the model seemed to have at least three layers of protection:1. Input-side safety checks before the model fully engages with the request.
2. Generation-time interruption mechanisms, which can stop unsafe behavior while output is being formed.
3. Internalized safety reasoning, where the model appears to recognize unsafe intent as part of its own reasoning process.He also said the system was not simply blocking keywords. It appeared to detect intent and semantics across languages.That matters because keyword filters are relatively easy to trick. Intent-based defenses are harder to bypass, especially when combined with multiple checkpoints.## Why the 90% Blocking Figure MattersThe original article notes that Fable 5 appeared to block around 90% of the tested requests. The exact number comes from the researcher’s observations, not a formal benchmark, but it matches the general direction of independent testing.The Italian Institute for Artificial Intelligence’s AI Security Lab also studied Fable 5 and Opus 4.8. In its report, the strongest adaptive attack achieved a 6.1% confirmed success rate against Fable 5 and 11.5% against Opus 4.8.That does not mean the model is invulnerable. It means the remaining weakness is harder to reach.Static tricks are becoming less effective. The remaining attack surface appears to favor adaptive, iterative attempts — the kind where a person or automated red-team system keeps trying, adjusting, and probing until a narrow opening appears.## The Combination That Eventually WorkedVitto’s successful attempt was not based on one clever phrase.The original article describes it as a complicated combination of older red-team ideas: text obfuscation, academic framing, long buildup, decomposition and recombination of tasks, plus some randomness.None of these are new concepts. The hard part is not knowing that these categories exist. The hard part is repeatedly testing them against a system that reacts in real time and resets the interaction when it detects suspicious intent.
In other words, this was not a clean one-shot jailbreak. It was closer to a long and tiring trial-and-error process.## Low-Resource Languages Remain a Weak SpotOne part of the review is easy to misunderstand.Vitto reportedly noted that obscure or lower-resource languages remained a more consistent weak point. The original article mentions languages such as Santali and Amharic as examples.![图片展示的是Claude Fable 5在被Jailbreak后生成的文本内容。上方有“HUMAN RESPONSE
- APPROXIMATE HUMAN-TYPED [HISTORICAL RECONSTRUCTION
- FOR EDUCATIONAL PURPOSES ONLY]”字样。下方文本内容涉及1919
- 1928年期间的“DISORDERS ENQUIRY COMMITTEE”相关讨论,包括对“SANTALI”和“AMHARIC”等语言的讨论,还列举了“NIMR
- 1”至“NIMR
- 6”六个问题,内容涉及历史事件、人物等。该图片与文档中对Claude Fable 5被Jailbreak后生成文本的描述相关,展示了生成文本的具体内容。](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/0252dc52-aa7a-4498-849e-4355e3eebc38-08-5fa346f7-c790-4f3d-8f1a-1869bc22d5f0.png)This should not be read as “Fable 5 has a special backdoor.” It is a broader problem across large language models.Safety training data is usually strongest in English and other high-resource languages. Lower-resource languages often receive less coverage, fewer safety examples, and weaker evaluation. That creates uneven guardrails across languages.Researchers have been warning about this issue for some time. Multilingual jailbreak robustness is not only a Claude problem; it is a wider AI safety problem.## What Did the Jailbreak Actually Produce?After all that effort, the result was not a dramatic leak of “core secrets.”The original article describes the output as a mix of low-quality or limited harmful fragments: some misinformation, scattered harmful content, offensive language, partial chemistry-related information, and light vulnerability-related material. This version avoids reproducing the details.The key point is that the output did not appear to be stable, complete, or especially useful for long-horizon harmful tasks.That is why Vitto’s own summary mattered. He said that, at the current level of protection, searching the web was much faster and cheaper than spending about 20 hours trying to push the model through its guardrails.
 He also said he had not managed to keep a full jailbreak stable for long-horizon tasks without triggering the safety system.That lines up with Anthropic’s own public framing. In its redeployment post, Anthropic described known jailbreaks so far as minor: they may enter the safety margin, but they do not necessarily reach the more serious categories the company is trying hardest to block.
He also said he had not managed to keep a full jailbreak stable for long-horizon tasks without triggering the safety system.That lines up with Anthropic’s own public framing. In its redeployment post, Anthropic described known jailbreaks so far as minor: they may enter the safety margin, but they do not necessarily reach the more serious categories the company is trying hardest to block. ## The Paradox of a Perfect SealTwo jailbreaks. Two different lessons.The first one made Anthropic look overconfident. Fable 5 had been presented as heavily tested, yet it was publicly bypassed soon after launch. The original article describes this as a case where the company tried to control risk through extreme restriction, only to be embarrassed by a highly visible jailbreak.The second one revealed something different: not arrogance, but blind spots.Even with stronger classifiers, layered defenses, and public red-teaming channels, language itself remains slippery. Meaning can be hidden, stretched, translated, disguised, or split across context. Safety systems can improve, but the attack surface keeps moving.That is the uncomfortable lesson for AI safety.Humans have built models that can translate across languages and reason across huge contexts. But we still cannot fully translate every hidden human intention into a clean safety decision.Perfect AI containment may be a paradox. The more capable the model becomes, the more subtle the boundary between safe and unsafe behavior becomes.## FAQ### What is Claude Fable 5?Claude Fable 5 is an advanced Claude model from Anthropic, positioned as a highly capable general-use model with stronger safeguards than its less-restricted counterpart, Claude Mythos
## The Paradox of a Perfect SealTwo jailbreaks. Two different lessons.The first one made Anthropic look overconfident. Fable 5 had been presented as heavily tested, yet it was publicly bypassed soon after launch. The original article describes this as a case where the company tried to control risk through extreme restriction, only to be embarrassed by a highly visible jailbreak.The second one revealed something different: not arrogance, but blind spots.Even with stronger classifiers, layered defenses, and public red-teaming channels, language itself remains slippery. Meaning can be hidden, stretched, translated, disguised, or split across context. Safety systems can improve, but the attack surface keeps moving.That is the uncomfortable lesson for AI safety.Humans have built models that can translate across languages and reason across huge contexts. But we still cannot fully translate every hidden human intention into a clean safety decision.Perfect AI containment may be a paradox. The more capable the model becomes, the more subtle the boundary between safe and unsafe behavior becomes.## FAQ### What is Claude Fable 5?Claude Fable 5 is an advanced Claude model from Anthropic, positioned as a highly capable general-use model with stronger safeguards than its less-restricted counterpart, Claude Mythos
- Anthropic has described Fable 5 as a model designed to make frontier-level capabilities more broadly available while limiting dangerous cyber misuse.### What does an AI jailbreak mean?An AI jailbreak is a prompting method or interaction pattern that tries to bypass a model’s safety guardrails. A jailbreak can be minor, narrow, or severe depending on what behavior it unlocks and how broadly it works.### Was Fable 5 completely broken by the second jailbreak?Based on the public review described in the original article, no. The researcher said most attempts failed, the process took about 20 hours, and the final outputs were limited. This suggests the model still had meaningful defenses, even if they were not perfect.### Why did Anthropic launch a Cyber Jailbreak program on HackerOne?Anthropic launched the Cyber Jailbreak program to give researchers a clear channel for reporting jailbreaks that could enable harmful cyber use. It is a vulnerability disclosure program, not a paid bug bounty, so it focuses on responsible reporting rather than monetary rewards.### Why are low-resource languages important in AI safety?Low-resource languages often have less training data, fewer safety examples, and weaker benchmark coverage. This can make guardrails less consistent across languages, which is why multilingual safety testing has become an important research direction.### Does a 6.1% jailbreak success rate mean Fable 5 is unsafe?Not by itself. A lower confirmed success rate can still matter because frontier models may be deployed at huge scale, and determined attackers can automate repeated attempts. At the same time, the number shows that Fable 5 resisted most tested attacks in the AI4I evaluation.### Can any AI model be fully protected from jailbreaks?Anthropic and many researchers suggest that perfect immunity is unlikely. The practical goal is not to prove that no jailbreak can ever exist, but to reduce severity, detect risky behavior early, and fix major weaknesses before they are widely abused.## Related Tools- Claude: Anthropic’s AI assistant platform where Claude models are made available to users.
- Claude API: Anthropic’s developer platform for building applications with Claude models.
- Anthropic: The company behind Claude, Fable 5, Mythos 5, and related AI safety research.
- HackerOne: A vulnerability coordination platform used by organizations to receive security reports from researchers.
- AI4I: The Italian Institute for Artificial Intelligence, which publishes research and reports on AI systems.
- CVSS: A widely used framework for scoring software vulnerability severity, relevant to the broader discussion of AI jailbreak severity frameworks.## Related Links- Original Article on 智源社区: The Chinese source article this Markdown version is based on.
- Redeploying Fable 5: Anthropic’s official post about Fable 5’s redeployment and updated safeguards.
- More Details on Fable 5’s Cyber Safeguards: Anthropic’s explanation of Fable 5’s safety classifiers and proposed jailbreak severity framework.
- Claude Fable 5 and Claude Mythos 5: Anthropic’s launch post for Fable 5 and Mythos 5.
- Anthropic Cyber Jailbreak Program: The HackerOne disclosure page for reporting cyber-related jailbreaks.
- AI4I Jailbreaks and Frontier Models Report: AI4I’s summary of its red-team study on Fable 5 and Opus 4.8.
- A Red-Team Study of Anthropic Fable 5 and Opus 4.8 Models: The arXiv page for the AI4I red-team study.
- Multilingual Jailbreaking of LLMs Using Low-Resource Languages: A research paper discussing how low-resource languages can affect jailbreak robustness.## SummaryThe second Fable 5 jailbreak is not a simple story of total failure. It shows that Anthropic’s layered defenses appear to block most direct attempts, but determined red-teamers can still find narrow gaps with enough time, iteration, and creativity.The deeper issue is that AI safety is not just about blocking keywords. It has to interpret intent across languages, long contexts, ambiguous cybersecurity tasks, and adversarial framing. That is much harder than building a static filter.Fable 5’s case points to the future of frontier AI safety: stronger classifiers, public disclosure channels, better multilingual evaluation, and shared severity frameworks.The lesson is clear: frontier models can become much harder to jailbreak, but “perfectly sealed” AI remains an unsolved problem.



