
Jun 27, 2026
多平台 AI 優化:品牌如何在 AI 搜尋、社群、影片及答案引擎建立能見度
AI 搜尋能見度已不再局限於單一平台。了解品牌如何在 Google AI Overviews、ChatGPT、Perplexity、YouTube、Reddit、LinkedIn 及自家網站上進行優化,並透過 We0 AI 將多平台能見度轉化為潛在客戶。

Eine klare Erklärung des Codex-SQLite-Feedback-Log-Bugs, warum eine kleine lokale Log-Datenbank dennoch enorme SSD-Schreibvorgänge verursach...
Ein kürzlich aufgetretenes Logging-Problem in Codex verwandelte eine unauffällige lokale Datenbank in einen überraschend intensiven SSD-Schreiber. Laut dem ursprünglichen GitHub-Bericht konnten die SQLite-Feedback-Logs von Codex unter dem gemeldeten Nutzungsmuster ungefähr 640 TB pro Jahr schreiben. Für eine Consumer-SSD mit einer Bewertung von etwa 600 TBW ist diese Zahl nicht nur ein kleines Durcheinander; sie liegt nahe an der garantierten Schreibausdauer des Laufwerks.
Das Merkwürdige daran ist, dass die Log-Datenbank gar nicht riesig wirkte. Die Datei konnte bei etwa einem Gigabyte liegen, während sich die tatsächlichen historischen Schreibvorgänge im Hintergrund weiter anhäuften. Genau deshalb erregte dieser Fehler so viel Aufmerksamkeit: Er füllte die Festplatte nicht auf offensichtliche Weise, konnte aber dennoch Schreibzyklen aufbrauchen.

Quellenhinweis: Dieser Artikel basiert auf dem BAAI-Hub-Repost des Berichts von Xinzhiyuan und wurde mit dem öffentlichen GitHub-Issue sowie der Diskussion auf Hacker News abgeglichen. Markenlogos, QR-Codes, Aufforderungen zum Folgen und nicht zugehörige dekorative Bilder der Originalseite wurden nicht übernommen.
Die Zahl klingt zunächst übertrieben, daher hilft es, mit der Messung zu beginnen.
Im GitHub-Issue sagte der Berichterstatter, dass die Haupt-SSD nach etwa 21 Tagen Betriebszeit rund 37 TB geschrieben hatte. Auf ein volles Jahr hochgerechnet ergibt das ungefähr 640 TB. Als mutmaßliche Hauptquelle galt die lokale SQLite-Feedback-Log-Datenbank von Codex.
Codex schrieb in Dateien unterhalb des lokalen Konfigurationsverzeichnisses:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shmDas Verhalten war nicht einfach „die Protokolldatei wächst ewig weiter“. Stattdessen sah es eher nach einer Einfügen-und-Bereinigungs-Schleife aus: Codex fügte neue Zeilen ein und löschte dann alte Zeilen, um die Anzahl der beibehaltenen Zeilen stabil zu halten. Die sichtbare Dateigröße blieb relativ ruhig, aber das Laufwerk musste dennoch die wiederholten Schreibvorgänge verarbeiten.
Eine 15-Sekunden-Stichprobe aus dem Bericht zeigte das Problem deutlich:
Metrik | Vorher | Nachher |
Beibehaltene Zeilen | 681.774 | 681.774 |
Max. Zeilen-ID | 5.003.347.015 | 5.003.383.226 |
Das bedeutet, dass etwa 36.211 Zeilen in 15 Sekunden eingefügt wurden, obwohl die Anzahl der beibehaltenen Zeilen überhaupt nicht zunahm. Von außen wirkte die Datenbank stabil, doch darunter setzte sich die Schreibaktivität fort.
Die häufigen Logeinträge waren außerdem nicht alle hochwertige Anwendungsereignisse. Die Beispiele umfassten wiederholtes Rauschen auf Dateisystem- und Abhängigkeitsebene, etwa inotify-Ereignisse:
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")Das Ergebnis war ein lokales Logging-System, das den Speicher immer wieder neu beschreiben konnte, während es den Nutzern nur sehr wenige sichtbare Anzeichen dafür gab, dass etwas Ungewöhnliches geschah.
Der kontraintuitivste Teil dieses Vorfalls ist einfach: Bei SSD-Verschleiß geht es um die gesamten Schreibvorgänge, nicht um die aktuelle Dateigröße.
Eine lokale Datenbank kann bei etwa 1 GB bleiben, während die Anwendung wiederholt Teile davon schreibt, bereinigt, indiziert, Checkpoints erstellt und neu schreibt. Aus Sicht der Speicherintegrität zählt nicht nur, wie groß die Datei heute aussieht. Entscheidend ist, wie viele Daten im Laufe der Zeit geschrieben wurden.
Metrik | Wert |
Aktuelle Dateigröße von | 1,2 GiB |
Aktuell beibehaltene Zeilen | 506.149 |
Insgesamt zugewiesene Zeilen-IDs | 5.543.677.486 |
Die aktuelle Datenbank behielt nur etwa eine halbe Million Zeilen, während die automatisch inkrementierte Zeilen-ID bereits 5,5 Milliarden überschritten hatte. Das ist der Kern der Write-Amplification-Geschichte: Alte Zeilen können aus der aktuellen Datenbankansicht verschwinden, aber die Schreibvorgänge auf die Festplatte, durch die sie erstellt wurden, haben bereits stattgefunden.
Auch SQLite’s WAL, oder Write-Ahead Logging, spielt hier eine Rolle. Im WAL-Modus werden Änderungen an eine separate -wal-Datei angehängt, bevor sie per Checkpoint zurück in die Hauptdatenbank geschrieben werden. WAL ist ein normaler und nützlicher SQLite-Mechanismus, aber wenn eine Anwendung sehr häufig Einfügungen und Löschungen durchführt, kann er die Menge der im Hintergrund stattfindenden Festplattenaktivität vervielfachen.
Einfach gesagt: Das Notizbuch sieht immer noch dünn aus, aber dieselben Seiten wurden viele Male beschrieben, gelöscht und neu beschrieben.
Der Bericht verwies auf ein besonders wichtiges Konfigurationsdetail im Protokollierungspfad von Codex:
Targets::new().with_default(Level::TRACE)Im Rust-tracing-Ökosystem wird die Protokollfilterung häufig über Targets und Levels gesteuert. Benutzer können vernünftigerweise erwarten, dass die Umgebungsvariable RUST_LOG dabei hilft, die Ausführlichkeit der Protokolle auf etwas wie info, warn oder niedriger zu reduzieren.
In diesem Pfad verwendete die SQLite-Senke für Feedback-Protokolle jedoch standardmäßig TRACE. TRACE ist die ausführlichste Stufe und kann Low-Level-Details von Abhängigkeiten, rohe Protokollaktivitäten und anderes Debugging-Rauschen erfassen. Der Problembericht argumentierte, dass diese Standardeinstellung bedeutete, dass die lokale persistente Protokolldatenbank weiterhin weit mehr speicherte, als sie sollte.
Die Verteilung der beibehaltenen Protokolle zeigte, wie dominant Inhalte auf TRACE-Ebene waren:
Stufe | Geschätzte MiB | Byte-Anteil |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
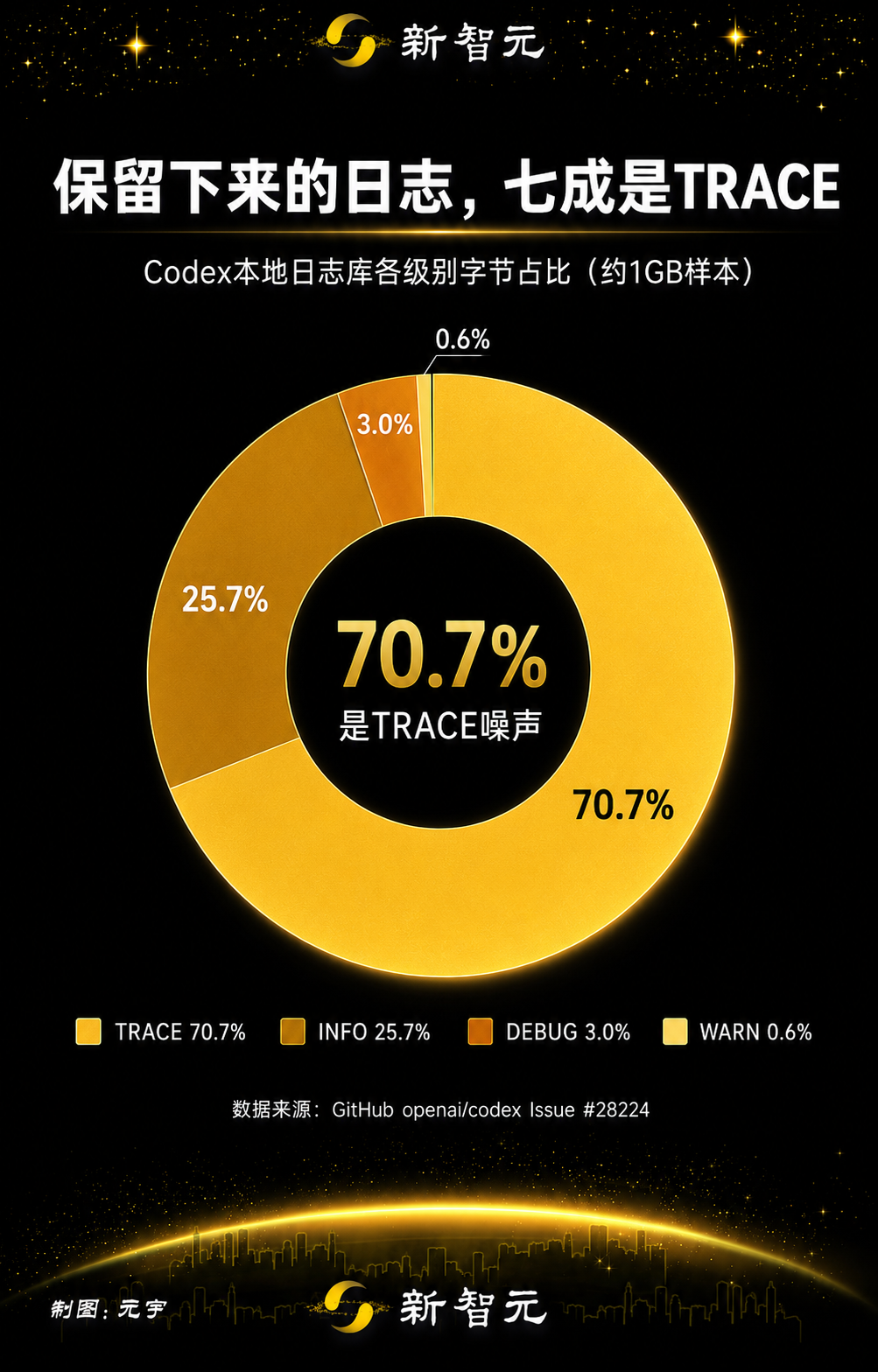
Der Bericht stellte außerdem fest, dass zwei gespiegelte, OpenTelemetry-bezogene Protokollquellen, codex_otel.log_only und codex_otel.trace_safe, einen weiteren großen Teil der beibehaltenen Protokollbytes ausmachten. In diesem Beispiel schätzte der Berichterstatter, dass das Herausfiltern dieser störenden Kategorien den Großteil des gespeicherten Protokollvolumens entfernen könnte, ohne Feedback-Protokolle vollständig zu deaktivieren.
Deshalb war der Fehler für Entwickler so frustrierend. Es ging nicht einfach nur um „Sie haben vergessen, die Protokollierung zu konfigurieren.“ Es wirkte eher wie: „Sie haben versucht, die Protokollierung zu reduzieren, aber dieser Pfad hat trotzdem weiterhin ausführliche Protokolle dauerhaft gespeichert.“
Der Bericht behandelte dies nicht als einzelnen, isolierten Vorfall. Er führte eine Reihe verwandter Codex-Probleme rund um SQLite-Protokolle, WAL-Wachstum, starke Festplattenaktivität sowie unbegrenzte oder übermäßige lokale Protokollierung auf.
Einige im Bericht erwähnte Beispiele waren:
Problem | Gemeldetes Thema |
| Übermäßige SQLite-WAL-Schreibvorgänge während des Streamings, weil TRACE-Logs |
| Wachstum von Desktop- |
| WAL-Dateien bleiben belegt oder wachsen unerwartet |
| Wachstum des Feedback-Log-SQLite ohne ausreichende Aufbewahrung oder Rotation |
| Schreibverstärkung bei einer winzigen SQLite-Datenbank |
| Starke E/A-Belastung durch inaktive Codex-Prozesse |
| 100 % aktive Datenträgerzeit unter Windows / WSL2 |
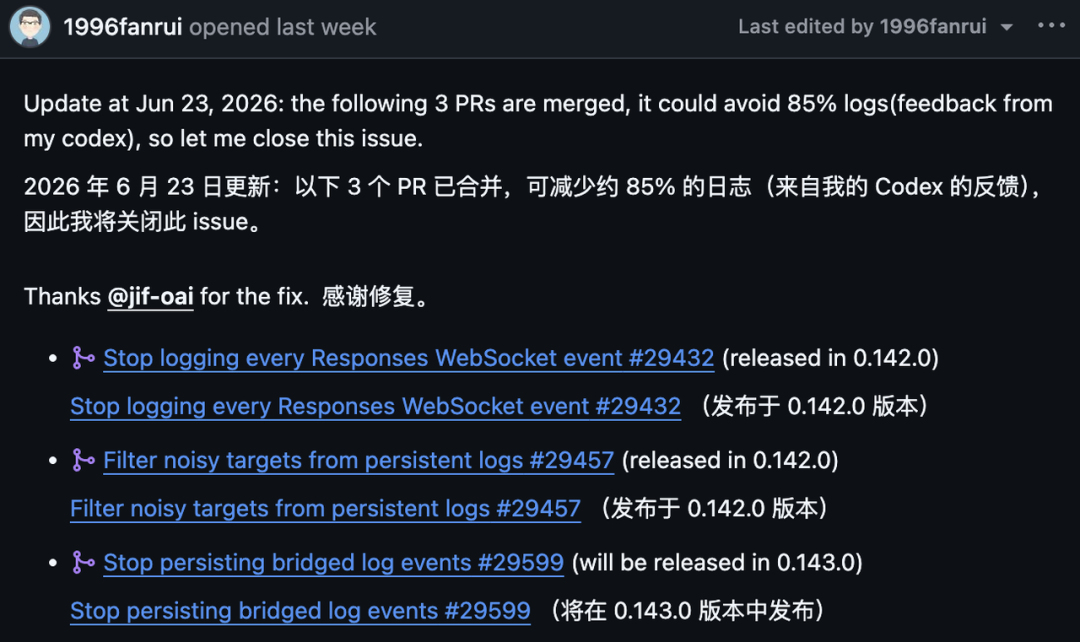
Das Issue listete die drei Korrekturen wie folgt auf:
Pull Request | Zweck | Release-Hinweis im Issue |
| Protokollierung jedes Responses-WebSocket-Ereignisses beenden | Veröffentlicht in |
| Störende Ziele aus persistenten Protokollen herausfiltern | Veröffentlicht in |
| Persistente Speicherung überbrückter Protokollereignisse beenden | Geplant für |
Eine Reduzierung um 85 % ist erheblich, aber sie ist nicht dasselbe wie der Nachweis, dass lokales Logging nun ein festes langfristiges Schreibbudget hat. Genau diese Unterscheidung ist der Grund, warum die Diskussion weiterging. Entwickler fragten nicht nur, ob dieser konkrete Fehler reduziert worden war; sie fragten, ob KI-Coding-Agenten klarere Grenzen für persistente lokale Telemetrie haben sollten.
Das GitHub-Issue enthielt außerdem einen einfachen Workaround, den ein Kommentator teilte. Er blockiert Einfügungen in die Tabelle logs, indem ein SQLite-Trigger erstellt wird:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"Verwenden Sie Workarounds wie diesen mit Vorsicht. Sie können lokale Log-Schreibvorgänge reduzieren, aber sie können auch Diagnosedaten entfernen, die Support-Teams oder Entwickler später benötigen könnten. Im Allgemeinen ist es sicherer, auf eine behobene Version zu aktualisieren und das aktuelle Log-Verhalten zu überprüfen, als eine Anwendungsdatenbank stillschweigend zu ändern, ohne die Abwägungen zu verstehen.
Die Diskussion ging schnell über Codex allein hinaus. Auf Hacker News brachten Entwickler auch allgemeinere Beschwerden über KI-Coding-Tools vor: hohe GPU-Auslastung, hoher Speicherverbrauch, Hintergrundaktivität und große lokale Debug-Logs.

Ein Tool kann sich in der Benutzeroberfläche „in Ordnung“ anfühlen und dennoch im Hintergrund still Ressourcen verbrauchen. Schnelle CPUs, großer Arbeitsspeicher und moderne NVMe-Laufwerke können Probleme lange verbergen. Die App friert möglicherweise nicht ein. Die Festplatte läuft vielleicht nicht voll. Das Terminal reagiert womöglich weiterhin. Doch die Zustandszähler der Hardware können eine andere Geschichte erzählen.
Deshalb wurde dieser Vorfall zu einer nützlichen Fallstudie für KI-Entwicklertools. Die Modellfähigkeit ist wichtig, aber die lokale Betriebsqualität ebenfalls. Ein Coding-Agent, der auf dem Rechner eines Entwicklers läuft, braucht vernünftige Standardeinstellungen, Aufbewahrungsgrenzen, Log-Rotation und eine Möglichkeit für Nutzer, zu verstehen, was er tut.
Es handelte sich um ein gemeldetes Codex-Protokollierungsproblem, bei dem lokale SQLite-Feedback-Logs sehr große Mengen an Schreibvorgängen auf dem Datenträger erzeugen konnten. Der GitHub-Bericht schätzte bei dem vom Melder gemessenen Nutzungsmuster etwa 640 TB Schreibvorgänge pro Jahr.
logs_2.sqlite-Datei trotzdem eine SSD abnutzen?WAL steht für Write-Ahead Logging. SQLite schreibt Änderungen zunächst in eine separate -wal-Datei und überträgt sie später per Checkpoint zurück in die Hauptdatenbank. Das ist normales Verhalten, kann jedoch viel Aktivität verursachen, wenn Einfügungen und Löschungen sehr häufig stattfinden.
TRACE ist die ausführlichste Protokollstufe. In der gemeldeten Stichprobe machten Inhalte auf TRACE-Ebene etwa 70,7 % der beibehaltenen Protokollbytes aus, und in dem Issue wurde argumentiert, dass ausführliche Abhängigkeits- und Protokoll-Logs standardmäßig dauerhaft gespeichert wurden.
Im Update des GitHub-Issues hieß es, dass drei PRs zusammengeführt wurden, wobei der Melder schätzte, dass auf Grundlage der Rückmeldungen aus seiner Codex-Nutzung etwa 85 % der Logs vermieden werden könnten. Zwei Korrekturen wurden als in 0.142.0 veröffentlicht aufgeführt, während die dritte als für 0.143.0 geplant angegeben wurde.
Dieser konkrete Bericht konzentrierte sich auf Codex. Das umfassendere Anliegen gilt jedoch für lokale KI-Agenten im Allgemeinen: Ständig aktive Tools benötigen klare Ressourcenbudgets für Festplatte, CPU, Arbeitsspeicher, Telemetrie und aufbewahrte Logs.
OpenAI Codex GitHub-Repository: Das öffentliche Repository für Codex CLI und den zugehörigen Quellcode.
SQLite: Die eingebettete Datenbank-Engine, die von vielen lokalen Anwendungen und Tools verwendet wird.
SQLite-Dokumentation zu Write-Ahead Logging: Offizielle Dokumentation, die erklärt, wie WAL funktioniert und warum Checkpointing wichtig ist.
Rust tracing: Das im Codex-Issue besprochene Rust-Framework für strukturiertes Logging und Diagnostik.
smartmontools: Eine Tool-Sammlung zur Überprüfung von SMART-Gesundheitsdaten von Speichermedien, einschließlich SSD-Schreibzählern auf unterstützten Laufwerken.
Hacker News: Die Diskussionsplattform, auf der der Codex-Logging-Bericht größere Aufmerksamkeit unter Entwicklern erregte.
Codex SQLite-Feedback-Protokolle, Issue #28224: Das zentrale GitHub-Issue, das die gemeldete Schreibschätzung von 640 TB/Jahr und die Belege dokumentiert.
Protokollierung jedes Responses-WebSocket-Ereignisses stoppen #29432: Einer der zusammengeführten PRs, die als Teil der Arbeit zur Reduzierung der Protokollierung aufgeführt sind.
Störende Ziele aus persistenten Protokollen filtern #29457: Der PR konzentrierte sich darauf, störende Ziele der persistenten Protokollierung herauszufiltern.
Persistierung überbrückter Protokollereignisse stoppen #29599: Der Folge-PR zielte darauf ab, die Persistierung überbrückter Abhängigkeits-Protokollereignisse zu stoppen.
Hacker-News-Diskussion: Community-Diskussion über Codex-Protokollierung, SSD-Schreibvorgänge und die Qualität von KI-Coding-Tools.
OpenAI Codex CLI README: Offizielle README des Repositorys zur Installation und Ausführung der Codex CLI.
SQLite-WAL-Dokumentation: Offizielle Erklärung zu WAL-Dateien, Checkpoints und Leistungsaspekten.
Jun 27, 2026
AI 搜尋能見度已不再局限於單一平台。了解品牌如何在 Google AI Overviews、ChatGPT、Perplexity、YouTube、Reddit、LinkedIn 及自家網站上進行優化,並透過 We0 AI 將多平台能見度轉化為潛在客戶。

Jun 27, 2026
E-E-A-T 已不再只是 SEO 的質素概念。在 AI 搜尋年代,經驗、專業知識、權威性與信任,已成為被理解、引用、排名及選擇的基準。了解如何透過 We0 AI 將你的網站轉化為具可信度的增長資產。

Jun 27, 2026
零點擊搜尋正成為預設的搜尋體驗。本文說明為何點擊量正在減少、為何能見度仍然重要,以及品牌如何透過 We0 AI 建立一個支援 SEO、GEO、內容增長及潛在客戶開發的網站。