
핵심 요약
Gemini 3.5 Flash에서 가장 비용이 많이 드는 실수는 문법 오류가 아니라 조용한 기본값입니다.
많은 코딩 에이전트에서
low는 사람들이 예상하는 것보다 더 나은 기본값입니다.GitHub Copilot을 통한 무거운 에이전트 루프는 14배 계량 때문에 훨씬 더 비싸질 수 있습니다.
We0 AI에서 모델 선택은 워크플로의 일부일 뿐입니다. 나머지는 제품이 어떻게 설명되고, 노출되며, 발견되는가에 달려 있습니다.
gemini-3.5-flash는 호출하기 쉬워 보입니다.
바로 그렇기 때문에 과소평가하기 쉽습니다. 프리뷰 시절 코드에서 작은 마이그레이션만 해도 눈에 보이는 오류 하나 없이 더 나쁜 출력, 다른 비용 구조, 더 비싼 멀티턴 루프를 초래할 수 있습니다.
이 가이드는 가장 중요한 세 가지 함정, 이를 피하는 코드 형태, 그리고 빠르게 적용할 수 있는 실용적인 MCP 스타일 에이전트 루프에 초점을 맞춥니다.
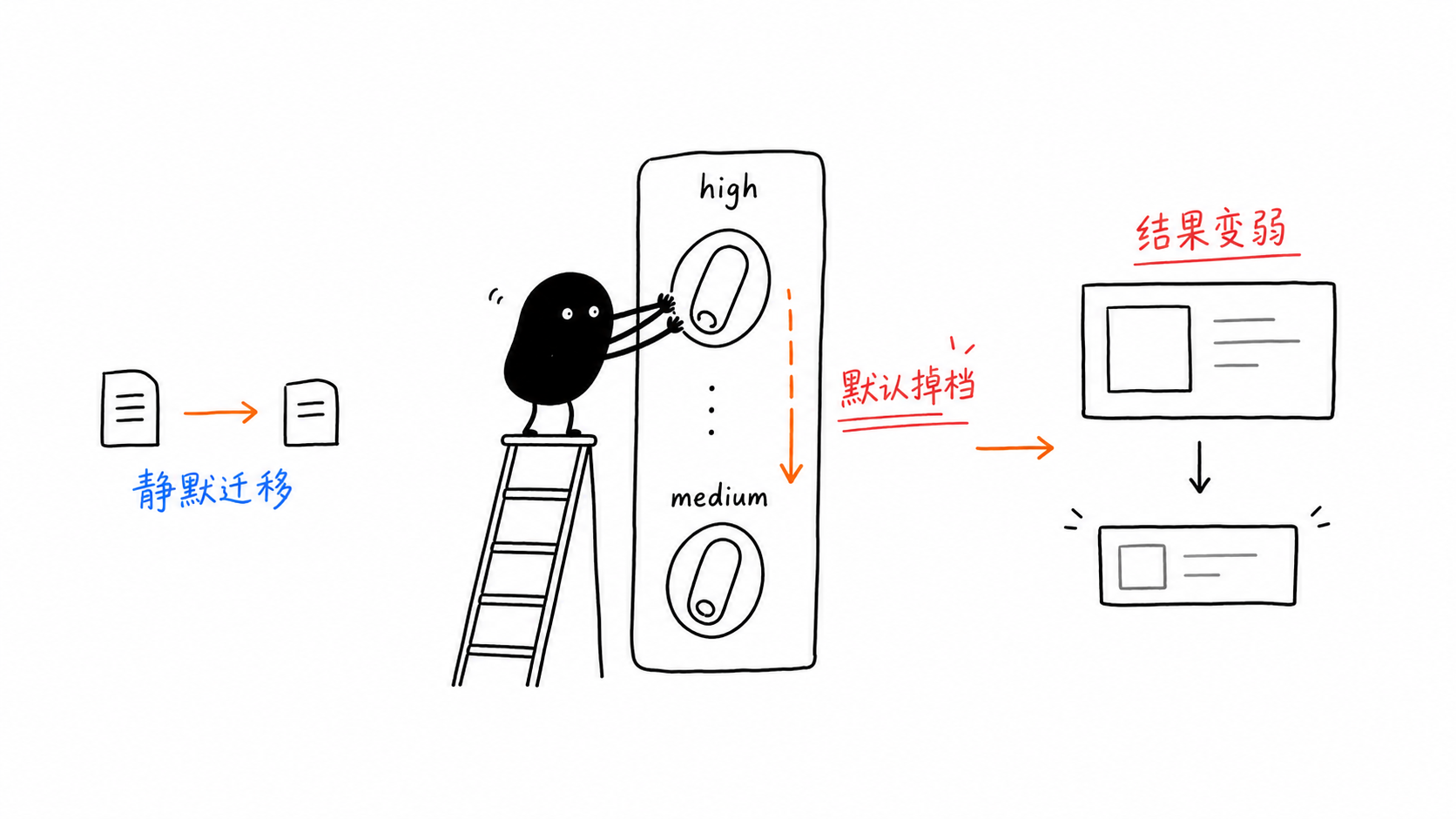
함정 1: thinking_level 기본값이 High에서 Medium으로 내려갔습니다
이것이 위험한 이유는 아무것도 크래시되지 않기 때문입니다.
예전 코드를 그대로 옮겨도 요청은 여전히 반환되지만, 모델은 더 이상 당신이 가정한 수준으로 추론하지 않습니다.
이전과 현재의 사고방식 비교
값
역할
사용 시점
minimal
최소한의 추론
자동완성, 분류, 단발성 완성
low
코드 및 에이전트형 작업에 맞게 재조정됨
코딩 에이전트, MCP 도구 루프, 다단계 워크플로
medium
새 기본값 — 균형형
일반 소비자용 채팅, 범용 Q&A
high
최대 추론 노력
고난도 추론, 새로운 문제 디버깅, 수학, 계획 수립
쉽게 하는 실수
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)두 번째 스니펫은 실행되지만, 기본값은 더 이상 같지 않습니다.
더 안전한 마이그레이션
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)직관에 반하는 권장사항
많은 코딩 에이전트 워크플로에서는 high가 아니라 low로 시작하세요.
실용적인 이유는 단순합니다:
더 빠름
더 저렴함
도구 중심의 코딩 루프에서는 종종 충분히 좋거나 비슷한 성능을 냄
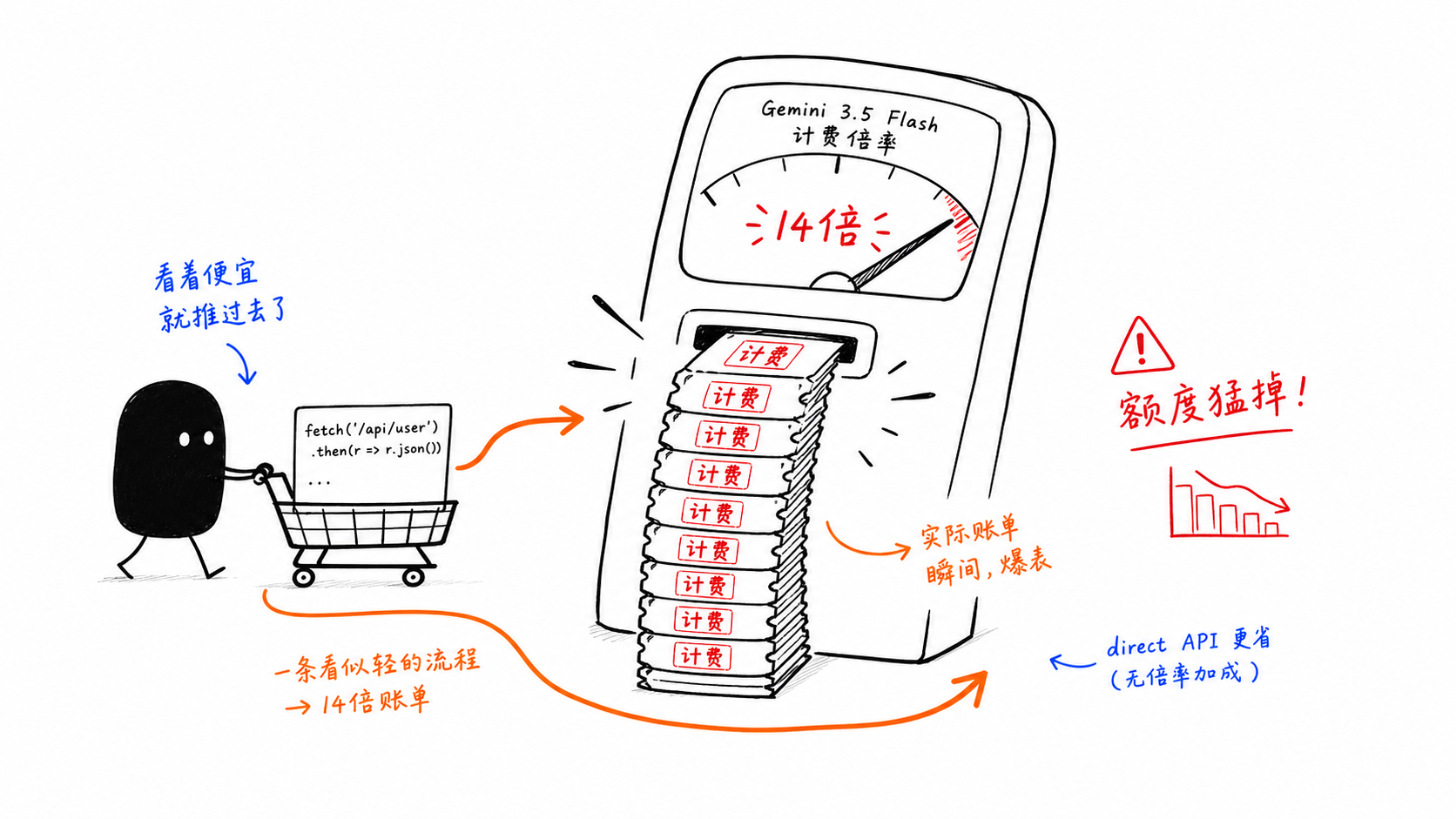
함정 2: GitHub Copilot은 Gemini 3.5 Flash를 14배로 과금합니다
이것이 이 글에서 가장 비용이 큰 함정입니다.
문제는 모델의 정가가 아닙니다. GitHub Copilot 내부의 프리미엄 요청 배수입니다. Flash가 에이전트 방식으로 사용되기 시작하면 비용 구조는 빠르게 바뀝니다.
그래서 많은 팀이 경로를 분리합니다:
가벼운 상호작용 사용은 Copilot 내부에 유지
무거운 루프와 배치형 워크플로는 직접 API를 통해 처리
아키텍처가 곧 비용 통제가 됩니다.
함정 3: 사고 보존이 멀티턴 토큰 비용을 자동으로 부풀립니다
Gemini 3.5 Flash는 턴 간에 내부 추론을 이어서 유지합니다.
이는 일관성을 높여주지만, 그 생각들이 이후 토큰 계산에도 계속 포함될 수 있음을 의미합니다.
긴 에이전트 루프에서는 이것이 토큰 사용량을 상당히 끌어올릴 수 있습니다.
실용적인 완화 방법
명확한 단계 경계에서 채팅을 초기화하기
중요한 내용만 요약해서 이어가기
안정적인 지침과 도구 정의에는 프롬프트 캐싱 사용하기
시간이 지남에 따라 사고 토큰과 프롬프트 토큰의 비율을 관찰하기
Gemini 3.5 Flash에서 동작하는 MCP 에이전트
원문에는 매우 유용한 엔드투엔드 패턴이 포함되어 있습니다. 파일 읽기 도구 하나, URL 가져오기 도구 하나, 표준 함수 선언 형식, 그리고 도구 응답을 다시 모델로 보내는 루프입니다.
도구 정의
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)에이전트 루프 패턴
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
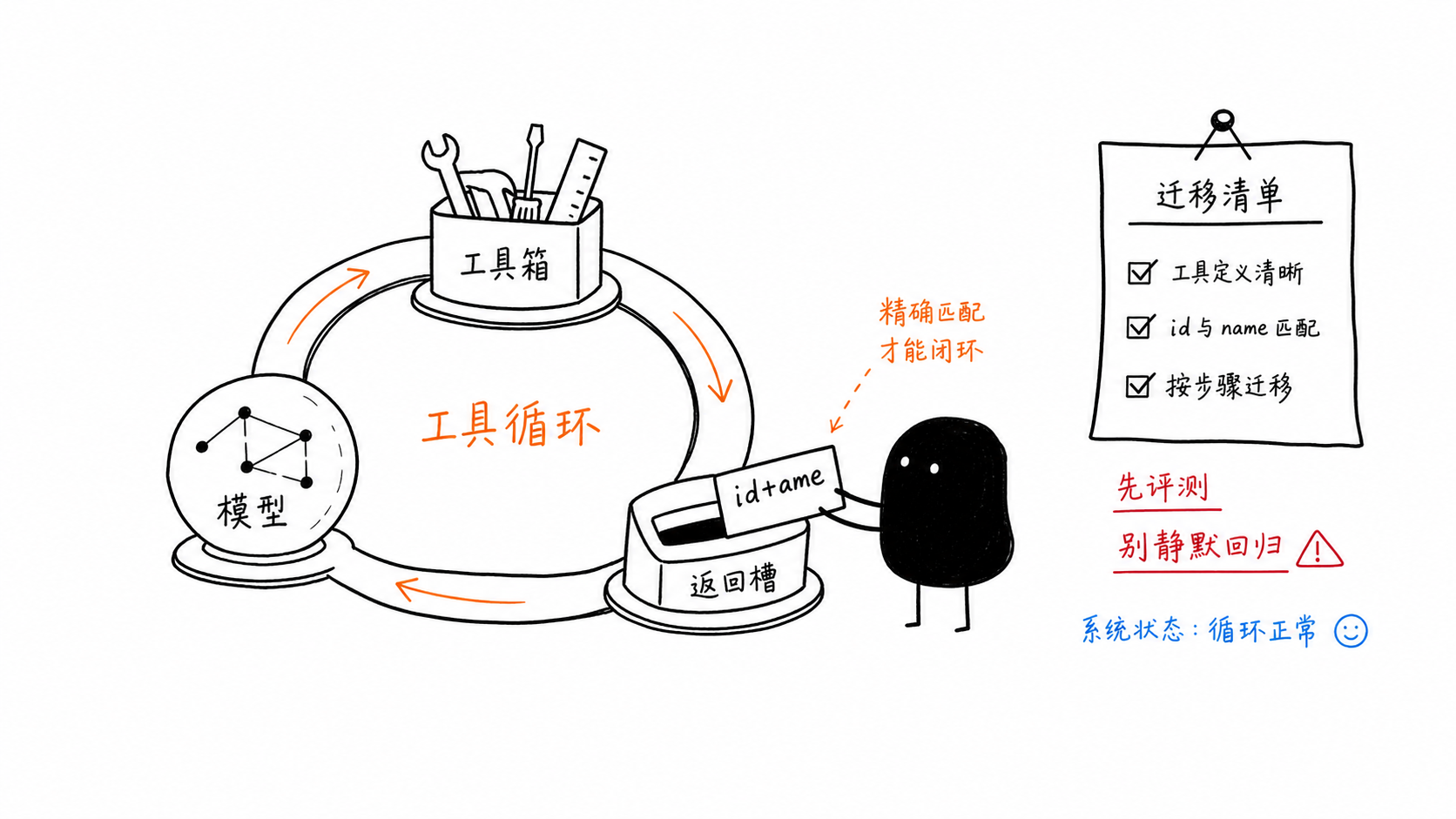
history.append(types.Content(role="tool", parts=tool_results))작지만 매우 중요한 마이그레이션 규칙은 함수 응답이 원래 호출의 id와 name 모두와 일치해야 한다는 점입니다.
대신 Antigravity를 선택해야 할 때
프로토타입에서는 수동으로 도구 루프를 만드는 것으로 충분합니다. 하지만 프로덕션에 들어가면 오케스트레이션, 캐싱, 라우팅, 재시도, 관측성을 곧 직접 다시 구현하게 됩니다.
그래서 더 중요한 질문은 단지 “이 모델을 연결할 수 있는가”가 아니라, “내가 직접 얼마나 많은 에이전트 인프라를 떠안게 될 것인가”입니다.
빠른 마이그레이션 체크리스트
gemini-3-flash-preview에서 gemini-3.5-flash로 이동한다면, 다음 항목을 명시적으로 확인하세요:
모델 ID를 신중하게 교체하기
thinking_level을 의도적으로 설정하기평가 결과로 정당화되지 않는 한 오래된 샘플링 오버라이드는 제거하기
도구 응답에서 id와 name 일치시키기
response.usage_metadata.thoughts_token_count검사하기여전히 의존하는 미지원 API에는 preview 유지하기
전후 평가 실행하기
Copilot 과금과 직접 API 비용 비교하기
도구와 함께 Gemini 3.5 Flash 사용해 보기
목표가 단순히 프롬프트를 테스트하는 것만이 아니라 파일, 리포지토리, API, 문서, 에이전트 워크플로를 함께 연결하는 것이라면, 보통은 단순한 모델 엔드포인트만으로는 부족합니다.
We0 AI에서는 이와 같은 원칙이 한 단계 더 확장됩니다. 에이전트 워크플로는 전체 작업의 절반에 불과합니다. 나머지는 문서, FAQ, 제품 페이지, 쇼케이스 콘텐츠, SEO / GEO 접점을 통해 제품을 이해하기 쉽고, 검색 가능하며, 추천 가능하고, 전환 가능하게 만드는 일입니다.
FAQ
Python에서 Gemini 3.5 Flash를 어떻게 호출하나요?
호출 자체는 짧습니다. 중요한 부분은 마이그레이션 중 출력 품질이 조용히 저하되지 않도록 thinking_level을 명시적으로 설정하는 것입니다.
thinking_level 값에는 무엇이 있나요?
매우 가벼운 작업용
minimal코딩 및 에이전트형 워크플로용
low소비자 스타일 기본값인
medium더 어려운 추론과 더 깊은 계획을 위한
high
GitHub Copilot 내부에서 Gemini 3.5 Flash 비용이 더 비싼 이유는 무엇인가요?
과금 배수가 경제성을 바꾸기 때문입니다. 에이전트를 많이 사용하는 경우, 기본 모델 가격보다 이것이 비용 구조에 더 큰 영향을 줄 수 있습니다.
사고 보존(thought preservation)이란 무엇인가요?
이는 모델이 여러 턴에 걸쳐 내부 추론을 이어가는 것을 의미합니다. 이는 멀티턴 일관성에 도움이 되지만, 시간이 지날수록 토큰 비용이 증가할 가능성도 높입니다.
Gemini 3.5 Flash는 MCP에 적합한가요?
네, 특히 도구 스키마, 응답 매칭, thinking_level, 그리고 토큰 예산 관리가 세심하게 처리될 때 그렇습니다.


