
Introduction
If you have been hearing people talk about “Loop Engineering” but still feel unsure where to start, this guide gives you a practical entry point.
Instead of repeatedly writing prompts and checking every step by hand, a loop lets an AI agent work toward a small goal on a schedule. The system can assign the task, read the current state, run the agent, verify the result, and bring a human back in when judgment is needed.
The original report introduced an open-source Loop Engineering framework by Cobus Greyling. At the time of the report, the project had gained around 4.5k GitHub stars. The repository may show a different star count now because it has continued to grow.
In short: the point is no longer only to write better prompts. The point is to design a reliable loop that can prompt, check, and iterate with clear boundaries.

What Is Loop Engineering?
Loop Engineering is a way to design repeatable AI agent workflows. A loop is not just one prompt. It is a small operating system around an agent: it defines when the agent runs, what context it reads, what it is allowed to change, how the result is checked, and when a human needs to review the outcome.
A typical loop can be used for tasks such as:
- daily project triage;
- watching pull requests;
- cleaning up CI failures;
- scanning dependencies;
- sorting issues;
- cleaning up after merges;
- drafting changelogs.
These are not always difficult tasks, but they are repetitive. They require attention, context, and a consistent standard. That is exactly the kind of work where a well-designed loop can help.
Why This Framework Is Getting Attention
The open-source framework described in the original article brings together practical loop patterns, starter templates, and command-line tools. It is designed for AI coding agents and supports workflows around tools such as Claude Code, Codex, Grok, and OpenCode.
The framework includes:
- seven ready-to-use loop patterns;
- starter templates for common scenarios;
loop-initfor scaffolding a loop;loop-costfor estimating token cost;loop-auditfor checking loop readiness;- state and budget files for longer-running workflows;
- support for safer human review and phased rollout.
The core message is simple:
Stop prompting. Design the loop.
That does not mean prompts disappear. It means prompts become part of a larger system that can repeat work, track state, and verify results.
Start Fast: One Command
The fastest way to begin is to run loop-init inside a Git project.
Note: some reposted versions of the original article display command-line flags with a long dash. In a real terminal, use the standard double hyphen
--shown below.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
This command scaffolds the loop structure in your current project. You can replace claude with another supported tool such as grok, codex, or opencode, depending on the workflow you want to test.
The daily-triage pattern is a good starting point for beginners because it is lower risk than high-frequency automation. It focuses on scanning the current project state and producing a report before allowing any automatic changes.
Beginner-Friendly Loop Tutorial
Loop Engineering may sound abstract at first, but the framework breaks it down into a few concrete building blocks.
The Five Building Blocks Plus Memory
At a basic level, a loop is built from five main parts, plus memory and state.
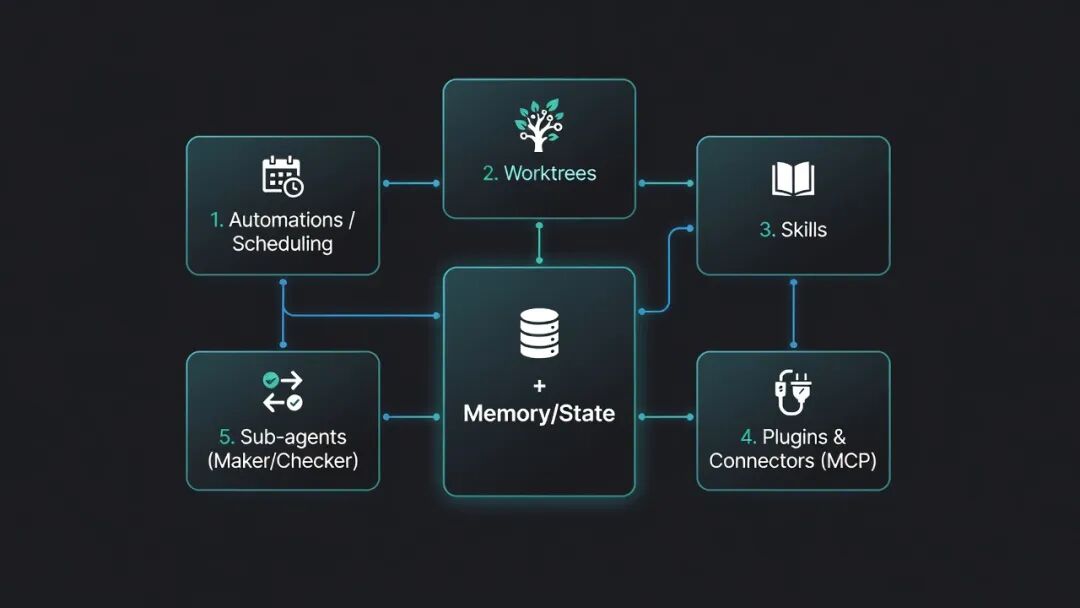
| Building Block | What It Does in the Loop |
|---|---|
| Automation / Scheduling | Runs the loop on a cadence, such as daily, hourly, or every few minutes. |
| Worktrees | Creates isolated working environments so multiple agents do not overwrite each other. |
| Skills | Stores reusable project knowledge, rules, and task instructions. |
| Plugins & Connectors | Connects the loop to real tools through systems such as MCP, GitHub, Linear, or Slack. |
| Sub-agents | Separates the maker role from the checker role so the same agent does not approve its own work. |
| Memory / State | Keeps durable context outside the chat, usually through files such as STATE.md. |
This structure makes the loop easier to reason about. You are not asking the model to “just handle everything.” You are giving it a defined environment, a schedule, a state file, a verification path, and a human handoff rule.
Seven Ready-to-Use Production Patterns
The framework also includes seven production-oriented patterns. Each pattern has a different cadence, risk level, and best use case.

| Pattern | Typical Use Case | Suggested Starting Mode |
|---|---|---|
| Daily Triage | Scan project status, issues, CI, and commits. | L1 report-only |
| PR Babysitter | Watch pull requests through review, CI, rebase, and merge. | L1 watch |
| CI Sweeper | Watch failing checks and propose or apply small fixes. | L2 cautious |
| Dependency Sweeper | Check stale dependencies and security updates. | L2 patch-only |
| Issue Triage | Deduplicate, score, and label incoming issues. | L1 propose-only |
| Post-Merge Cleanup | Clean TODOs, minor debt, and follow-up work after merges. | L1 off-peak |
| Changelog Drafter | Draft release notes from commits and merged changes. | L1 draft |
The practical advice is to start with a low-risk loop. Daily triage is usually easier to trust because it does not need to change code immediately.
Interactive Pattern Picker
The project also provides an interactive picker. Instead of choosing a pattern manually, you can start from a pain point such as “PRs keep getting stuck,” “CI keeps failing,” or “issues are too noisy.”
The picker then recommends a loop pattern and gives you a starting command. This is useful when you know the problem but are not sure which loop should handle it.
Run Your First Loop
Here is a beginner-friendly way to run the first loop while keeping risk under control.
Step 1: Choose a Pattern
Start with daily-triage if this is your first time. It is a low-risk pattern and a good way to understand how the loop reads project state, writes notes, and prepares work for a human.
Step 2: Scaffold the Loop
Run the initialization command in the root directory of your Git project.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
You can swap the tool name if you are using a different AI coding agent.
npx @cobusgreyling/loop-init . --pattern daily-triage --tool grok
npx @cobusgreyling/loop-init . --pattern daily-triage --tool codex
npx @cobusgreyling/loop-init . --pattern daily-triage --tool opencode
You can also replace daily-triage with another supported pattern once you understand the basic flow.
Step 3: Estimate Token Cost
High-frequency loops can consume a lot of tokens, especially if they use sub-agents, long context, or repeated verification. Estimate the cost before you run a loop too often.
npx @cobusgreyling/loop-cost --pattern daily-triage --level L1
For early testing, keep the loop at L1 and avoid aggressive schedules.
Step 4: Audit Loop Readiness
Before trusting the loop, run an audit. The audit gives the project a readiness score from 0 to 100 and suggests improvements.
npx @cobusgreyling/loop-audit . --suggest
If your project is not ready, fix the missing pieces first. Common gaps include no state file, no verification step, unclear scope, missing budget limits, or weak human handoff rules.
If the project reaches a good readiness level, you can also generate a Loop Ready badge for your README.
npx @cobusgreyling/loop-audit . --badge
Step 5: Start in Report-Only Mode
幾分鐘搭建展示站並增長獲客
輸入一句想法,We0 AI 即可生成展示站、頁面與 CMS。發佈上線後並幫你獲取客戶和流量。
Do not let the loop modify production code on day one. Start with report-only mode, then review the output manually.
For a Grok-style loop command, the first run can look like this:
/loop 1d Run loop-triage. Update STATE.md. No auto-fix in week one.
This tells the loop to triage, write state, and avoid automatic fixes during the first week.
Step 6: Read the Output
Open STATE.md and check what the loop found. This file acts as memory outside the conversation. It should show what the loop saw, what it did, what it skipped, and what needs human attention.
If the output is noisy or wrong, adjust the loop before increasing autonomy. A useful loop should become boring, predictable, and inspectable.
Loop Maturity: L1 to L3
Loop Engineering should be rolled out gradually. The maturity levels help you avoid giving too much freedom too early.
| Level | Meaning | Recommended Use |
|---|---|---|
| L1 | The loop reports findings and updates state, but does not change code. | Best for first runs and low-risk adoption. |
| L2 | The loop can make small changes with a verifier and human review. | Useful after the team trusts the loop’s output. |
| L3 | The loop can run for longer periods with limited unattended execution. | Only suitable when scope, safety, cost, and verification are mature. |
A good first goal is not full autonomy. A good first goal is a reliable L1 loop that gives you useful information without creating extra cleanup work.
The Standard Loop Process
A complete loop has a clear sequence. The original article described it as an eight-step process:
- scheduled trigger;
- task triage;
- read current state;
- create an isolated workspace;
- let the agent execute;
- run verifier checks;
- connect to Git or ticket systems;
- ask for human confirmation when needed.
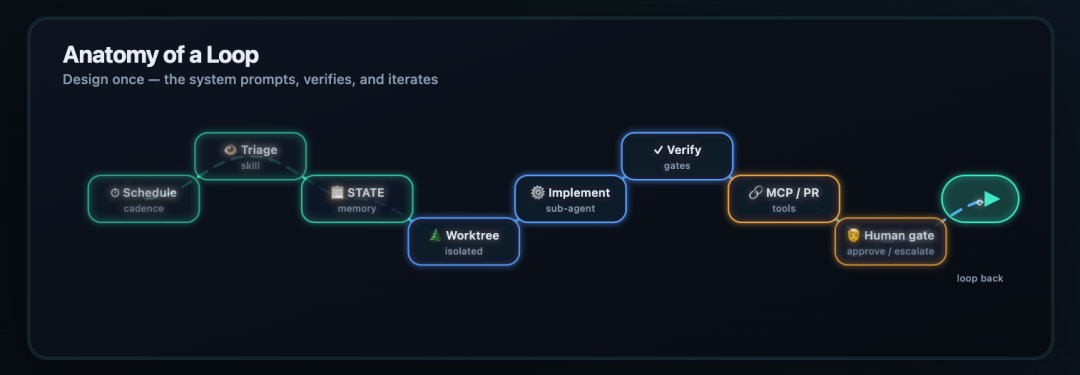
This is the main difference between a casual prompt and a real loop. The agent is not simply “doing things.” It is working inside a controlled process with state, isolation, checks, and handoff.
Andrew Ng: Product Development Needs Three Loops
The original article also connected Loop Engineering to Andrew Ng’s discussion of product development. The key point is that building software with AI is not just one loop. For a real product, there are several loops moving at different speeds.

- Agentic Coding Loop
The innermost loop is the coding loop. A human gives the agent a product specification and evaluation criteria. The agent writes code, tests it, fixes problems, and keeps iterating.
This loop can be fast. In some cases, it may produce a new version every few minutes.
- Developer Feedback Loop
The next layer is the developer feedback loop. The agent can test and revise, but the developer still checks whether the result feels right, fits the product direction, and solves the real user problem.
This loop is slower. It may run every few dozen minutes or every few hours, depending on the product and the complexity of the changes.
- External Feedback Loop
The outer layer is the user feedback loop. Once the product reaches friends, alpha testers, or real users, the team starts learning from feedback, usage data, and experiments.
This loop is slower again. It may take hours, days, or weeks.

Together, the three loops create a practical product-building chain: the agent helps produce versions quickly, the developer decides what the product should become, and users prove whether the direction is worth continuing.
Why Human Taste Still Matters
Loop Engineering does not remove humans from software development. It changes the human role.
The agent can handle repeated execution, but it still needs clear boundaries, strong verification, and product judgment. The human still understands context: what users need, what trade-offs matter, what should not be automated, and what “good enough” really means.
That is why a loop can be installed with one command, but the definition of “done” still belongs to the people building the product.
Source Note
Original source: BAAI Hub article, syndicated from QbitAI / WeChat. The article also referenced the Loop Engineering GitHub repository and Andrew Ng’s public post on X.
Image note: the opening meme image and the final QR/contact promotional banner from the source page were excluded because they are not necessary for understanding the tutorial. The remaining images are included only where they support the technical explanation.
FAQ
What is Loop Engineering?
Loop Engineering is a way to design repeatable workflows for AI agents. Instead of prompting the agent manually for every small task, you define a loop with scheduling, state, tools, verification, and human handoff.
How do I start a Loop Engineering project?
The fastest starting point is to run npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude inside a Git project. For beginners, daily-triage is usually safer than high-frequency loops because it can start in report-only mode.
Why does Loop Engineering use STATE.md?
STATE.md gives the loop durable memory outside the chat session. It helps the loop remember prior findings, last actions, unresolved items, and human overrides.
What is the Loop Ready score?
The Loop Ready score is an audit result produced by loop-audit. It checks whether the project has enough structure, state, verification, cost limits, and safety controls to run a loop responsibly.
Can an AI agent loop run unattended?
It can, but it should not start that way. A safer path is L1 report-only first, then L2 assisted fixes with verification, and only later L3 unattended runs when scope, safety, and cost controls are mature.
Why should I estimate token cost before running a loop?
Loops can become expensive if they run often, use long context, or spawn multiple sub-agents. loop-cost helps you estimate usage before a high-frequency workflow burns through budget.
How does Andrew Ng’s three-loop idea relate to this?
The engineering loop helps agents build and revise software quickly. Developer feedback and user feedback are slower loops that decide whether the product is useful, usable, and worth continuing.
Related Tools
- Loop Engineering: Open-source patterns, starters, and CLI tools for designing AI agent loops.
- Loop Engineering Showcase: Interactive overview with patterns, primitives, and a readiness simulator.
- Node.js: Runtime needed for using
npx-based CLI tools. - npm: Package ecosystem used to run the Loop Engineering CLI commands through
npx. - Git: Version control system used for repositories and worktree-based isolated execution.
- GitHub Actions: Automation platform that can support scheduled checks and loop validation workflows.
- Model Context Protocol: Protocol for connecting AI systems to external tools and data sources.
Related Links
- Original BAAI Hub Article: Source article introducing the beginner-friendly Loop Engineering tutorial.
- Loop Engineering GitHub Repository: Main repository for patterns, starters, docs, and CLI tools.
- Loop Engineering Showcase: Official interactive page for exploring the framework.
- Five Primitives + Memory: Official explanation of the core loop building blocks.
- Loop Design Checklist: Checklist for deciding whether a loop is ready for production use.
- Loop Safety Guide: Safety notes for automation, denylist paths, human review, and risk control.
- Operating Loops: Notes on cost, logging, run history, and operating discipline.
- Loop Patterns README: Overview of the available production loop patterns.
Summary
This guide explains how Loop Engineering turns one-off AI prompts into repeatable agent workflows. The basic idea is to define the schedule, state, tools, verification, and human review process before trusting an agent to act repeatedly.
For a first run, daily-triage is the safest starting point. Scaffold the loop, estimate token cost, audit readiness, and keep the first week in report-only mode.
The larger lesson is not that humans disappear from development. Agents can move faster inside loops, but product judgment, safety boundaries, and the definition of “done” still depend on people.
The best first loop is not the most autonomous one. It is the one you can inspect, trust, and improve.


