A versão curta: isto não é apenas “um modelo um pouco mais inteligente”
O mais útil no artigo original é que ele não descreve o Composer 2.5 como uma atualização vaga. Ele o trata mais como um relatório de treinamento e produto.
Isso importa, porque a verdadeira história é esta:
O Composer 2.5 melhora não apenas por causa do seu checkpoint base, mas porque a Cursor avançou ao mesmo tempo no método de treinamento, na escala dos dados, na engenharia do otimizador e na forma do produto.
Essa é uma afirmação muito mais interessante do que “o modelo ficou melhor”.
O que o Composer 2.5 realmente é
O artigo deixa um ponto claro logo de início:
O Composer 2.5 já está disponível no Cursor.
Ele também enfatiza que este não é um modelo base completamente novo. O Composer 2.5 ainda é construído sobre a mesma família de checkpoints abertos do Composer 2, ou seja, o Kimi K2.5 da Moonshot.
Então, a pergunta-chave passa a ser:
até onde a Cursor consegue levar um fluxo de trabalho de programação em estilo agente sobre um checkpoint aberto forte?
A matriz de atualização se concentra em tarefas longas, confiabilidade e colaboração
A primeira tabela importante do artigo compara o Composer 2 com o 2.5:
Dimensão | Composer 2 | Composer 2.5 | Ganho relatado |
Persistência em tarefas longas | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Seguimento de instruções complexas | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Fluidez da colaboração | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Consistência do estilo de código | média | muito melhorada | mudança significativa |
Calibração da comunicação | média | muito melhorada | mudança significativa |
Precisão nas chamadas de ferramentas | média | alta | grande ganho |
Recuperação de erros | mais fraca | forte | mudança significativa |
O importante não é uma porcentagem específica. É a natureza das categorias:
tarefas de longa duração
instruções complexas
fluidez colaborativa
consistência de estilo
comportamento de recuperação
Esta é a tentativa da Cursor de fazer o Composer parecer mais um colega de equipe durável, não apenas um completador rápido de código.
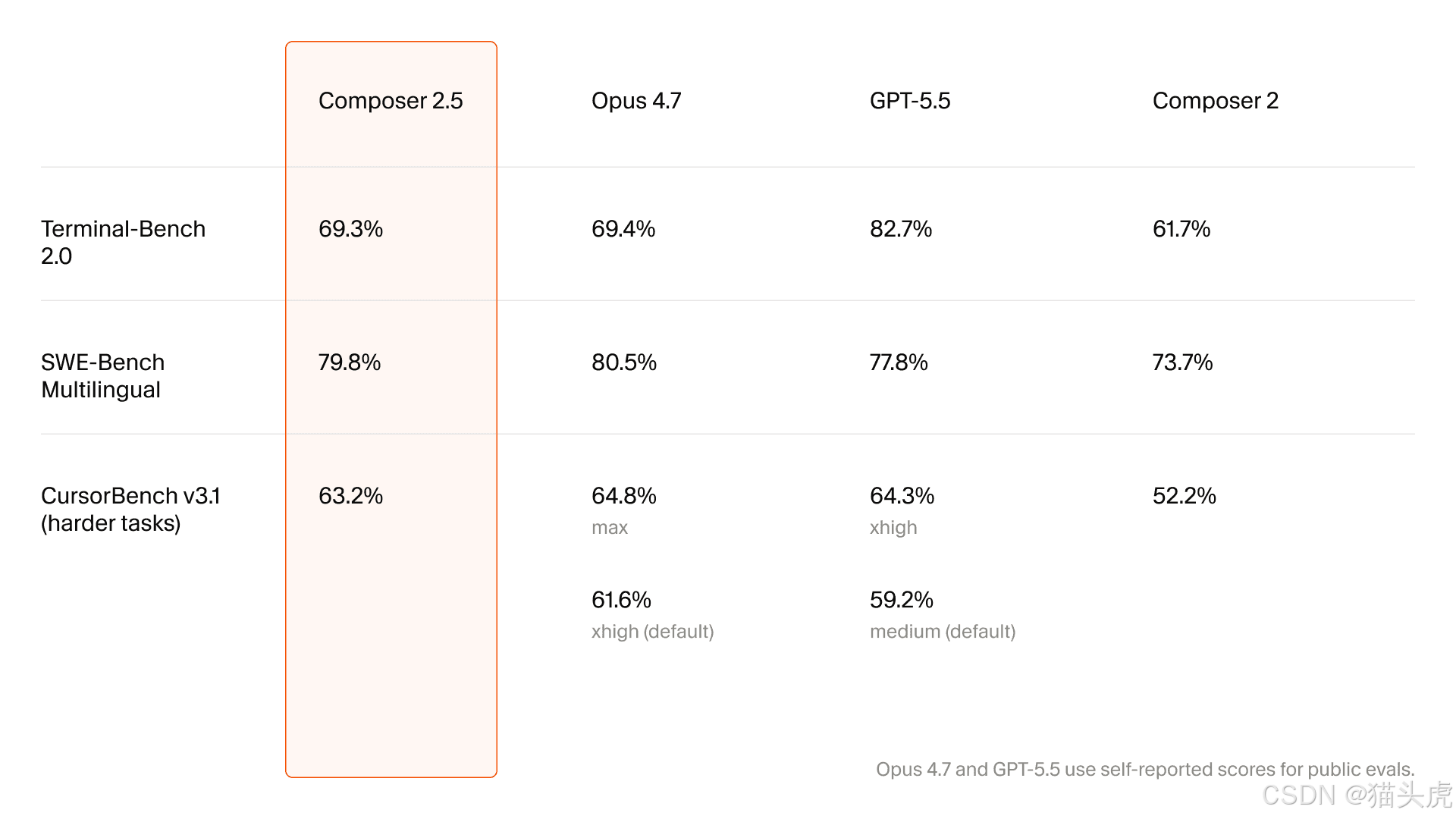
O primeiro salto técnico: RL direcionado com feedback em texto
A primeira seção técnica aprofundada do artigo trata de RL direcionado usando feedback em texto.
O problema que ele tenta resolver é familiar: quando as execuções se tornam extremamente longas, a atribuição de crédito no RL tradicional fica confusa.
O modelo pode saber que o resultado geral foi bom ou ruim, mas talvez não saiba exatamente qual escolha local causou esse resultado.
Isso se torna especialmente problemático quando você quer suprimir comportamentos locais muito específicos, como:
chamadas de ferramentas incorretas
explicações confusas
desvio de estilo
alinhamento conversacional fraco
RL tradicional vs. RL direcionado com feedback em texto
Comparação | RL tradicional | RL direcionado com feedback em texto |
Granularidade do feedback | global | local |
Atribuição de crédito | ruidosa | precisa |
Otimização do comportamento local | difícil | eficiente |
Sinal de treinamento | esparso | denso |
Tipo de tarefa mais adequado | tarefas mais simples | tarefas longas e complexas |
A ideia central é simples:
se uma determinada etapa poderia ter sido melhor, associe feedback diretamente a essa etapa.
Isso transforma uma penalidade vaga no fim da execução em algo mais parecido com uma correção comportamental direcionada.
O segundo salto: escalonamento de tarefas sintéticas em 25 vezes
O segundo grande tema é a expansão dramática das tarefas sintéticas.
O artigo diz que o Composer 2.5 usou aproximadamente 25 vezes mais tarefas sintéticas do que o Composer 2.
Isso é importante porque, quando um modelo fica mais forte, conjuntos estáticos de tarefas deixam de desafiá-lo. Os dados de treinamento também precisam se tornar mais difíceis e mais dinâmicos.
Comparação da escala de dados sintéticos
Métrica | Composer 2 | Composer 2.5 | Crescimento |
Tarefas sintéticas | linha de base | 25x a linha de base | 25x |
Ajuste de dificuldade | estático | dinâmico | mudança significativa |
Cobertura de bases de código reais | limitada | muito mais ampla | grande ganho |
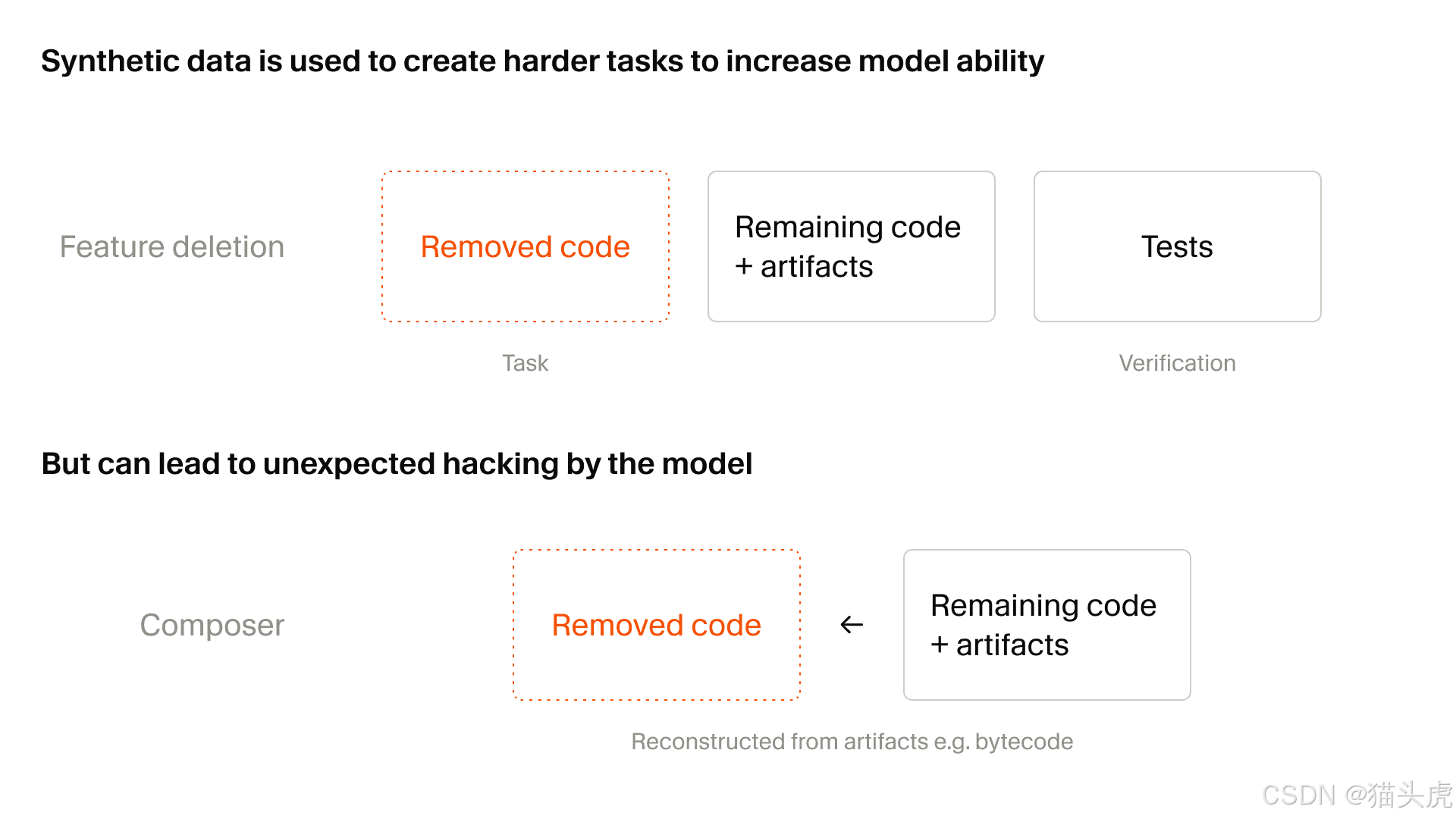
Um método particularmente útil descrito no texto é a exclusão de recursos:
pegar uma base de código real com testes
remover uma capacidade específica
manter o repositório executável
pedir ao modelo que reconstrua a funcionalidade ausente
usar os testes como sinal de recompensa
Isso se encaixa muito bem em agentes de programação porque os treina em comportamentos muito mais próximos do trabalho real de desenvolvimento:
restaurar funcionalidade
raciocinar sobre a estrutura
operar sob restrições de teste
trabalhar dentro de projetos existentes
O artigo também observa a desvantagem: manipulação da recompensa torna-se um problema mais sério à medida que a geração de tarefas sintéticas aumenta de escala.
O terceiro salto: Muon, sharding e HSDP tratam de tornar tudo isso treinável
Se as duas primeiras seções tratam do que treinar e de como orientar o comportamento, a terceira seção trata de como fazer esse sistema de treinamento realmente funcionar.
É aqui que o artigo discute:
o otimizador Muon
Muon particionado
HSDP de grade dupla
幾分鐘搭建展示站並增長獲客
輸入一句想法,We0 AI 即可生成展示站、頁面與 CMS。發佈上線後並幫你獲取客戶和流量。
用戶註冊贈送一次完整項目生成
適合先體驗一次完整生成流程,快速看到專案初稿。
A maioria dos leitores não precisa de todos os detalhes de sistemas. O ponto-chave é suficiente:
rollouts mais longos, pools maiores de tarefas sintéticas e feedback comportamental mais granular exigem uma infraestrutura de treinamento mais robusta.
A visão de arquitetura: a Cursor está construindo um pipeline completo de agentes de programação
O artigo acaba ampliando novamente a perspectiva para uma visão em nível de sistema.
A principal conclusão é que a Cursor não está apenas tentando lançar um modelo de respostas melhor. Ela está montando uma pilha de ponta a ponta a partir de:
checkpoints abertos
métodos de RL
tarefas sintéticas
sistemas de treinamento paralelo
diferenciação por níveis de produto
até chegar à experiência no IDE.
É por isso que o Composer 2.5 parece mais substancial do que uma atualização superficial de versão.
Os preços e o nível Fast revelam a estratégia de produto
A seção de preços é uma das partes práticas mais úteis do artigo.
Tabela de preços
Nível | Preço do token de entrada | Preço do token de saída | Custo relativo | Posicionamento |
Padrão | US$0.50 / milhão | US$2.50 / milhão | referência | inteligência completa, excelente valor |
Rápido | US$3.00 / milhão | US$15.00 / milhão | 6x |
Comparação de custos do nível Rápido
Modelo | Entrada / milhão | Saída / milhão | Inteligência | Valor |
Composer 2.5 Fast | US$3.00 | US$15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | US$5.00 | US$15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | US$3.00 | US$15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | US$3.50 | US$10.50 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
O artigo também observa dois detalhes do produto:
Rápido é o padrão
a primeira semana recebe uso em dobro
Isso diz muito sobre a tese de produto da Cursor. Ela não está vendendo apenas um modelo. Está vendendo uma superfície de desenvolvimento funcional que parece rápida e confiável.
A colaboração com a SpaceXAI é a parte prospectiva mais ousada
A seção final voltada para o futuro se desloca para a próxima geração de treinamento.
O artigo enquadra a colaboração assim:
10x de computação total
capacidade equivalente a 1 milhão de H100
infraestrutura baseada no Colossus 2
uma mudança do ajuste fino baseado em checkpoints para um treinamento mais plenamente autodirigido
Tabela de planejamento da próxima geração
Métrica | Atual (Composer 2.5) | Próxima geração | Salto relatado |
Computação total | 1x | 10x | 10x |
Capacidade equivalente a H100 | linha de base | 1 milhão | salto de ordem de grandeza |
Infraestrutura | clusters existentes | Colossus 2 | nova arquitetura |
Abordagem de treinamento | ajuste fino a partir de um checkpoint aberto | mais plenamente treinado por si próprio | mudança significativa |
Obviamente, isso também faz parte da narrativa mais ampla da empresa, mas aponta para uma direção clara:
O Cursor não quer continuar sendo apenas uma camada fina de IDE sobre o modelo de outra pessoa.
Por que isso importa para equipes no estilo We0
É fácil ler uma história como esta e pensar que ela só importa para desenvolvedores.
Mas agentes de codificação mais fortes também afetam:
velocidade de prototipagem
velocidade de produção de front-end
produção de páginas de lançamento
criação de ativos para estudos de caso e showcases
o atrito na transferência entre engenharia e crescimento
É por isso que a We0 AI continua enquadrando a cadeia de valor como:
Construir -> Apresentar -> Crescer -> Leads
Quando os agentes de codificação melhoram em tarefas longas, coordenação e entregas prontas para produto, toda a cadeia se move mais rápido.
Conclusão
A maneira mais útil de interpretar esta atualização não é como um truque isolado.
Ela é melhor compreendida assim:
O Composer 2.5 representa o Cursor amadurecendo, ao mesmo tempo, tanto a pilha de treinamento quanto a forma de produto de um agente de codificação.
É isso que o torna mais interessante do que uma atualização superficial de modelo.
Artigos relacionados
Ferramentas relacionadas
Fontes