La version courte : ce n’est pas simplement « un modèle légèrement plus intelligent »
Ce qu’il y a de plus utile dans l’article original, c’est qu’il ne décrit pas Composer 2.5 comme une mise à niveau vague. Il le traite plutôt comme un rapport à la fois sur l’entraînement et sur le produit.
C’est important, car la véritable histoire est la suivante :
Composer 2.5 s’améliore non seulement grâce à son checkpoint de base, mais aussi parce que Cursor a fait progresser simultanément la méthode d’entraînement, l’échelle des données, l’ingénierie de l’optimiseur et la forme du produit.
C’est une affirmation bien plus intéressante que « le modèle s’est amélioré ».
Ce qu’est réellement Composer 2.5
L’article énonce clairement un point dès le départ :
Composer 2.5 est désormais disponible dans Cursor.
Il souligne également qu’il ne s’agit pas d’un modèle de base entièrement nouveau. Composer 2.5 est toujours construit sur la même famille de checkpoints ouverts que Composer 2, à savoir Kimi K2.5 de Moonshot.
La question clé devient donc :
jusqu’où Cursor peut-il pousser un workflow de codage de type agent au-dessus d’un checkpoint ouvert puissant ?
La matrice de mise à niveau se concentre sur les tâches longues, la fiabilité et la collaboration
Le premier grand tableau de l’article compare Composer 2 à Composer 2.5 :
Dimension | Composer 2 | Composer 2.5 | Gain rapporté |
Persistance sur les tâches longues | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67 % |
Respect des instructions complexes | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67 % |
Fluidité de la collaboration | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67 % |
Cohérence du style de code | moyenne | nettement améliorée | changement radical |
Calibrage de la communication | moyen | nettement amélioré | changement radical |
Précision des appels d’outils | moyenne | élevée | gain majeur |
Récupération après erreur | plus faible | forte | changement radical |
Ce qui importe, ce n’est pas un pourcentage particulier. C’est la nature des catégories :
tâches de longue durée
instructions complexes
fluidité collaborative
cohérence du style
comportement de récupération
C’est Cursor qui tente de faire en sorte que Composer ressemble davantage à un coéquipier fiable qu’à un simple outil de complétion rapide de code.
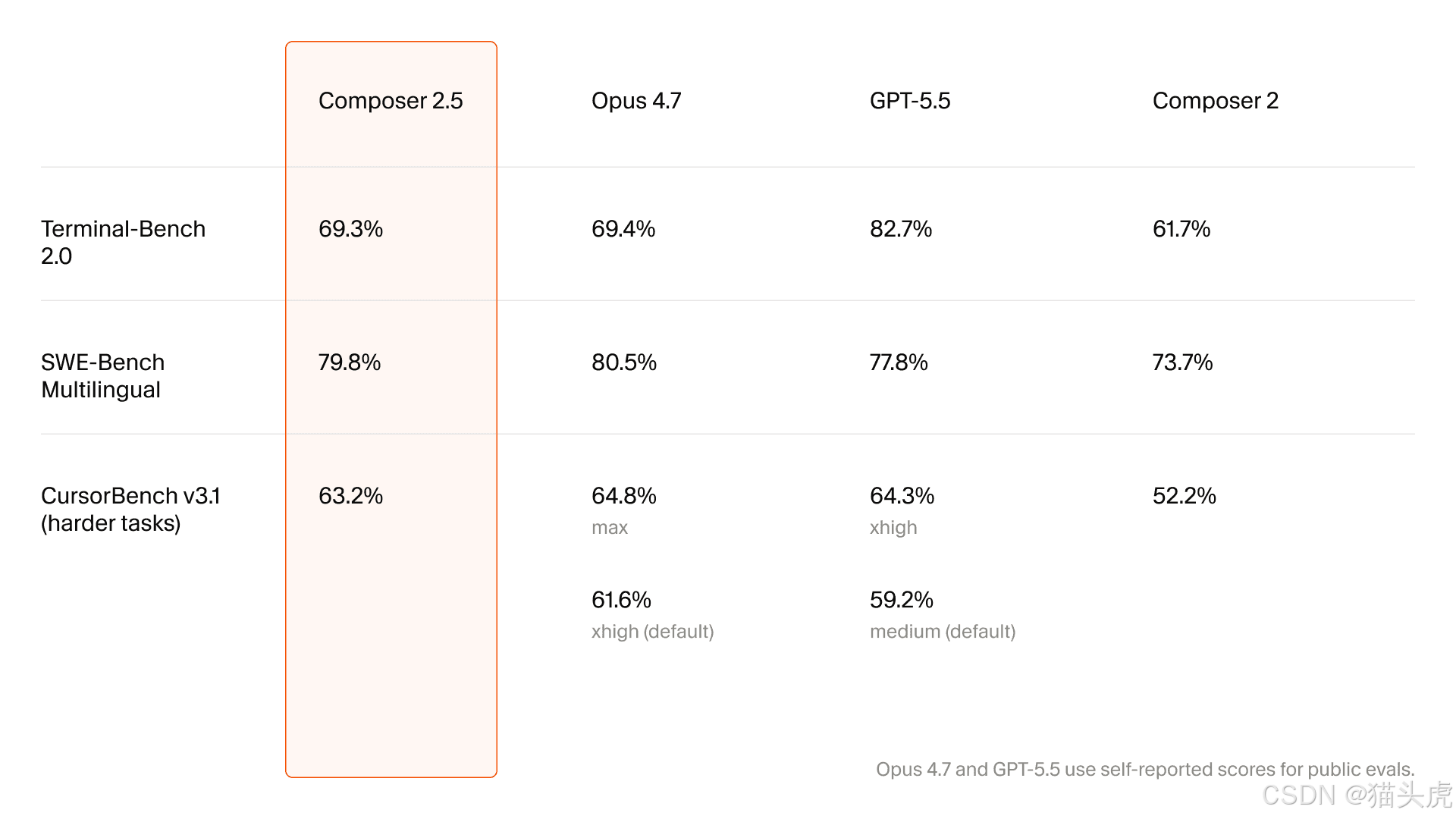
Le premier saut technique : RL dirigé par rétroaction textuelle
La première section technique approfondie de l’article porte sur le RL dirigé utilisant une rétroaction textuelle.
Le problème qu’elle tente de résoudre est familier : lorsque les rollouts deviennent extrêmement longs, l’attribution du crédit dans le RL traditionnel devient confuse.
Le modèle peut savoir que le résultat global était bon ou mauvais, mais il peut ne pas savoir exactement quel choix local a provoqué ce résultat.
Cela devient particulièrement pénible lorsque l’on veut supprimer des comportements locaux très spécifiques tels que :
des appels d’outils incorrects
des explications confuses
une dérive de style
un faible alignement conversationnel
RL traditionnel vs RL dirigé par rétroaction textuelle
Comparaison | RL traditionnel | RL dirigé par rétroaction textuelle |
Granularité de la rétroaction | globale | locale |
Attribution du crédit | bruyante | précise |
Optimisation du comportement local | difficile | efficace |
Signal d’entraînement | clairsemé | dense |
Type de tâche le mieux adapté | tâches plus simples | tâches longues et complexes |
L’idée centrale est simple :
si une étape donnée aurait pu être meilleure, associez directement la rétroaction à cette étape.
Cela transforme une vague pénalité de fin de rollout en quelque chose qui ressemble davantage à une correction comportementale ciblée.
Le deuxième saut : mise à l’échelle par 25 des tâches synthétiques
Le deuxième grand thème est l’expansion spectaculaire des tâches synthétiques.
L’article indique que Composer 2.5 a utilisé environ 25 fois plus de tâches synthétiques que Composer 2.
C’est important, car lorsqu’un modèle devient plus performant, les ensembles de tâches statiques cessent de le mettre au défi. Les données d’entraînement doivent elles aussi devenir plus difficiles et plus dynamiques.
Comparaison de l’échelle des données synthétiques
Métrique | Composer 2 | Composer 2.5 | Croissance |
Tâches synthétiques | référence | 25x la référence | 25x |
Ajustement de la difficulté | statique | dynamique | changement radical |
Couverture de bases de code réelles | limitée | beaucoup plus large | gain majeur |
Une méthode particulièrement utile décrite dans l’article est la suppression de fonctionnalités :
prendre une base de code réelle avec des tests
supprimer une capacité spécifique
garder le dépôt exécutable
demander au modèle de reconstruire la fonctionnalité manquante
utiliser les tests comme signal de récompense
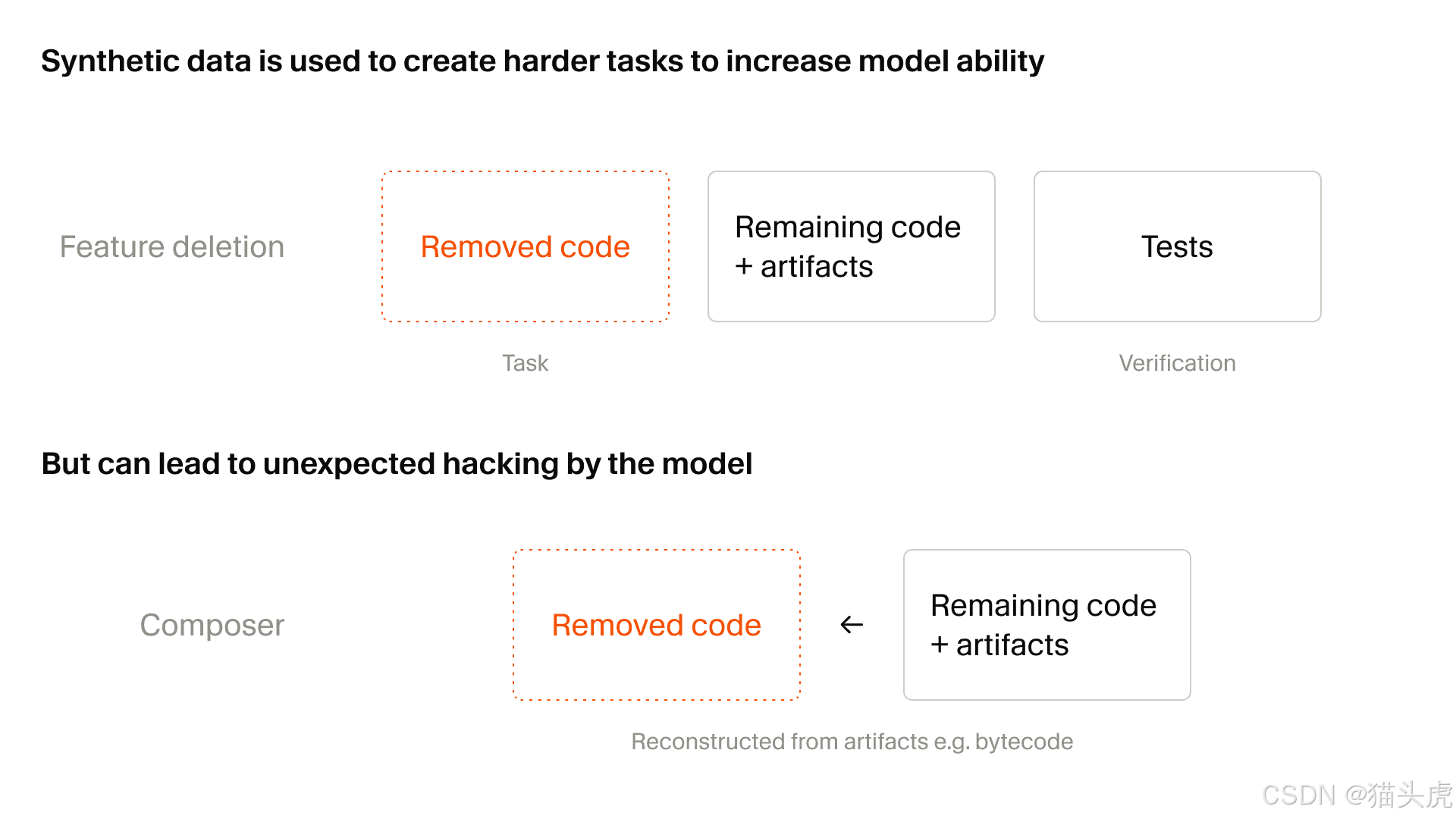
Cela convient particulièrement bien aux agents de codage, car cela les entraîne sur des comportements beaucoup plus proches du travail de développement réel :
restaurer des fonctionnalités
raisonner sur la structure
fonctionner sous contraintes de tests
travailler au sein de projets existants
L’article souligne également l’inconvénient : le détournement de la récompense devient un problème plus sérieux à mesure que la génération de tâches synthétiques prend de l’ampleur.
Le troisième bond : Muon, le partitionnement et HSDP visent à rendre l’ensemble entraînable
Si les deux premières sections portent sur ce qu’il faut entraîner et sur la manière de guider le comportement, la troisième section explique comment faire réellement fonctionner ce système d’entraînement.
C’est là que l’article aborde :
l’optimiseur Muon
Muon partitionné
HSDP à double grille
幾分鐘搭建展示站並增長獲客
輸入一句想法,We0 AI 即可生成展示站、頁面與 CMS。發佈上線後並幫你獲取客戶和流量。
用戶註冊贈送一次完整項目生成
適合先體驗一次完整生成流程,快速看到專案初稿。
La plupart des lecteurs n’ont pas besoin de tous les détails système. L’essentiel suffit :
des déploiements plus longs, des pools de tâches synthétiques plus vastes et des retours comportementaux plus granulaires exigent tous une infrastructure d’entraînement plus robuste.
Vue architecturale : Cursor construit une chaîne complète pour agents de codage
L’article finit par prendre du recul pour offrir une vision au niveau du système.
Le véritable enseignement est que Cursor ne cherche pas seulement à livrer un meilleur modèle de réponse. Il assemble une pile de bout en bout à partir de :
points de contrôle ouverts
méthodes d’apprentissage par renforcement
tâches synthétiques
systèmes d’entraînement parallèles
différenciation par niveaux de produit
jusqu’à l’expérience dans l’IDE.
C’est pourquoi Composer 2.5 semble plus substantiel qu’une simple mise à jour mineure de version.
La tarification et l’offre Fast révèlent la stratégie produit
La section sur la tarification est l’une des parties pratiques les plus utiles de l’article.
Tableau des tarifs
Niveau | Prix des tokens d’entrée | Prix des tokens de sortie | Coût relatif | Positionnement |
Standard | 0,50 $ / million | 2,50 $ / million | référence | intelligence complète, excellent rapport qualité-prix |
Rapide | 3,00 $ / million | 15,00 $ / million | 6x |
Comparaison des coûts du niveau Rapide
Modèle | Entrée / million | Sortie / million | Intelligence | Valeur |
Composer 2.5 Fast | 3,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | 5,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | 3,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | 3,50 $ | 10,50 $ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
L’article relève également deux détails concernant le produit :
Rapide est le choix par défaut
la première semaine donne droit à une utilisation doublée
Cela en dit long sur la thèse produit de Cursor. Il ne vend pas seulement un modèle. Il vend une surface de développement opérationnelle qui donne une impression de rapidité et de fiabilité.
La collaboration SpaceXAI est la partie prospective la plus audacieuse
La dernière section tournée vers l’avenir s’oriente vers la prochaine génération d’entraînement.
L’article présente la collaboration ainsi :
10x de calcul total
capacité équivalente à 1 million de H100
infrastructure basée sur Colossus 2
un passage du finetuning basé sur des checkpoints vers un entraînement plus entièrement autodirigé
Tableau de planification de nouvelle génération
Métrique | Actuel (Composer 2.5) | Nouvelle génération | Progression annoncée |
Calcul total | 1x | 10x | 10x |
Capacité équivalente H100 | référence | 1 million | saut d’un ordre de grandeur |
Infrastructure | clusters existants | Colossus 2 | nouvelle architecture |
Approche d’entraînement | finetuning à partir d’un checkpoint ouvert | entraînement plus largement autonome | changement de palier |
Cela fait évidemment aussi partie du récit plus large de l’entreprise, mais cela indique une direction claire :
Cursor ne veut pas rester seulement une fine couche d’IDE au-dessus du modèle de quelqu’un d’autre.
Pourquoi cela compte pour les équipes de type We0
Il est facile de lire une histoire comme celle-ci et de penser qu’elle ne concerne que les développeurs.
Mais des agents de codage plus puissants influencent aussi :
la vitesse de prototypage
la vitesse de production front-end
la production de pages de lancement
la création d’actifs pour les études de cas et les présentations
les frictions de transmission entre l’ingénierie et la croissance
C’est pourquoi We0 AI continue de présenter la chaîne de valeur ainsi :
Construire -> Présenter -> Croître -> Prospects
Lorsque les agents de codage s’améliorent sur les tâches longues, la coordination et les livrables prêts pour le produit, toute la chaîne avance plus vite.
Conclusion
La manière la plus utile d’interpréter cette mise à niveau n’est pas de la voir comme une astuce isolée.
Il vaut mieux la comprendre ainsi :
Composer 2.5 représente la maturation simultanée, chez Cursor, de la pile d’entraînement et de la forme produit d’un agent de codage.
C’est ce qui la rend plus intéressante qu’un simple rafraîchissement superficiel du modèle.
Articles connexes
Outils associés
Sources