
重點整理
Gemini 3.5 Flash 最昂貴的錯誤,是無聲的預設值,而不是語法錯誤。
對許多程式設計代理而言,
low比大家預期中更適合作為預設值。透過 GitHub Copilot 執行高頻代理迴圈,可能因為 14 倍計費而變得昂貴許多。
在 We0 AI,模型選擇只是工作流程的一部分。其餘在於產品如何被說明、呈現與發掘。
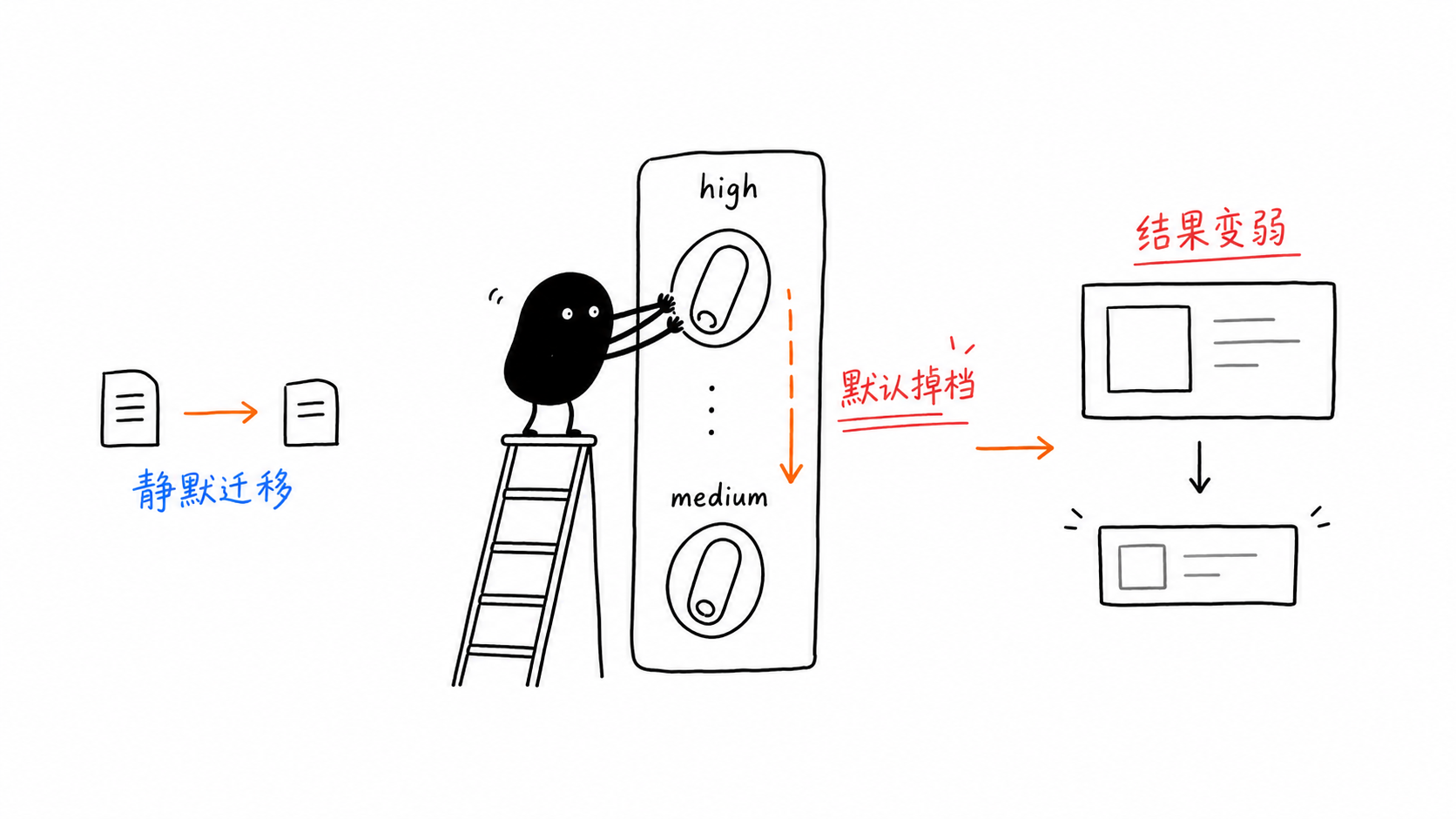
gemini-3.5-flash 看起來很容易呼叫。
也正因如此,它很容易被低估。即使只是將預覽版本時期的程式碼做小幅遷移,也可能產生更差的輸出、不同的成本結構,以及更昂貴的多輪迴圈,而且全程不會拋出任何明顯錯誤。
本指南聚焦於最重要的三個陷阱、可避免這些問題的程式碼寫法,以及一個你可以快速調整套用的實用 MCP 風格代理迴圈。
陷阱 1:thinking_level 的預設值從 High 降為 Medium
這很危險,因為什麼都不會當掉。
你把舊程式碼移植過來,請求仍然會回傳,但模型的推理層級已不再是你原本以為的那個水準。
舊版與新版的思維模型
值
作用
使用時機
minimal
最低限度的推理
自動補全、分類、單次完成
low
針對程式碼與代理任務重新調整
程式設計代理、MCP 工具迴圈、多步驟工作流程
medium
新的預設值 — 平衡
消費者聊天、一般問答
high
最大推理強度
高難度推理、除錯新型問題、數學、規劃
最容易犯的錯誤
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)第二段程式碼可以執行,但預設值已經和以前不同了。
更安全的移植方式
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)違反直覺的建議
對許多程式設計代理工作流程來說,應該先從 low 開始,而不是 high。
實務上的原因很簡單:
更快
更便宜
對以工具為主的程式設計迴圈來說,通常已經夠用,或表現相近
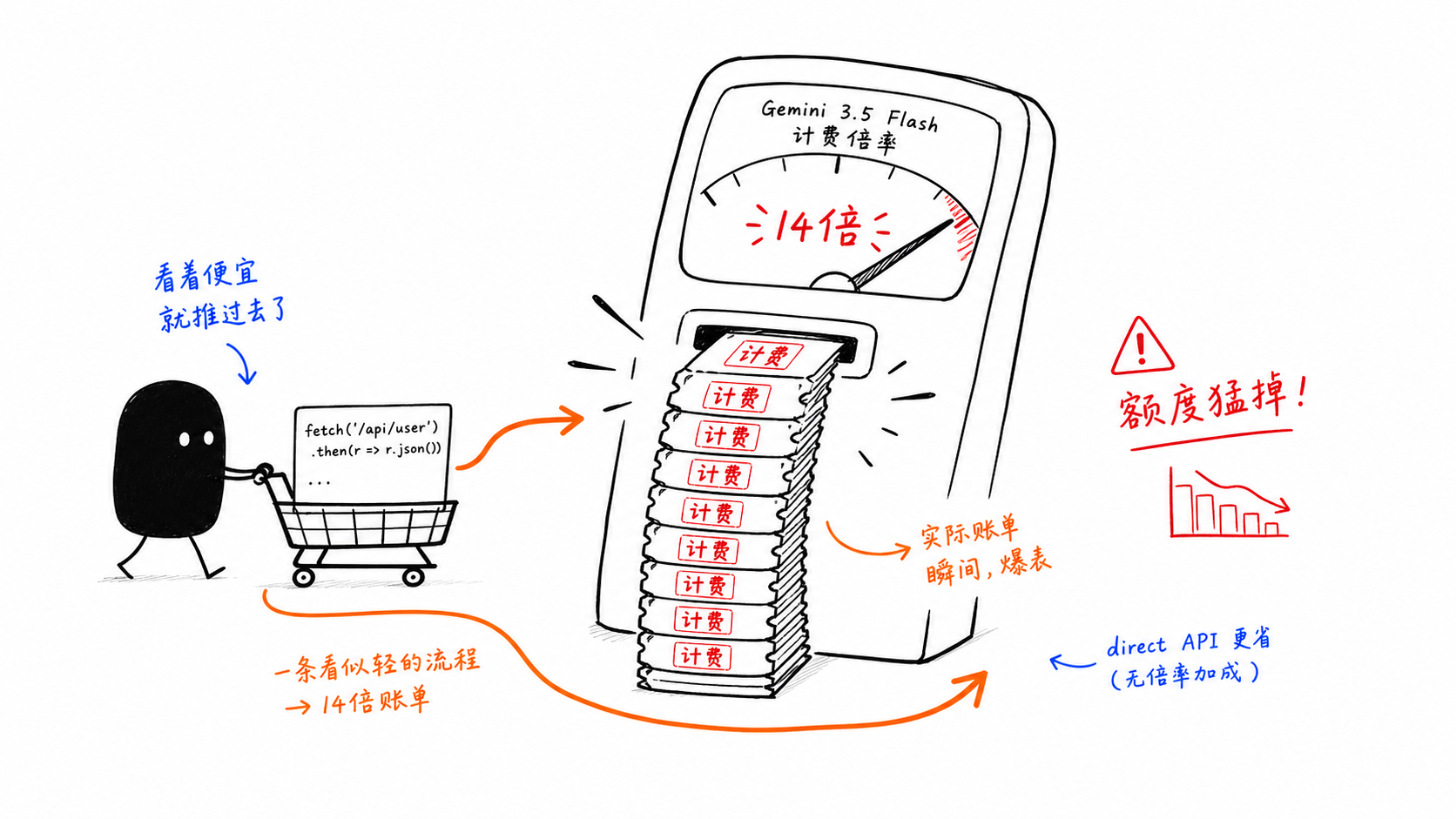
陷阱 2:GitHub Copilot 對 Gemini 3.5 Flash 的計費是 14 倍
這是本文中成本最高的陷阱。
問題不在於模型的牌價,而是在 GitHub Copilot 內部的高級請求倍率。一旦以代理方式使用 Flash,成本結構就會很快改變。
這就是為什麼許多團隊會拆分路徑:
輕量的互動式使用留在 Copilot 內
高頻迴圈與批次型工作流程則走直接 API
Build a showcase site and grow leads in minutes
Describe your idea once, and We0 AI can generate a showcase site, pages, and CMS, then help you attract customers and traffic after launch.
One complete project generation for free registration
Best for trying one complete generation flow and seeing a first project draft quickly.
架構本身就成了成本控管。
陷阱 3:思維保留會自動推高多輪 Token 帳單
Gemini 3.5 Flash 會在多輪對話中延續內部推理。
這會提升連貫性,但也代表那些思維內容可能持續出現在後續的 token 計算中。
對長時間的代理迴圈來說,這可能會大幅提高 token 使用量。
實務上的緩解方式
在清楚的階段邊界重設對話
摘要後只保留真正重要的內容往下傳遞
對穩定的指令與工具定義使用提示快取
持續觀察 thoughts tokens 與 prompt tokens 的比例變化
一個可運作的 Gemini 3.5 Flash MCP Agent
原始文章包含一個非常實用的端對端模式:一個讀取檔案工具、一個抓取 URL 工具、標準的函式宣告格式,以及一個將工具回應送回模型的迴圈。
工具定義
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="讀取本機檔案並以文字形式回傳其內容。",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "檔案的絕對路徑"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="擷取 URL 並以文字形式回傳回應主體。",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "完整 URL"
}
},
"required": ["url"],
},
)Agent 迴圈模式
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"未知工具:{call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
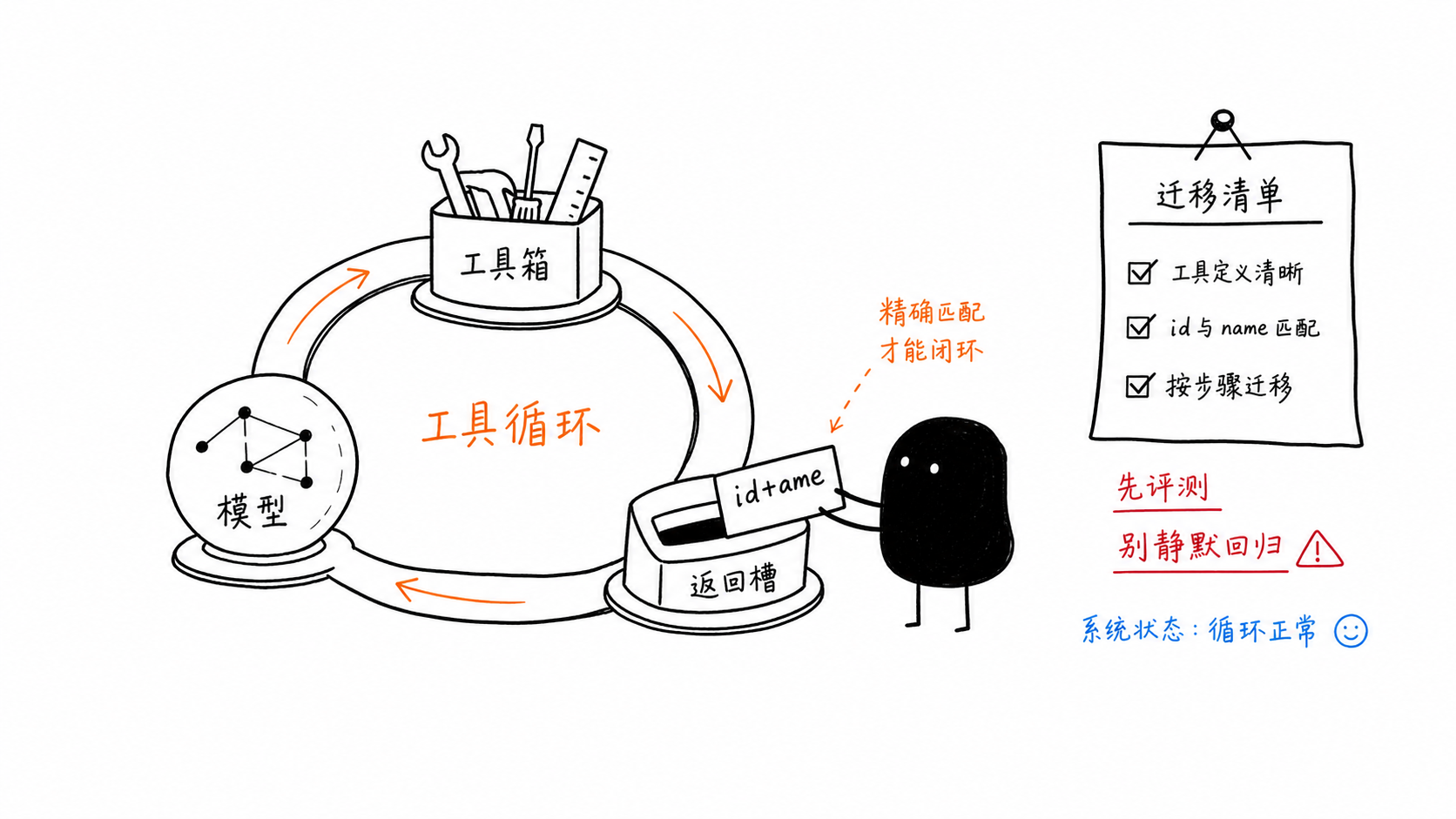
history.append(types.Content(role="tool", parts=tool_results))這裡有一條小但關鍵的遷移規則:你的函式回應必須同時對應原始呼叫中的 id 與 name。
何時應該改用 Antigravity
手動建立工具迴圈對原型開發來說沒問題。但到了正式環境,你很快就會發現自己在重建協調、快取、路由、重試與可觀測性。
這就是為什麼更重要的問題不只是「我能不能把這個模型接進來?」,而是「我到底要自己承擔多少 Agent 基礎設施?」
快速遷移檢查清單
如果你正從 gemini-3-flash-preview 遷移到 gemini-3.5-flash,請明確檢查以下項目:
謹慎替換模型 id
有意識地設定
thinking_level移除過時的取樣覆寫設定,除非評估結果證明它們有必要
在工具回應中對應 id 與 name
檢查
response.usage_metadata.thoughts_token_count對於你仍然依賴但尚未支援的 API,保留 preview 版本
執行遷移前後評估
比較 Copilot 計費與直接 API 成本
搭配你的工具試用 Gemini 3.5 Flash
如果你的目標不只是測試提示詞,而是把檔案、程式碼儲存庫、API、文件與 Agent 工作流程串接在一起,那你通常需要的不只是原始模型端點。
在 We0 AI,這個原則還會再延伸一步:Agent 工作流程只完成了一半的工作,另一半則是透過文件、FAQ、產品頁、展示內容,以及 SEO / GEO 觸點,讓產品更容易被理解、搜尋、推薦與轉換。
常見問題
我要如何從 Python 呼叫 Gemini 3.5 Flash?
呼叫本身很簡短。真正重要的是明確設定 thinking_level,這樣遷移時才不會在無聲無息中降低輸出品質。
thinking_level 有哪些值?
minimal適用於非常輕量的任務low適用於程式開發與 Agent 工作流程medium作為偏向一般使用者風格的預設值high適用於更困難的推理與更深入的規劃
為什麼 Gemini 3.5 Flash 在 GitHub Copilot 裡成本更高?
因為計費倍率改變了成本結構。對於高強度的 Agent 使用情境來說,這一點對成本的影響,可能比基礎模型價格還要大。
什麼是 thought preservation?
它指的是模型能在多輪對話中延續內部推理。這有助於提升多輪互動的一致性,但也會增加 token 成本隨時間上升的可能性。
Gemini 3.5 Flash 適合用於 MCP 嗎?
是的,尤其是在謹慎處理工具結構描述、回應比對、thinking_level 與權杖預算時。


