
最近的一个 Codex 日志记录问题,把一个安静的本地数据库变成了出人意料的 SSD 写入大户。根据最初的 GitHub 报告,在所报告的使用模式下,Codex 的 SQLite 反馈日志每年可能写入大约 640TB。对于一块额定写入寿命约为 600TBW 的消费级 SSD 来说,这个数字可不只是有点混乱;它已经接近该硬盘的保修写入耐久度。
奇怪的是,这个日志数据库看起来并不大。文件可能只有约一 GB,而实际的历史写入却在后台不断累积。这就是为什么这个 bug 引起了如此多关注:它不会以明显的方式填满磁盘,但仍可能消耗大量写入周期。

来源说明:本文基于 BAAI Hub 对新智元报道的转载,并与公开的 GitHub issue 和 Hacker News 讨论进行了交叉核对。原页面中的品牌标志、二维码、关注提示以及无关装饰图片未包含在内。
640TB 的 SSD 写入是如何发生的
这个数字乍听起来像是夸大其词,所以不妨先从测量结果说起。
在 GitHub issue 中,报告者称,在大约 21 天的运行时间 后,主 SSD 已写入约 37TB。如果外推到一整年,大约就是 640TB。被怀疑的主要来源是 Codex 的本地 SQLite 反馈日志数据库。
Codex 正在向本地配置目录下的文件写入:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shm这种行为并不只是“日志文件会无限增长”。相反,它看起来更像一个 插入并清理 循环:Codex 插入新行,然后删除旧行,以保持保留的行数稳定。可见的文件大小保持相对平稳,但硬盘仍然必须处理反复的写入。
报告中的一个 15 秒样本清楚地显示了这个问题:
指标 | 之前 | 之后 |
保留行数 | 681,774 | 681,774 |
最大行 ID | 5,003,347,015 | 5,003,383,226 |
这意味着大约有 36,211 行在 15 秒内被插入,尽管保留的行数完全没有增加。从外部看,数据库似乎很稳定,但底层的写入 churn 仍在继续。
频繁出现的日志条目也并不全都是高价值的应用事件。示例中包括重复的文件系统和依赖项级别噪声,例如 inotify 事件:
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")其结果是,一个本地日志系统可能会持续重写存储,同时几乎不给用户任何可见迹象表明有异常正在发生。
1GB 的文件仍然可能产生数百 TB 的写入量
这起事件中最反直觉的部分很简单:SSD 磨损取决于总写入量,而不是当前文件大小。
本地数据库可以维持在约 1GB 左右,同时应用程序不断对其部分内容进行写入、修剪、建立索引、执行检查点和重写。从存储健康的角度来看,重要的不只是文件今天看起来有多大。重要的是随着时间推移已经写入了多少数据。
报告中包含了一个快照,使这种差距更容易看清:
指标 | 值 |
当前 | 1.2 GiB |
当前保留的行数 | 506,149 |
已分配的行 ID 总数 | 5,543,677,486 |
当前数据库仅保留了大约五十万行,而自增行 ID 已经超过了 55 亿。这正是写入放大问题的核心:旧行可以从当前数据库视图中消失,但创建它们所产生的磁盘写入已经发生了。
SQLite 的 WAL,即预写式日志,在这里也很重要。在 WAL 模式下,更改会先追加到单独的 -wal 文件中,然后再通过检查点写回主数据库。WAL 是 SQLite 中一种正常且有用的机制,但当应用程序执行非常频繁的插入和删除操作时,它可能会成倍增加幕后发生的磁盘活动量。
通俗地说:笔记本看起来仍然很薄,但同样的页面已经被书写、擦除又重写了许多次。
根本原因:一个未按用户预期运行的 RUST_LOG 设置
该报告指出了 Codex 日志记录路径中一个尤其重要的配置细节:
Targets::new().with_default(Level::TRACE)在 Rust 的 tracing 生态系统中,日志过滤通常通过目标和级别来控制。用户可能会合理地期望 RUST_LOG 环境变量有助于将日志详细程度降低到类似 info、warn 或更低的级别。
但在这一路径中,SQLite 反馈日志接收器使用了 TRACE 作为默认级别。TRACE 是最详细的级别,可能会捕获底层依赖细节、原始协议活动以及其他调试噪声。该问题报告认为,这一默认设置意味着本地持久化日志数据库持续存储了远超应有范围的内容。
保留下来的日志分布显示了 TRACE 级别内容占据主导地位的程度:
级别 | 估算 MiB | 字节占比 |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
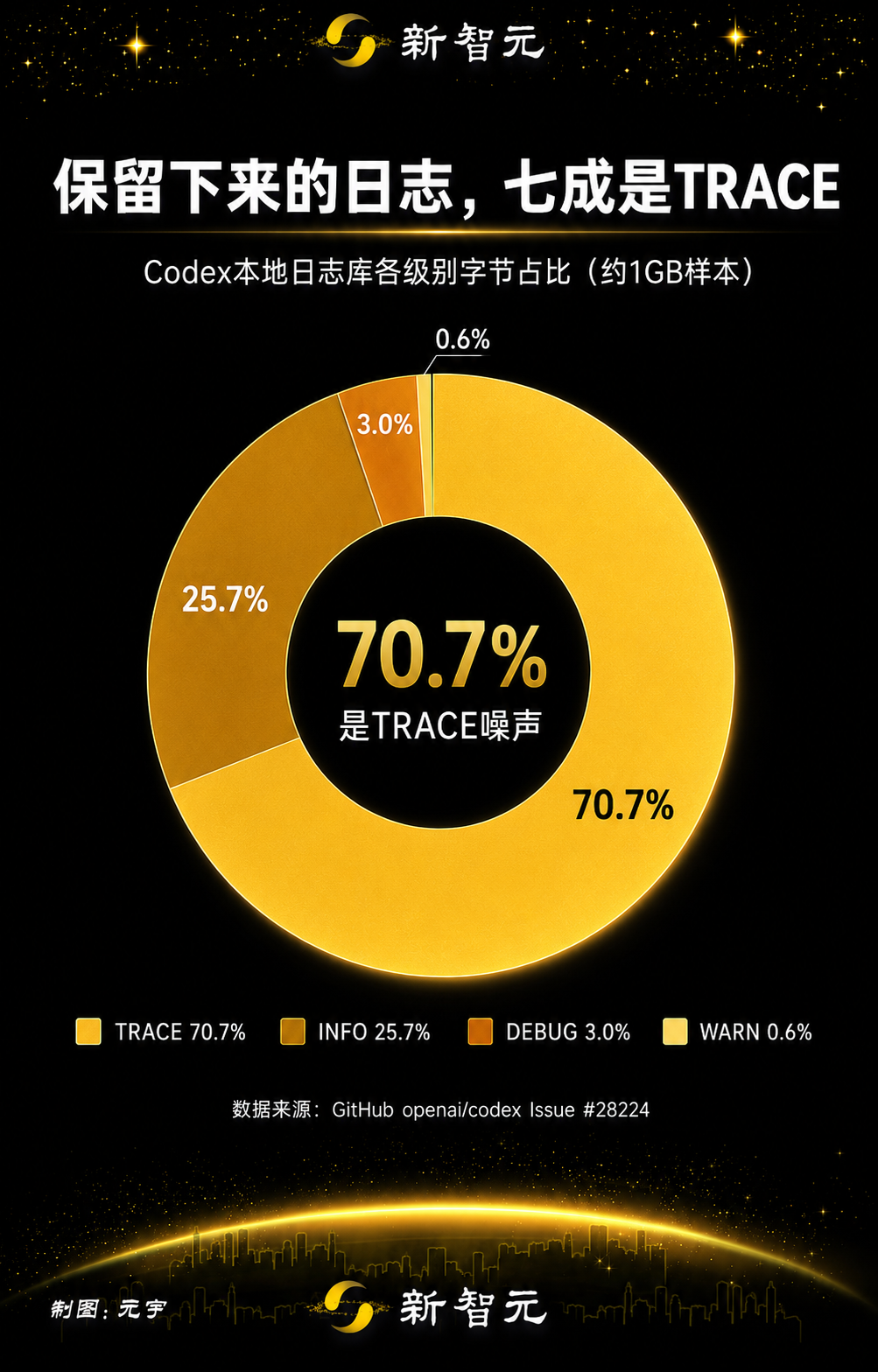
该报告还指出,两个与 OpenTelemetry 相关的镜像日志源 codex_otel.log_only 和 codex_otel.trace_safe 占据了保留日志字节数的另一大部分。在该样本中,报告者估计,过滤这些噪声类别可以在不完全禁用反馈日志的情况下,移除大部分保留的日志量。
这就是为什么这个 bug 让开发者感到如此沮丧。它并不只是“你忘了配置日志记录”。它更像是“你试图减少日志记录,但这条路径仍然无论如何都会持久化详细日志”。
Erstelle in Minuten eine Showcase-Website und gewinne Leads
Beschreibe deine Idee einmal, und We0 AI erstellt eine Showcase-Website, Seiten und ein CMS und hilft nach dem Launch bei Kunden und Traffic.
这并不是第一个相关问题
该报告并未将其视为一次孤立的意外事件。它列出了一组与 SQLite 日志、WAL 增长、大量磁盘活动以及无边界或过量本地日志记录相关的 Codex 问题。
报告中提到的一些示例包括:
问题 | 报告的主题 |
| 流式传输期间 SQLite WAL 写入过多,因为 TRACE 日志忽略了 |
| 桌面端 |
| WAL 文件仍被分配或意外增长 |
| 反馈日志 SQLite 增长,缺少足够的保留或轮换机制 |
| 小型 SQLite 数据库上的写放大 |
| 空闲 Codex 进程产生大量 I/O |
| Windows / WSL2 上磁盘活动时间达到 100% |
AI 编程工具正越来越多地被视为始终在线的开发伙伴。它们读取文件、监视代码仓库、保持会话存活、收集遥测数据并保留上下文。这使得本地磁盘、内存和 CPU 预算与 token 预算和模型质量同样重要。
修复已合并,但争论并未结束
该 GitHub issue 后来添加了一条更新,称已有三个拉取请求被合并,并且报告者自己的 Codex 反馈显示,日志量预计减少了 85%。
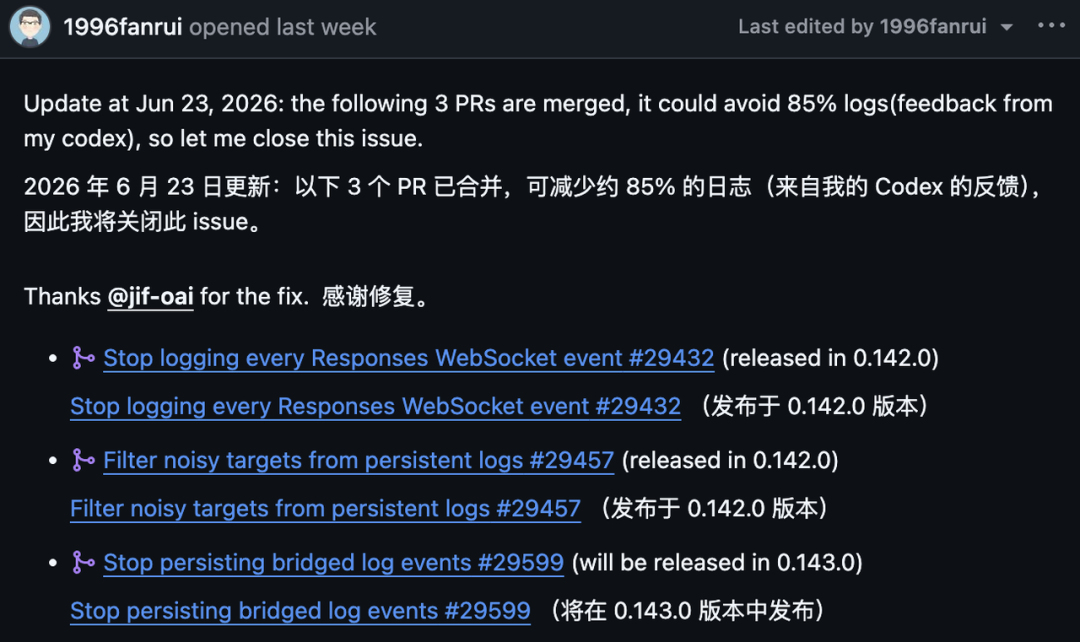
该 issue 是这样列出这三项修复的:
拉取请求 | 目的 | Issue 中的发布说明 |
| 停止记录每个 Responses WebSocket 事件 | 已在 |
| 从持久日志中过滤噪声目标 | 已在 |
| 停止持久化桥接的日志事件 | 计划用于 |
85% 的减少幅度很显著,但这并不等同于证明本地日志现在已经有了严格的长期写入预算。这一区别正是讨论持续下去的原因。开发者们问的不只是这个特定 bug 是否已经得到缓解;他们还在问,AI 编码代理是否应该对持久化本地遥测有更明确的限制。
该 GitHub issue 还包含了一位评论者分享的简单变通方法。它通过创建一个 SQLite 触发器来阻止向 logs 表插入数据:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"请谨慎使用这类变通方法。它们可能会减少本地日志写入,但也可能删除支持团队或开发者日后可能需要的诊断数据。一般来说,更新到已修复的版本并检查当前日志行为,比在不了解取舍的情况下悄悄修改应用程序数据库更安全。
编码工具之战消耗的不只是 SSD
讨论很快就不再局限于 Codex 本身。在 Hacker News 上,开发者们还提出了对 AI 编码工具更广泛的不满:GPU 占用率高、内存消耗大、后台活动频繁,以及庞大的本地调试日志。

这种反应是可以理解的。现代 AI 编程助手不再是简单的命令行工具。它们中的许多更像是本地代理:它们会监视项目、与远程模型通信、管理上下文、运行命令,并在任务之间保持状态。这种能力很有用,但也带来了一类新的工程责任。
一个工具在用户界面中可能感觉“没问题”,但仍然在后台悄悄消耗资源。高速 CPU、大容量内存和现代 NVMe 硬盘可以在很长时间内掩盖问题。应用可能不会卡死。磁盘可能不会被占满。终端可能仍然有响应。但硬件健康计数器可能会呈现出另一番景象。
这就是为什么这起事件成为 AI 开发者工具的一个有用案例研究。模型能力很重要,但本地运行质量同样重要。一个运行在开发者机器上的编程代理需要合理的默认设置、保留限制、日志轮转,以及一种让用户了解它正在做什么的方式。
常见问题
Codex SQLite 日志漏洞是什么?
这是一个被报告的 Codex 日志记录问题,其中本地 SQLite 反馈日志可能产生非常大量的磁盘写入。GitHub 报告估计,在报告者测量到的使用模式下,每年约有 640TB 的写入量。
为什么一个很小的 logs_2.sqlite 文件仍然会磨损 SSD?
SSD 的耐久性取决于一段时间内写入的数据总量,而不仅仅是当前文件大小。数据库可以反复插入、删除、写入 WAL、执行检查点以及更新索引,同时在磁盘上看起来仍然很小。
在这种情况下,SQLite WAL 是什么意思?
WAL 代表预写式日志。SQLite 会先将更改写入单独的 -wal 文件,随后再通过检查点将其写回主数据库,这是正常行为,但当插入和删除非常频繁时,可能会产生大量活动。
TRACE 日志起到了什么作用?
TRACE 是最详细的日志级别。在报告的样本中,TRACE 级别的内容约占保留日志字节数的 70.7%,该问题指出,详细的依赖项和协议日志默认被持久化保存。
OpenAI 修复了 Codex 日志问题吗?
GitHub issue 更新称已有三个 PR 被合并,报告者根据其 Codex 使用反馈估计,这些 PR 可避免约 85% 的日志。两个修复被列为已在 0.142.0 中发布,而第三个被列为计划在 0.143.0 中发布。
用户应该手动删除或阻止 Codex 日志吗?
应谨慎处理手动更改,因为它们可能会删除诊断信息,并可能产生副作用。更安全的第一步是更新 Codex、检查日志文件,并在你担心时监控 SSD 写入计数器。
这只是 Codex 的问题吗?
这份具体报告聚焦于 Codex。不过,更广泛的担忧适用于本地 AI 代理整体:始终运行的工具需要针对磁盘、CPU、内存、遥测和保留日志制定明确的资源预算。
相关工具
OpenAI Codex GitHub 仓库:Codex CLI 及相关源代码的公共仓库。
SQLite:许多本地应用程序和工具使用的嵌入式数据库引擎。
SQLite 预写式日志文档:解释 WAL 工作原理以及检查点为何重要的官方文档。
Rust tracing:Codex 问题中讨论的 Rust 结构化日志记录和诊断框架。
smartmontools:用于检查 SMART 存储健康数据的工具集,包括受支持驱动器上的 SSD 写入计数器。
Hacker News:Codex 日志报告引发更广泛开发者关注的讨论平台。
相关链接
Codex SQLite 反馈日志问题 #28224:记录所报告的每年 640TB 写入估算及相关证据的主要 GitHub 问题。
停止记录每个 Responses WebSocket 事件 #29432:作为减少日志工作一部分列出的已合并 PR 之一。
从持久日志中过滤嘈杂目标 #29457:该 PR 专注于过滤嘈杂的持久日志目标。
停止持久化桥接日志事件 #29599:后续 PR 旨在阻止桥接依赖日志事件被持久化。
Hacker News 讨论:社区围绕 Codex 日志、SSD 写入以及 AI 编码工具质量的讨论。
OpenAI Codex CLI README:用于安装和运行 Codex CLI 的官方仓库 README。
SQLite WAL 文档:关于 WAL 文件、检查点和性能注意事项的官方说明。


