Объяснение ошибки журнала Codex SQLite: 640 ТБ записей на SSD, TRACE-логи и исправления OpenAI
Понятное объяснение ошибки в журнале обратной связи Codex SQLite: почему небольшая локальная база данных журналов всё равно могла создавать ...
Недавняя проблема с журналированием в Codex превратила тихую локальную базу данных в неожиданно активный источник записей на SSD. Согласно исходному отчету на GitHub, журналы обратной связи Codex в SQLite могли записывать примерно 640 ТБ в год при описанном сценарии использования. Для потребительского SSD с ресурсом около 600 TBW это число не просто немного неаккуратно; оно близко к гарантированному ресурсу записи накопителя.
Странность в том, что база данных журнала не выглядела огромной. Файл мог занимать около одного гигабайта, тогда как фактический объем исторических записей продолжал накапливаться в фоновом режиме. Именно поэтому эта ошибка привлекла столько внимания: она не заполняла диск очевидным образом, но все равно могла быстро расходовать циклы записи.
Примечание об источниках: эта статья основана на репосте отчета Xinzhiyuan на BAAI Hub и сверена с публичным issue на GitHub и обсуждением на Hacker News. Логотипы брендов, QR-коды, призывы подписаться и несвязанные декоративные изображения с исходной страницы не включены.
Как могут появиться 640 ТБ записей на SSD
Сначала это число кажется преувеличенным, поэтому стоит начать с измерения.
В issue на GitHub автор сообщил, что примерно после 21 дня работы без перезагрузки основной SSD записал около 37 ТБ. При экстраполяции на полный год это дает примерно 640 ТБ. Предполагаемым основным источником была локальная база данных журналов обратной связи Codex в SQLite.
Codex выполнял запись в файлы в локальном каталоге конфигурации:
Поведение заключалось не просто в том, что «файл журнала бесконечно растёт». Скорее это было похоже на цикл вставки и очистки: Codex вставлял новые строки, а затем удалял старые, чтобы сохранять стабильным количество удерживаемых строк. Видимый размер файла оставался относительно спокойным, но накопителю всё равно приходилось обрабатывать повторяющиеся операции записи.
15-секундный фрагмент из отчёта ясно показал проблему:
Метрика
До
После
Удерживаемые строки
681,774
681,774
Максимальный ID строки
5,003,347,015
5,003,383,226
Это означает, что примерно 36 211 строк были вставлены за 15 секунд, хотя количество сохранённых строк вообще не увеличилось. Снаружи база данных выглядела стабильной, но внутри продолжалась активная перезапись.
Частые записи в журнале также не всегда были ценными событиями приложения. Примеры включали повторяющийся шум на уровне файловой системы и зависимостей, например события inotify:
В результате локальная система журналирования могла продолжать перезаписывать хранилище, почти не подавая пользователям видимых признаков того, что происходит что-то необычное.
Файл размером 1 ГБ всё ещё может привести к сотням терабайт записей
Самая контринтуитивная часть этого инцидента проста: износ SSD зависит от общего объёма записей, а не от текущего размера файла.
Локальная база данных может оставаться в пределах примерно 1 ГБ, в то время как приложение постоянно записывает, удаляет, индексирует, создаёт контрольные точки и перезаписывает её части. С точки зрения состояния накопителя важно не только то, насколько большим выглядит файл сегодня. Важно то, сколько данных было записано с течением времени.
Отчёт включал один снимок, который наглядно показывал этот разрыв:
Метрика
Значение
Текущий размер файла logs_2.sqlite
1,2 ГиБ
Текущее количество сохранённых строк
506 149
Общее количество выделенных идентификаторов строк
5 543 677 486
Текущая база данных содержала всего около полумиллиона строк, тогда как автоматически увеличиваемый идентификатор строки уже превысил 5,5 миллиарда. В этом и заключается суть истории с усилением записи: старые строки могут исчезнуть из текущего представления базы данных, но записи на диск, в результате которых они были созданы, уже произошли.
WAL в SQLite, или журналирование с упреждающей записью, здесь тоже имеет значение. В режиме WAL изменения сначала добавляются в отдельный файл -wal, прежде чем через контрольную точку записываются обратно в основную базу данных. WAL — это обычный и полезный механизм SQLite, но когда приложение выполняет очень частые вставки и удаления, он может многократно увеличить объём дисковой активности, происходящей в фоновом режиме.
Проще говоря: блокнот всё ещё выглядит тонким, но одни и те же страницы были написаны, стёрты и переписаны много раз.
Первопричина: настройка RUST_LOG, которая работала не так, как ожидали пользователи
В отчёте указывалось на одну особенно важную деталь конфигурации в пути журналирования Codex:
Targets::new().with_default(Level::TRACE)
В экосистеме tracing Rust фильтрация журналов часто управляется через цели и уровни. Пользователи вполне могут ожидать, что переменная окружения RUST_LOG поможет снизить подробность журналирования до уровня вроде info, warn или ниже.
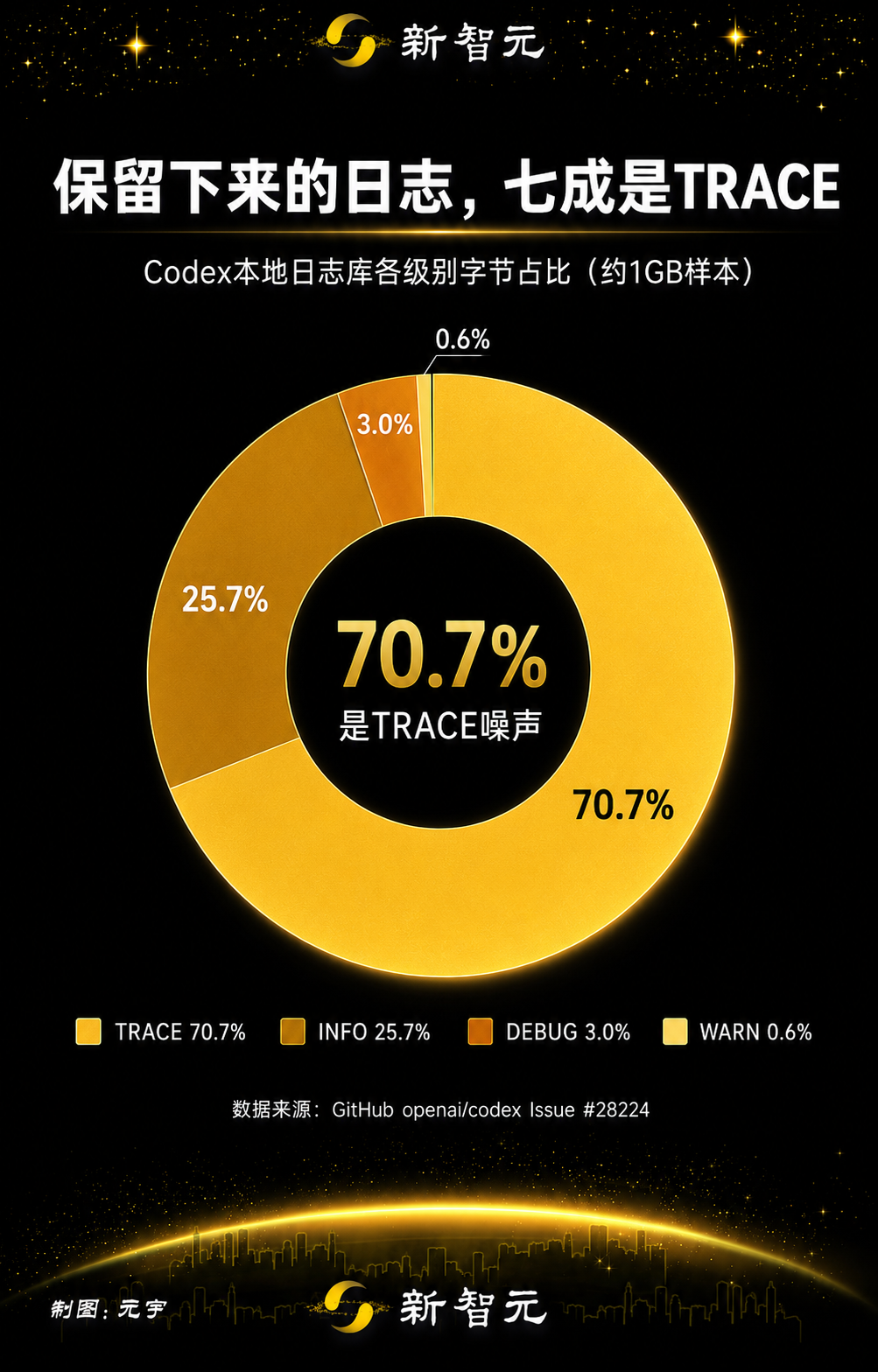
Но в этом пути приёмник журнала обратной связи SQLite использовал значение по умолчанию TRACE. TRACE — это самый подробный уровень, и он может захватывать низкоуровневые детали зависимостей, необработанную активность протокола и другой отладочный шум. В отчёте о проблеме утверждалось, что из-за этого значения по умолчанию локальная постоянная база данных журналов сохраняла гораздо больше, чем следовало.
Распределение сохранённых журналов показало, насколько доминирующим было содержимое уровня TRACE:
Уровень
Оценка, МиБ
Доля байтов
TRACE
732.5
70.7%
INFO
266.5
25.7%
DEBUG
30.6
3.0%
WARN
5.9
0.6%
В отчёте также отмечалось, что два зеркальных источника журналов, связанных с OpenTelemetry, codex_otel.log_only и codex_otel.trace_safe, составляли ещё одну значительную часть сохранённых байтов журналов. В этом образце автор отчёта оценил, что фильтрация этих «шумных» категорий могла бы удалить большую часть сохранённого объёма журналов без полного отключения журналов обратной связи.
Именно поэтому эта ошибка так раздражала разработчиков. Дело было не просто в том, что «вы забыли настроить логирование». Это больше походило на ситуацию: «вы попытались сократить объём логирования, но этот путь всё равно сохранял подробные журналы».
Это была не первая связанная проблема
В отчёте это не рассматривалось как единичный изолированный инцидент. В нём был перечислен ряд связанных проблем Codex, касающихся журналов SQLite, роста WAL, высокой дисковой активности, а также неограниченного или чрезмерного локального логирования.
Некоторые примеры, упомянутые в отчёте, включали:
Проблема
Заявленная тема
#17320
Чрезмерные записи SQLite WAL во время потоковой передачи, поскольку журналы TRACE игнорировали RUST_LOG
#24275
Рост настольного logs_2.sqlite / WAL при обычном использовании
#22444
Файлы WAL остаются выделенными или неожиданно увеличиваются
#26374
Рост журнала отзывов SQLite без достаточного срока хранения или ротации
#27911
Усиление записи в небольшой базе данных SQLite
#20563
Высокая нагрузка ввода-вывода от простаивающих процессов Codex
#27020
100% активного времени диска в Windows / WSL2
Инструменты ИИ для программирования всё чаще воспринимаются как постоянно включённые партнёры по разработке. Они читают файлы, отслеживают репозитории, поддерживают сеансы активными, собирают телеметрию и сохраняют контекст. Поэтому бюджеты локального диска, памяти и CPU становятся столь же важными, как бюджеты токенов и качество модели.
Исправления были объединены, но дискуссия не закончилась
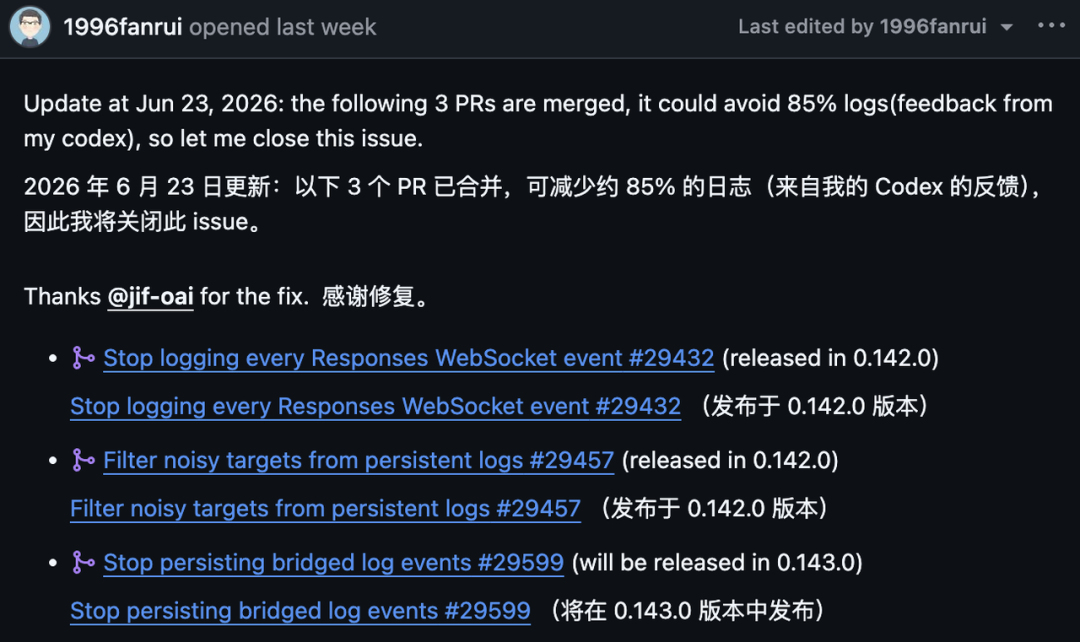
Позже в issue на GitHub было добавлено обновление, в котором говорилось, что три pull request были объединены, а собственный отзыв автора отчёта о Codex указывал на предполагаемое сокращение логов на 85%.
В issue эти три исправления были перечислены так:
Pull Request
Назначение
Примечание к выпуску в Issue
#29432
Прекратить логирование каждого события Responses WebSocket
Выпущено в 0.142.0
#29457
Отфильтровать шумные цели из постоянных логов
Выпущено в 0.142.0
#29599
Прекратить сохранение перенаправленных событий логов
Запланировано для 0.143.0
Сокращение на 85% — это существенно, но это не то же самое, что доказать наличие у локального логирования жесткого долгосрочного лимита на запись. Именно из-за этого различия обсуждение продолжилось. Разработчики спрашивали не только о том, была ли уменьшена именно эта ошибка; они спрашивали, должны ли AI-агенты для программирования иметь более четкие ограничения для постоянной локальной телеметрии.
В issue на GitHub также был приведен простой обходной путь, которым поделился один из комментаторов. Он блокирует вставки в таблицу logs путем создания триггера SQLite:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"
Используйте такие обходные пути осторожно. Они могут сократить локальные записи логов, но также могут удалить диагностические данные, которые позже могут понадобиться службам поддержки или разработчикам. В целом обновление до исправленной версии и проверка текущего поведения логирования безопаснее, чем незаметное изменение базы данных приложения без понимания компромисса.
Битва инструментов для программирования сжигает не только SSD
Обсуждение быстро вышло за рамки одного лишь Codex. На Hacker News разработчики также подняли более широкие претензии к AI-инструментам для программирования: высокая загрузка GPU, большое потребление памяти, фоновая активность и крупные локальные отладочные логи.
Такая реакция вполне понятна. Современные ИИ-ассистенты для программирования уже не являются простыми утилитами командной строки. Многие из них ведут себя скорее как локальные агенты: они отслеживают проекты, взаимодействуют с удалёнными моделями, управляют контекстом, выполняют команды и сохраняют состояние между задачами. Такая мощь полезна, но она также создаёт новую категорию инженерной ответственности.
Инструмент может казаться «нормальным» в пользовательском интерфейсе, при этом незаметно потребляя ресурсы в фоновом режиме. Быстрые процессоры, большой объём памяти и современные NVMe-накопители могут долго скрывать проблемы. Приложение может не зависать. Диск может не заполняться. Терминал может по-прежнему отвечать. Но счётчики состояния оборудования могут показывать совсем другую картину.
Именно поэтому этот инцидент стал полезным кейсом для инструментов разработчика на базе ИИ. Возможности модели важны, но качество локальной эксплуатации тоже имеет значение. Агент для программирования, работающий на компьютере разработчика, нуждается в разумных настройках по умолчанию, ограничениях хранения, ротации логов и способе, позволяющем пользователям понимать, что он делает.
Часто задаваемые вопросы
В чём заключалась ошибка с SQLite-логами Codex?
Это была заявленная проблема логирования в Codex, при которой локальные SQLite-логи обратной связи могли создавать очень большие объёмы записей на диск. В отчёте на GitHub оценивалось около 640 ТБ записей в год при измеренном автором отчёта сценарии использования.
Почему небольшой файл logs_2.sqlite всё равно мог изнашивать SSD?
Ресурс SSD зависит от общего объёма данных, записанных с течением времени, а не только от текущего размера файла. База данных может многократно выполнять вставки, удаления, запись в WAL, checkpoint и обновление индексов, при этом по-прежнему выглядя небольшой на диске.
Что означает SQLite WAL в этом контексте?
WAL означает Write-Ahead Logging (журналирование с упреждающей записью). SQLite сначала записывает изменения в отдельный файл -wal, а позже переносит их обратно в основную базу данных через контрольные точки; это нормальное поведение, но оно может создавать большую активность, когда вставки и удаления происходят очень часто.
Какую роль сыграло журналирование TRACE?
TRACE — самый подробный уровень журналирования. В приведенном примере содержимое уровня TRACE составляло около 70,7% сохраненных байтов журналов, а в отчете утверждалось, что подробные журналы зависимостей и протоколов сохранялись по умолчанию.
Исправила ли OpenAI проблему журналирования Codex?
В обновлении issue на GitHub говорилось, что были объединены три PR, при этом автор отчета оценил, что на основе отзывов о своем использовании Codex они могут избежать примерно 85% журналов. Два исправления были указаны как выпущенные в 0.142.0, тогда как третье было указано как запланированное для 0.143.0.
Следует ли пользователям вручную удалять или блокировать журналы Codex?
К ручным изменениям следует относиться осторожно, поскольку они могут удалить диагностическую информацию и иметь побочные эффекты. Более безопасный первый шаг — обновить Codex, проверить файлы журналов и отслеживать счетчики записи SSD, если вас это беспокоит.
Это проблема только Codex?
Этот конкретный отчет был посвящен Codex. Однако более широкая проблема относится к локальным ИИ-агентам в целом: постоянно работающим инструментам нужны четкие бюджеты ресурсов для диска, CPU, памяти, телеметрии и сохраняемых журналов.