
최근 Codex 로깅 문제로 인해 조용하던 로컬 데이터베이스가 예상외로 SSD에 많은 쓰기를 발생시키는 원인이 되었습니다. 원래 GitHub 보고서에 따르면, Codex의 SQLite 피드백 로그는 보고된 사용 패턴에서 연간 약 640TB를 쓸 수 있었습니다. 약 600TBW 등급의 소비자용 SSD 기준으로 보면, 이 수치는 단순히 조금 번거로운 수준이 아니라 드라이브의 보증 쓰기 내구성에 가까운 수준입니다.
이상한 점은 로그 데이터베이스가 크게 보이지 않았다는 것입니다. 파일은 약 1기가바이트 정도에 머물 수 있었지만, 실제 누적 쓰기 기록은 백그라운드에서 계속 쌓이고 있었습니다. 그래서 이 버그가 큰 주목을 받았습니다. 디스크를 눈에 띄게 가득 채우지는 않았지만, 여전히 쓰기 사이클을 빠르게 소모할 수 있었기 때문입니다.

출처 참고: 이 글은 신즈위안 보고서를 BAAI Hub가 재게시한 내용을 기반으로 하며, 공개 GitHub 이슈와 Hacker News 토론을 교차 확인했습니다. 원문 페이지의 브랜드 로고, QR 코드, 팔로우 안내, 관련 없는 장식 이미지는 포함하지 않았습니다.
640TB의 SSD 쓰기가 어떻게 발생할 수 있는가
처음에는 이 수치가 과장된 것처럼 들리므로, 측정값부터 살펴보는 것이 도움이 됩니다.
GitHub 이슈에서 제보자는 약 21일의 가동 시간 후 주 SSD에 약 37TB가 기록되었다고 밝혔습니다. 이를 1년 전체로 환산하면 약 640TB가 됩니다. 주요 원인으로 의심된 것은 Codex의 로컬 SQLite 피드백 로그 데이터베이스였습니다.
Codex는 로컬 설정 디렉터리 아래의 파일에 쓰고 있었습니다:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shm동작은 단순히 “로그 파일이 끝없이 계속 커진다”는 것이 아니었습니다. 오히려 삽입-가지치기 루프에 더 가까워 보였습니다. Codex가 새 행을 삽입한 다음, 유지되는 행 수를 안정적으로 유지하기 위해 오래된 행을 삭제했습니다. 눈에 보이는 파일 크기는 비교적 안정적으로 유지되었지만, 드라이브는 여전히 반복적인 쓰기를 처리해야 했습니다.
보고서의 15초 샘플은 이 문제를 명확히 보여주었습니다:
지표 | 이전 | 이후 |
유지된 행 | 681,774 | 681,774 |
최대 행 ID | 5,003,347,015 | 5,003,383,226 |
즉, 보존된 행 수는 전혀 증가하지 않았음에도 15초 동안 약 36,211개 행이 삽입되었다는 뜻입니다. 데이터베이스는 겉으로는 안정적으로 보였지만, 내부에서는 쓰기 변동이 계속되고 있었습니다.
빈번한 로그 항목이 모두 가치가 높은 애플리케이션 이벤트였던 것도 아닙니다. 예시에는 inotify 이벤트와 같은 반복적인 파일 시스템 및 의존성 수준의 노이즈가 포함되어 있었습니다.
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")그 결과, 사용자에게는 평소와 다른 일이 벌어지고 있다는 눈에 띄는 신호를 거의 주지 않으면서도 저장소를 계속 다시 쓰는 로컬 로깅 시스템이 만들어졌습니다.
1GB 파일도 여전히 수백 테라바이트의 쓰기를 발생시킬 수 있습니다
이번 사건에서 가장 직관에 반하는 부분은 간단합니다. SSD 마모는 현재 파일 크기가 아니라 총 쓰기량의 문제라는 것입니다.
로컬 데이터베이스는 약 1GB 수준을 유지하면서도 애플리케이션이 그 일부를 반복적으로 쓰고, 정리하고, 인덱싱하고, 체크포인트를 만들고, 다시 쓸 수 있습니다. 저장소 상태 관점에서 중요한 것은 오늘 파일이 얼마나 커 보이는지만이 아닙니다. 시간이 지남에 따라 얼마나 많은 데이터가 쓰였는지가 중요합니다.
보고서에는 그 차이를 더 쉽게 확인할 수 있게 해 주는 스냅샷 하나가 포함되어 있었습니다.
지표 | 값 |
현재 | 1.2 GiB |
현재 보존된 행 수 | 506,149 |
할당된 총 행 ID 수 | 5,543,677,486 |
현재 데이터베이스에는 약 50만 행만 남아 있었지만, 자동 증가된 행 ID는 이미 55억을 넘어섰습니다. 이것이 쓰기 증폭 이야기의 핵심입니다. 오래된 행은 현재 데이터베이스 보기에서 사라질 수 있지만, 그것들을 생성한 디스크 쓰기는 이미 발생한 뒤입니다.
SQLite의 WAL, 즉 Write-Ahead Logging도 여기서 중요합니다. WAL 모드에서는 변경 사항이 기본 데이터베이스로 체크포인트되기 전에 별도의 -wal 파일에 추가됩니다. WAL은 정상적이고 유용한 SQLite 메커니즘이지만, 애플리케이션이 매우 빈번하게 삽입과 삭제를 수행하면 내부적으로 발생하는 디스크 활동량을 몇 배로 늘릴 수 있습니다.
쉽게 말하면, 노트북은 여전히 얇아 보이지만 같은 페이지들이 여러 번 쓰이고, 지워지고, 다시 쓰인 셈입니다.
근본 원인: 사용자가 기대한 대로 동작하지 않은 RUST_LOG 설정
보고서는 Codex 로깅 경로에서 특히 중요한 구성 세부 사항 하나를 지적했습니다.
Targets::new().with_default(Level::TRACE)Rust의 tracing 생태계에서는 로그 필터링이 보통 대상과 레벨을 통해 제어됩니다. 사용자는 RUST_LOG 환경 변수가 로그 상세 수준을 info, warn 또는 그보다 낮은 수준으로 줄이는 데 도움이 될 것이라고 합리적으로 기대할 수 있습니다.
하지만 이 경로에서 SQLite 피드백 로그 싱크는 기본값으로 TRACE를 사용했습니다. TRACE는 가장 상세한 레벨이며, 저수준 의존성 세부 정보, 원시 프로토콜 활동 및 기타 디버깅 잡음을 포착할 수 있습니다. 이 이슈 보고서는 이러한 기본값 때문에 로컬 영구 로그 데이터베이스가 필요한 것보다 훨씬 더 많은 내용을 계속 저장했다고 주장했습니다.
보존된 로그 분포는 TRACE 레벨 콘텐츠가 얼마나 지배적이었는지를 보여주었습니다.
레벨 | 예상 MiB | 바이트 비중 |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
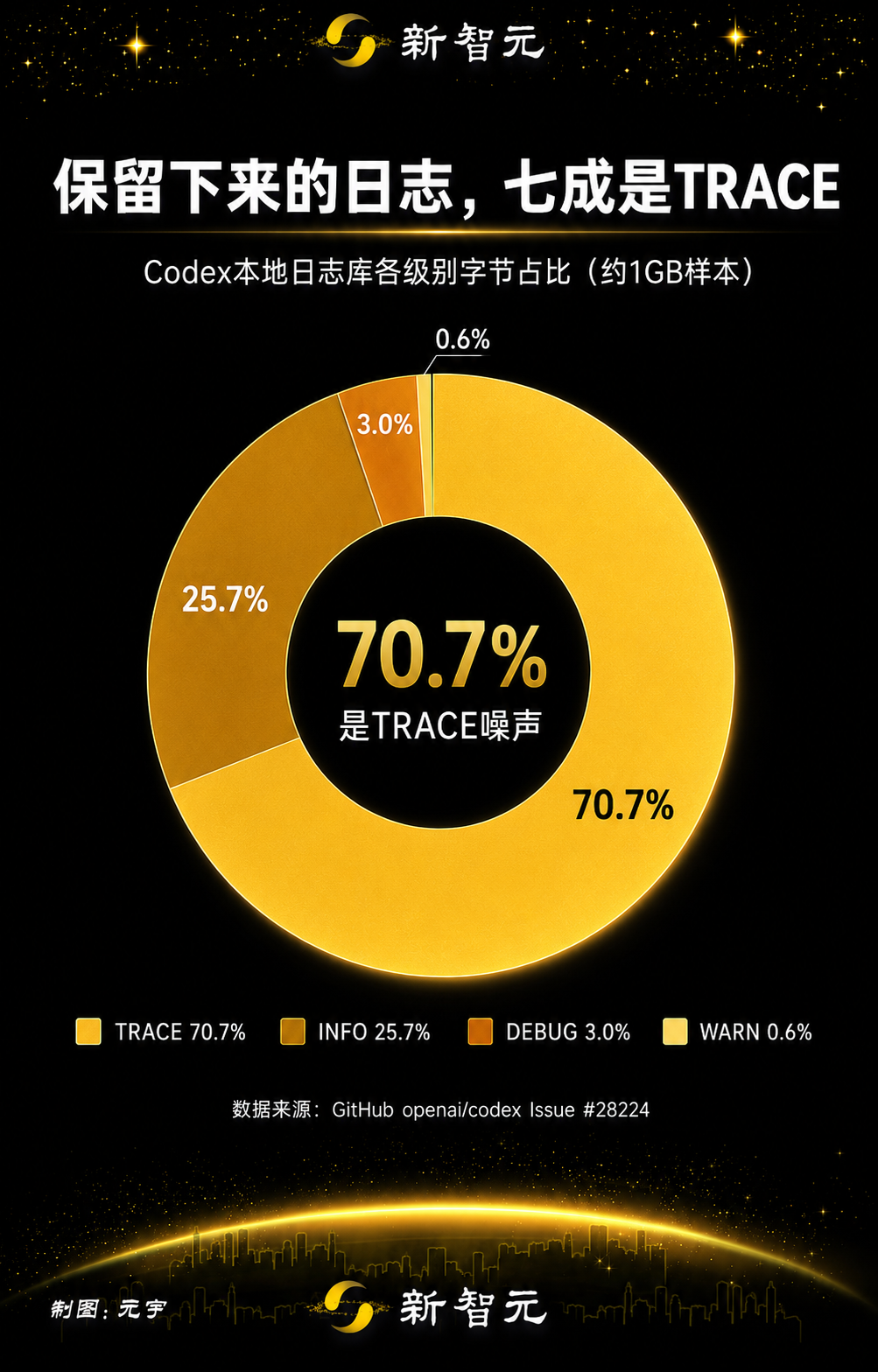
보고서는 또한 두 개의 미러링된 OpenTelemetry 관련 로그 소스인 codex_otel.log_only와 codex_otel.trace_safe가 보존된 로그 바이트의 또 다른 큰 부분을 차지했다고 지적했다. 해당 샘플에서 보고자는 이러한 노이즈가 많은 범주를 필터링하면 피드백 로그를 완전히 비활성화하지 않고도 보존된 로그 용량의 대부분을 제거할 수 있을 것으로 추정했다.
그래서 이 버그는 개발자들에게 매우 답답하게 느껴졌다. 단순히 “로깅 구성을 깜빡했다”는 문제가 아니었다. 오히려 “로깅을 줄이려고 했지만, 이 경로는 여전히 상세 로그를 계속 저장했다”는 것에 더 가까워 보였다.
이것이 첫 번째 관련 문제는 아니었다
보고서는 이를 단일한 고립된 사고로 취급하지 않았다. SQLite 로그, WAL 증가, 과도한 디스크 활동, 그리고 제한 없거나 과도한 로컬 로깅과 관련된 Codex 문제들을 묶어 나열했다.
보고서에서 언급된 몇 가지 예는 다음과 같다:
이슈 | 보고된 주제 |
|
|
| 일반 사용 중 데스크톱 |
| WAL 파일이 할당된 상태로 남아 있거나 예기치 않게 증가함 |
| 충분한 보존 또는 순환 없이 피드백 로그 SQLite가 증가함 |
| 작은 SQLite 데이터베이스에서 쓰기 증폭 발생 |
유휴 Codex 프로세스의 과도한 I/O | |
| Windows / WSL2에서 디스크 활성 시간이 100% |
AI 코딩 도구는 점점 더 항상 켜져 있는 개발 파트너처럼 여겨지고 있습니다. 파일을 읽고, 저장소를 감시하며, 세션을 유지하고, 텔레메트리를 수집하며, 컨텍스트를 보존합니다. 따라서 로컬 디스크, 메모리, CPU 예산은 토큰 예산과 모델 품질만큼이나 중요합니다.
수정 사항은 병합되었지만 논쟁은 끝나지 않았습니다
GitHub 이슈에는 이후 세 개의 풀 리퀘스트가 병합되었으며, 제보자 자신의 Codex 피드백에 따르면 로그가 약 85% 감소한 것으로 추정된다는 업데이트가 추가되었습니다.
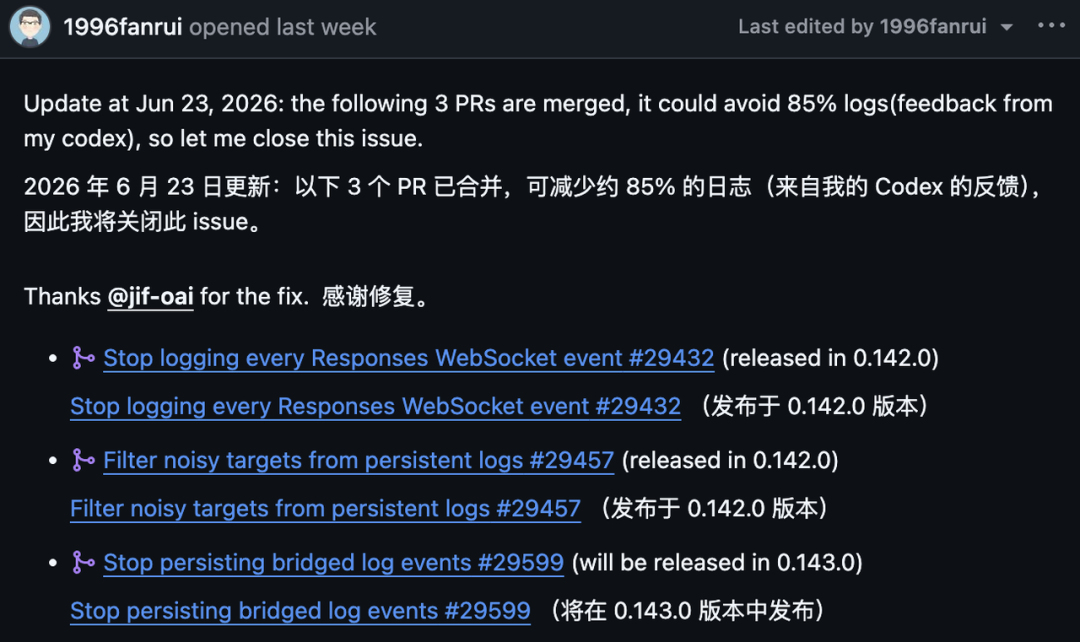
이 이슈는 세 가지 수정 사항을 다음과 같이 나열했습니다.
풀 리퀘스트 | 목적 | 이슈의 릴리스 노트 |
| 모든 Responses WebSocket 이벤트 로깅 중지 |
|
| 영구 로그에서 노이즈가 많은 대상 필터링 |
|
| 브리지된 로그 이벤트 영구 저장 중지 |
|
85% 감소는 상당한 수준이지만, 로컬 로깅에 이제 장기적인 하드 쓰기 예산이 있다는 것을 입증하는 것과는 다릅니다. 바로 이 차이 때문에 논의가 계속되었습니다. 개발자들은 이 특정 버그가 줄어들었는지만 묻고 있었던 것이 아니라, AI 코딩 에이전트가 지속적인 로컬 텔레메트리에 대해 더 명확한 한계를 가져야 하는지도 묻고 있었습니다.
GitHub 이슈에는 한 댓글 작성자가 공유한 간단한 우회 방법도 포함되어 있었습니다. 이 방법은 SQLite 트리거를 생성하여 logs 테이블에 삽입되는 것을 차단합니다:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"이와 같은 우회 방법은 신중하게 사용하세요. 로컬 로그 쓰기를 줄일 수는 있지만, 지원팀이나 개발자가 나중에 필요로 할 수 있는 진단 데이터도 제거할 수 있습니다. 일반적으로는 절충점을 이해하지 못한 채 애플리케이션 데이터베이스를 조용히 수정하는 것보다, 수정된 버전으로 업데이트하고 현재 로그 동작을 확인하는 것이 더 안전합니다.
코딩 도구 경쟁은 SSD만 태우고 있는 것이 아닙니다
논의는 곧 Codex만의 문제를 넘어섰습니다. Hacker News에서 개발자들은 AI 코딩 도구에 대한 더 광범위한 불만도 제기했습니다. 높은 GPU 사용량, 과도한 메모리 소비, 백그라운드 활동, 대용량 로컬 디버그 로그 등이었습니다.

그런 반응은 이해할 만합니다. 최신 AI 코딩 어시스턴트는 더 이상 단순한 명령줄 유틸리티가 아닙니다. 그중 다수는 로컬 에이전트에 더 가깝게 동작합니다. 프로젝트를 감시하고, 원격 모델과 통신하며, 컨텍스트를 관리하고, 명령을 실행하며, 작업 전반에 걸쳐 상태를 유지합니다. 이러한 능력은 유용하지만, 엔지니어링 책임의 새로운 범주도 만들어냅니다.
도구는 사용자 인터페이스에서는 “문제없어” 보이면서도 백그라운드에서 조용히 리소스를 소비할 수 있습니다. 빠른 CPU, 대용량 메모리, 최신 NVMe 드라이브는 오랫동안 문제를 숨길 수 있습니다. 앱이 멈추지 않을 수도 있습니다. 디스크가 가득 차지 않을 수도 있습니다. 터미널도 계속 응답할 수 있습니다. 하지만 하드웨어 상태 카운터는 다른 이야기를 들려줄 수 있습니다.
이것이 바로 이 사건이 AI 개발자 도구에 유용한 사례 연구가 된 이유입니다. 모델 성능도 중요하지만, 로컬 운영 품질 역시 중요합니다. 개발자 컴퓨터에서 실행되는 코딩 에이전트에는 합리적인 기본 설정, 보존 한도, 로그 로테이션, 그리고 사용자가 그것이 무엇을 하고 있는지 이해할 수 있는 방법이 필요합니다.
FAQ
Codex SQLite 로그 버그는 무엇이었나요?
로컬 SQLite 피드백 로그가 매우 많은 양의 디스크 쓰기를 생성할 수 있다는 보고된 Codex 로깅 문제였습니다. GitHub 보고서는 제보자의 측정된 사용 패턴을 기준으로 연간 약 640TB의 쓰기가 발생할 것으로 추정했습니다.
작은 logs_2.sqlite 파일이 어떻게 SSD를 마모시킬 수 있나요?
SSD 내구성은 현재 파일 크기만이 아니라 시간에 따른 총 쓰기 데이터량에 따라 달라집니다. 데이터베이스는 디스크에서 작게 보이는 상태를 유지하면서도 반복적으로 삽입, 삭제, WAL 쓰기, 체크포인트 수행, 인덱스 업데이트를 할 수 있습니다.
이 맥락에서 SQLite WAL은 무엇을 의미하나요?
WAL은 Write-Ahead Logging의 약자입니다. SQLite는 변경 사항을 먼저 별도의 -wal 파일에 기록한 뒤 나중에 이를 메인 데이터베이스로 체크포인트합니다. 이는 정상적인 동작이지만 삽입과 삭제가 매우 자주 발생할 경우 많은 활동을 유발할 수 있습니다.
TRACE 로깅은 어떤 역할을 했나요?
TRACE는 가장 상세한 로그 수준입니다. 보고된 샘플에서 TRACE 수준 콘텐츠는 보존된 로그 바이트의 약 70.7%를 차지했으며, 해당 이슈에서는 자세한 의존성 및 프로토콜 로그가 기본적으로 저장되고 있다고 주장했습니다.
OpenAI는 Codex 로깅 문제를 해결했나요?
GitHub 이슈 업데이트에 따르면 세 개의 PR이 병합되었으며, 제보자는 자신의 Codex 사용에 대한 피드백을 바탕으로 약 85%의 로그를 피할 수 있을 것으로 추정했습니다. 두 가지 수정 사항은 0.142.0에서 릴리스된 것으로 표시되었고, 세 번째는 0.143.0에서 예정된 것으로 표시되었습니다.
사용자가 Codex 로그를 수동으로 삭제하거나 차단해야 하나요?
수동 변경은 진단 정보를 제거할 수 있고 부작용이 있을 수 있으므로 신중하게 다뤄야 합니다. 우려된다면 먼저 Codex를 업데이트하고, 로그 파일을 검사하며, SSD 쓰기 카운터를 모니터링하는 것이 더 안전한 첫 단계입니다.
이것은 Codex만의 문제인가요?
이 특정 보고서는 Codex에 초점을 맞췄습니다. 그러나 더 넓은 우려는 로컬 AI 에이전트 전반에 적용됩니다. 항상 켜져 있는 도구에는 디스크, CPU, 메모리, 텔레메트리, 보존 로그에 대한 명확한 리소스 예산이 필요합니다.
관련 도구
OpenAI Codex GitHub 저장소: Codex CLI 및 관련 소스 코드를 위한 공개 저장소입니다.
SQLite: 많은 로컬 애플리케이션과 도구에서 사용되는 임베디드 데이터베이스 엔진입니다.
SQLite Write-Ahead Logging 문서: WAL이 어떻게 작동하는지와 체크포인팅이 왜 중요한지를 설명하는 공식 문서입니다.
Rust tracing: Codex 이슈에서 논의된 Rust의 구조화된 로깅 및 진단 프레임워크입니다.
smartmontools: 지원되는 드라이브에서 SSD 쓰기 카운터를 포함한 SMART 저장 장치 상태 데이터를 확인하기 위한 도구 모음입니다.
Hacker News: Codex 로깅 보고서가 더 넓은 개발자들의 관심을 끈 토론 플랫폼입니다.
관련 링크
Codex SQLite 피드백 로그 이슈 #28224: 보고된 연간 640TB 쓰기 추정치와 증거를 문서화한 주요 GitHub 이슈입니다.
모든 Responses WebSocket 이벤트 로깅 중지 #29432: 로깅 감소 작업의 일부로 나열된 병합된 PR 중 하나입니다.
영구 로그에서 잡음이 많은 대상 필터링 #29457: 잡음이 많은 영구 로깅 대상을 필터링하는 데 초점을 맞춘 PR입니다.
브리지된 로그 이벤트 영구 저장 중지 #29599: 브리지된 종속성 로그 이벤트가 영구 저장되지 않도록 하는 것을 목표로 한 후속 PR입니다.
Hacker News 토론: Codex 로깅, SSD 쓰기, AI 코딩 도구 품질을 둘러싼 커뮤니티 토론입니다.
OpenAI Codex CLI README: Codex CLI 설치 및 실행을 위한 공식 저장소 README입니다.
SQLite WAL 문서: WAL 파일, 체크포인트 및 성능 고려 사항에 대한 공식 설명입니다.


