

Die Kurzfassung: Das ist nicht einfach nur „ein etwas intelligenteres Modell“
Das Nützlichste am ursprünglichen Artikel ist, dass er Composer 2.5 nicht als vages Upgrade beschreibt. Er behandelt es eher wie einen Bericht über Training und Produkt.
Das ist wichtig, denn die eigentliche Geschichte lautet:
Composer 2.5 verbessert sich nicht nur wegen seines Basis-Checkpoints, sondern weil Cursor gleichzeitig an Trainingsmethode, Datenumfang, Optimizer-Engineering und Produktform gearbeitet hat.
Das ist eine deutlich interessantere Aussage als „das Modell ist besser geworden“.
Was Composer 2.5 tatsächlich ist
Der Artikel macht gleich zu Beginn einen klaren Punkt:
Composer 2.5 ist jetzt in Cursor verfügbar.
Er betont außerdem, dass es sich nicht um ein völlig neues Basismodell handelt. Composer 2.5 basiert weiterhin auf derselben offenen Checkpoint-Familie wie Composer 2, nämlich Moonshots Kimi K2.5.
Damit lautet die zentrale Frage:
Wie weit kann Cursor einen agentenartigen Coding-Workflow auf Basis eines starken offenen Checkpoints treiben?
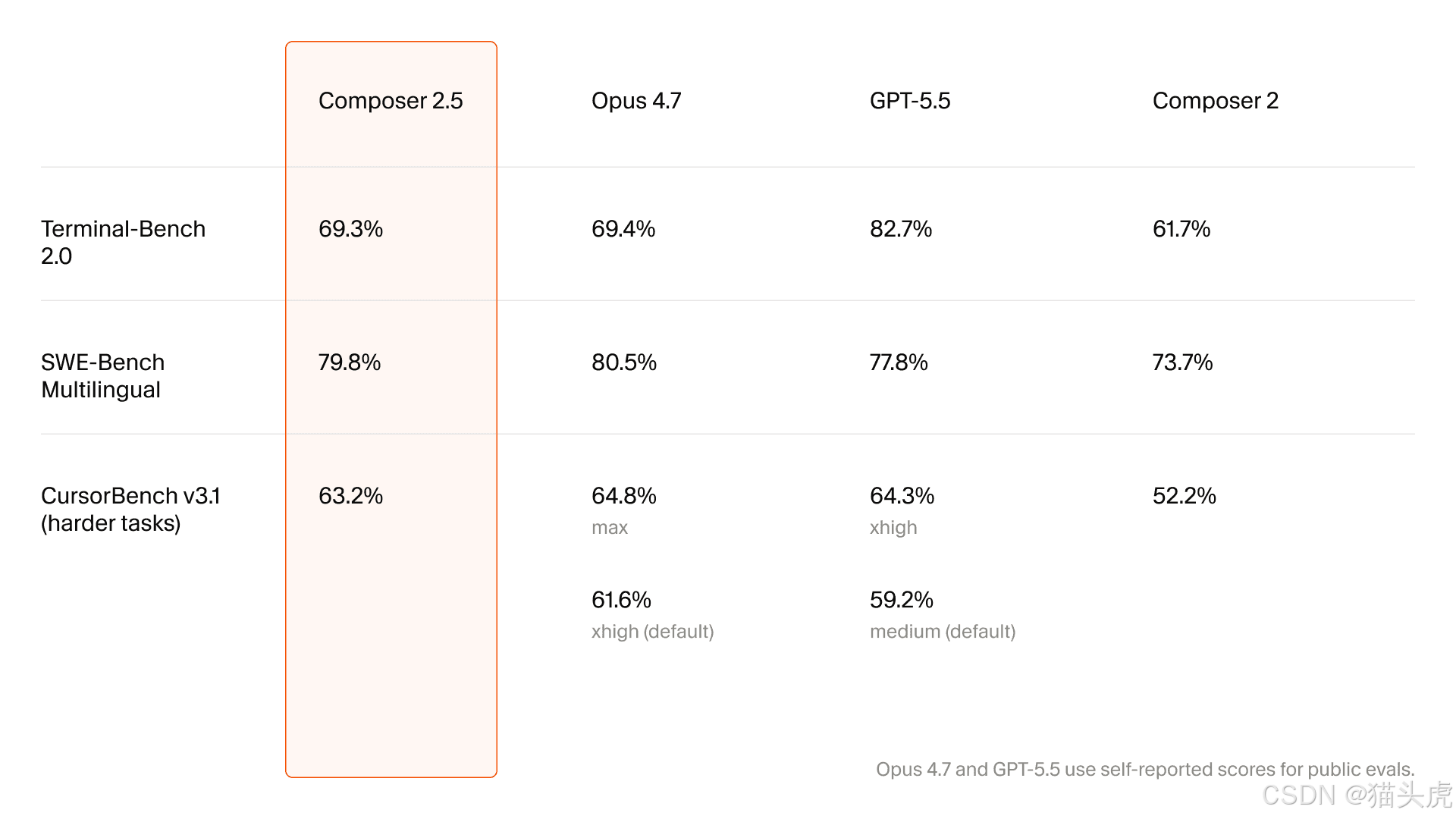
Die Upgrade-Matrix konzentriert sich auf lange Aufgaben, Zuverlässigkeit und Zusammenarbeit
Die erste große Tabelle des Artikels vergleicht Composer 2 mit 2.5:
Dimension | Composer 2 | Composer 2.5 | Gemeldeter Zugewinn |
Ausdauer bei langen Aufgaben | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Befolgen komplexer Anweisungen | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Reibungslosigkeit der Zusammenarbeit | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Konsistenz des Coding-Stils | durchschnittlich | deutlich verbessert | grundlegender Wandel |
Kommunikationskalibrierung | durchschnittlich | deutlich verbessert | grundlegender Wandel |
Genauigkeit von Tool-Aufrufen | mittel | hoch | großer Zugewinn |
Fehlerbehebung | schwächer | stark | grundlegender Wandel |
Wichtig ist nicht irgendein einzelner Prozentsatz. Entscheidend ist die Art der Kategorien:
lang laufende Aufgaben
komplexe Anweisungen
reibungsloses Zusammenarbeiten
Stilkonsistenz
Wiederherstellungsverhalten
Cursor versucht damit, Composer eher wie einen belastbaren Teamkollegen wirken zu lassen, nicht nur wie einen schnellen Code-Vervollständiger.
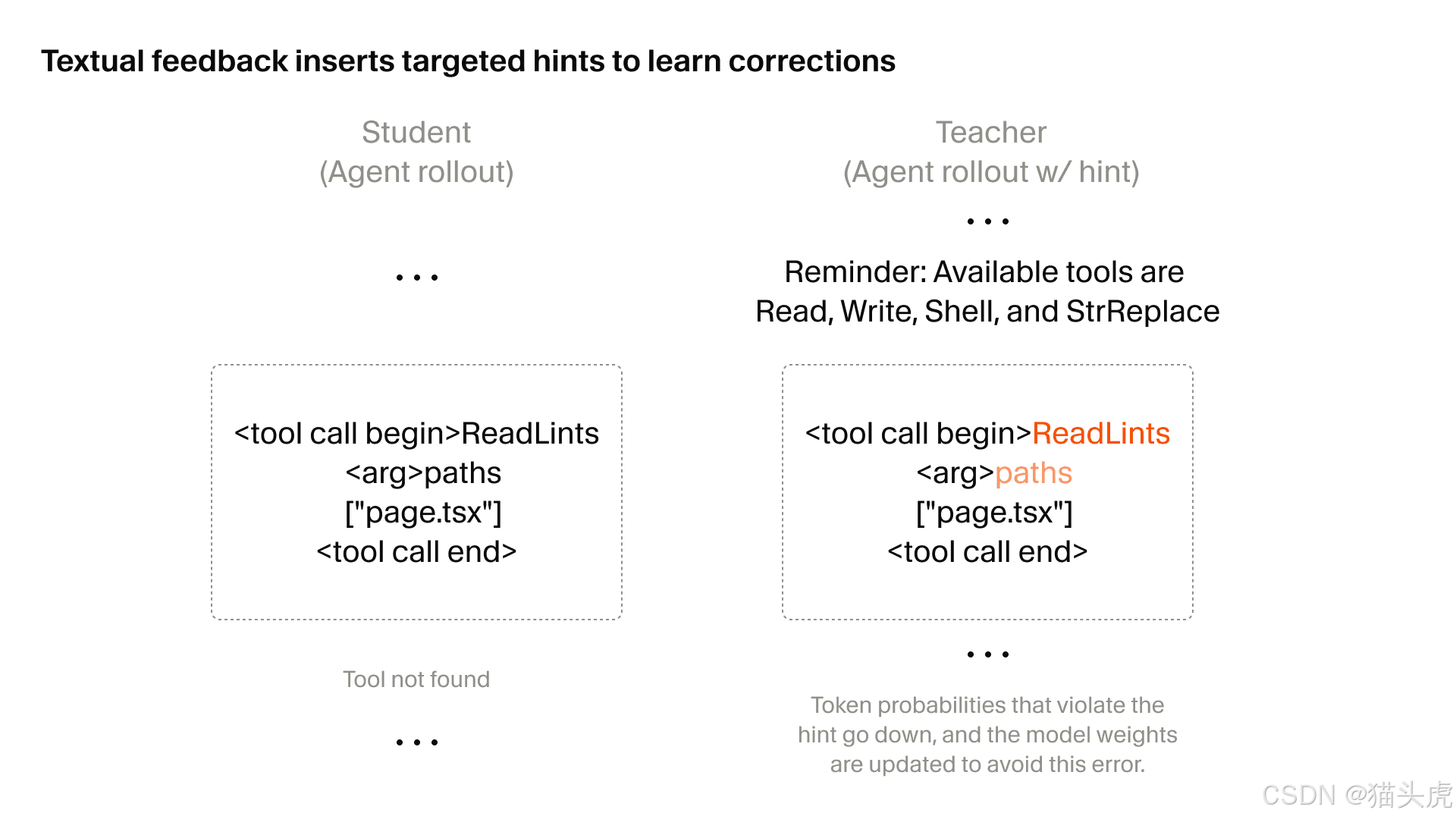
Der erste technische Sprung: gerichtetes RL mit Text-Feedback
Der erste tiefgehende technische Abschnitt des Artikels handelt von gerichtetem RL mithilfe von Text-Feedback.
Das Problem, das damit gelöst werden soll, ist bekannt: Sobald Rollouts extrem lang werden, wird die Credit Assignment im traditionellen RL unübersichtlich.
Das Modell weiß möglicherweise, ob das Gesamtergebnis gut oder schlecht war, aber nicht unbedingt, welche lokale Entscheidung genau dieses Ergebnis verursacht hat.
Das wird besonders problematisch, wenn man sehr spezifische lokale Verhaltensweisen unterdrücken möchte, wie etwa:
falsche Tool-Aufrufe
verwirrende Erklärungen
Stildrift
schwache Ausrichtung auf den Gesprächskontext
Traditionelles RL vs. gerichtetes RL mit Text-Feedback
Vergleich | Traditionelles RL | Gerichtetes RL mit Text-Feedback |
Feedback-Granularität | global | lokal |
Credit Assignment | verrauscht | präzise |
Optimierung lokalen Verhaltens | schwierig | effizient |
Trainingssignal | spärlich | dicht |
Am besten geeigneter Aufgabentyp | einfachere Aufgaben | lange, komplexe Aufgaben |
Die Kernidee ist einfach:
Wenn ein bestimmter Schritt besser hätte sein können, wird das Feedback direkt diesem Schritt zugeordnet.
Dadurch wird aus einer vagen Strafe am Ende eines Rollouts eher eine gezielte Verhaltenskorrektur.
Der zweite Sprung: 25-fache Skalierung synthetischer Aufgaben
Das zweite große Thema ist die drastische Ausweitung synthetischer Aufgaben.
Dem Artikel zufolge verwendete Composer 2.5 etwa 25-mal mehr synthetische Aufgaben als Composer 2.
Das ist wichtig, denn sobald ein Modell leistungsfähiger wird, fordern statische Aufgabenpools es nicht mehr ausreichend heraus. Auch die Trainingsdaten müssen schwieriger und dynamischer werden.
Skalenvergleich synthetischer Daten
Kennzahl | Composer 2 | Composer 2.5 | Wachstum |
Synthetische Aufgaben | Basiswert | 25x Basiswert | 25x |
Schwierigkeitsanpassung | statisch | dynamisch | sprunghafte Veränderung |
Abdeckung realer Codebasen | begrenzt | deutlich breiter | großer Zugewinn |
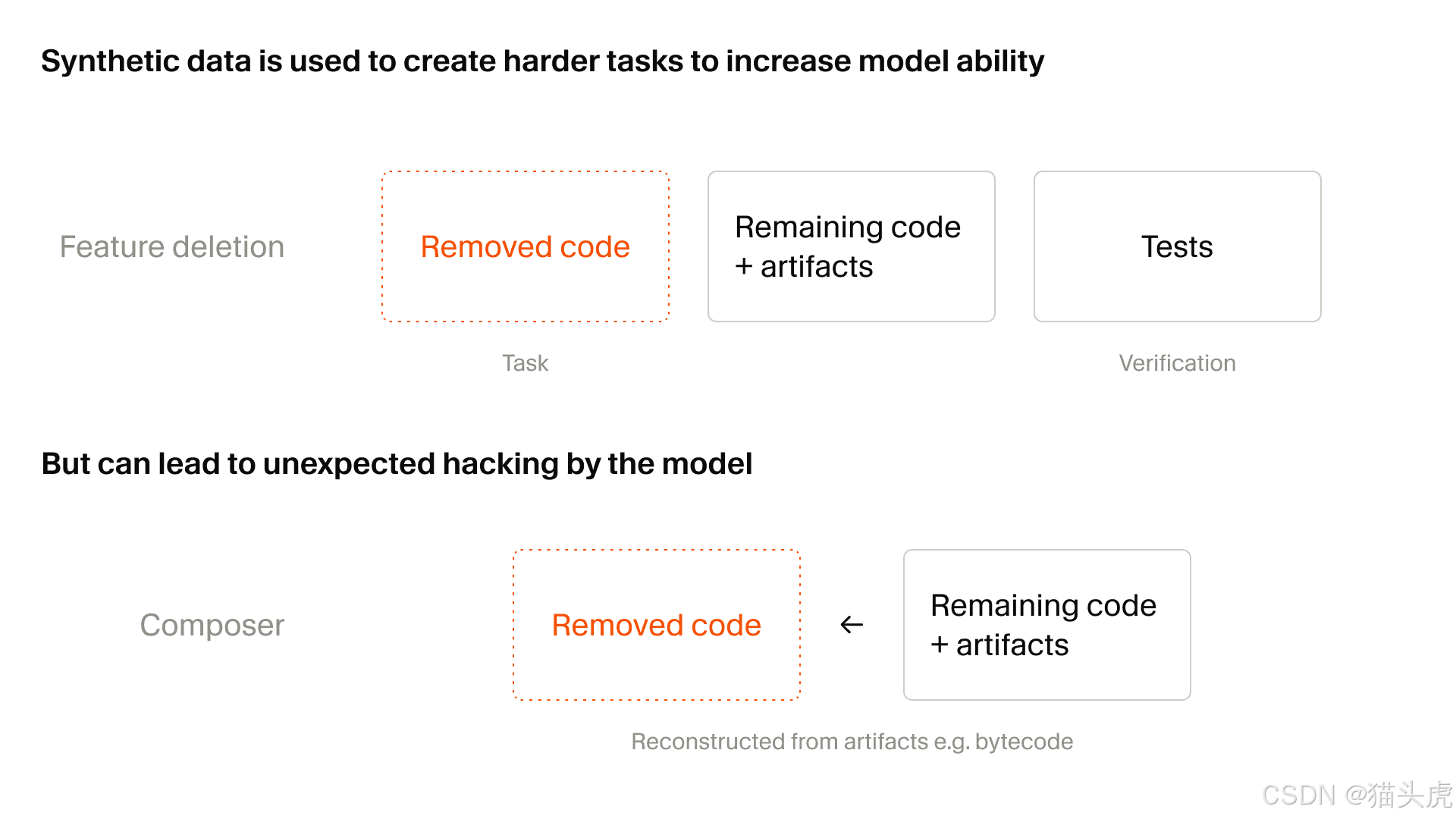
Eine besonders nützliche Methode, die in dem Artikel beschrieben wird, ist die Feature-Entfernung:
eine reale Codebasis mit Tests nehmen
eine bestimmte Fähigkeit entfernen
das Repository lauffähig halten
das Modell bitten, die fehlende Funktionalität wiederherzustellen
die Tests als Belohnungssignal verwenden
Das passt besonders gut zu Coding-Agenten, weil es sie auf Verhalten trainiert, das realer Entwicklungsarbeit viel näher kommt:
Funktionalität wiederherstellen
über Struktur nachdenken
unter Testvorgaben arbeiten
innerhalb bestehender Projekte arbeiten
Der Artikel weist auch auf den Nachteil hin: Reward Hacking wird zu einem ernsteren Problem, wenn die Erzeugung synthetischer Aufgaben skaliert.
Der dritte Sprung: Bei Muon, Sharding und HSDP geht es darum, das Ganze trainierbar zu machen
Wenn es in den ersten beiden Abschnitten darum geht, was trainiert werden soll und wie Verhalten gelenkt wird, geht es im dritten Abschnitt darum, wie dieses Trainingssystem tatsächlich zum Laufen gebracht wird.
Hier behandelt der Artikel:
den Muon-Optimizer
Sharded Muon
Dual-Grid-HSDP
Erstelle in Minuten eine Showcase-Website und gewinne Leads
Beschreibe deine Idee einmal, und We0 AI erstellt eine Showcase-Website, Seiten und ein CMS und hilft nach dem Launch bei Kunden und Traffic.
Eine komplette Projektgeneration zur kostenlosen Registrierung
Am besten geeignet, um einen vollständigen Generierungsablauf auszuprobieren und schnell einen ersten Projektentwurf zu sehen.
Die meisten Leser brauchen nicht jedes Systemdetail. Der zentrale Punkt reicht aus:
Längere Rollouts, größere Pools synthetischer Aufgaben und granulareres Verhaltensfeedback erfordern alle eine stärkere Trainingsinfrastruktur.
Die Architekturperspektive: Cursor baut eine vollständige Coding-Agenten-Pipeline
Der Artikel zoomt schließlich wieder heraus und zeigt ein Bild auf Systemebene.
Die eigentliche Erkenntnis ist, dass Cursor nicht nur versucht, ein besseres Antwortmodell auszuliefern. Es stellt einen End-to-End-Stack zusammen aus:
offenen Checkpoints
RL-Methoden
synthetischen Aufgaben
parallelen Trainingssystemen
Differenzierung nach Produktstufen
bis hinein in die IDE-Erfahrung.
Deshalb wirkt Composer 2.5 substanzieller als ein oberflächlicher Versionssprung.
Preisgestaltung und der Fast-Tier zeigen die Produktstrategie
Der Abschnitt zur Preisgestaltung ist einer der nützlichsten praktischen Teile des Artikels.
Preistabelle
Stufe | Preis für Eingabe-Token | Preis für Ausgabe-Token | Relative Kosten | Positionierung |
Standard | 0,50 $ / Million | 2,50 $ / Million | Ausgangswert | volle Intelligenz, starkes Preis-Leistungs-Verhältnis |
Schnell | 3,00 $ / Million | 15,00 $ / Million | 6x |
Kostenvergleich der Schnellstufe
Modell | Eingabe / Million | Ausgabe / Million | Intelligenz | Wert |
Composer 2.5 Fast | 3,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | 5,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | 3,00 $ | 15,00 $ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | 3,50 $ | 10,50 $ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Der Artikel weist außerdem auf zwei Produktdetails hin:
Schnell ist die Standardeinstellung
in der ersten Woche gibt es doppelte Nutzung
Das sagt viel über Cursors Produktthese aus. Es wird nicht nur ein Modell verkauft. Verkauft wird eine funktionierende Entwicklungsoberfläche, die sich schnell und zuverlässig anfühlt.
Die Zusammenarbeit mit SpaceXAI ist der kühnste zukunftsgerichtete Teil
Der abschließende zukunftsgerichtete Abschnitt wendet sich der nächsten Generation des Trainings zu.
Der Artikel beschreibt die Zusammenarbeit so:
10-fache Gesamt-Rechenleistung
1 Million H100-äquivalente Kapazität
Infrastruktur auf Basis von Colossus 2
eine Verlagerung von checkpoint-basiertem Finetuning hin zu stärker vollständig selbstgesteuertem Training
Planungstabelle für die nächste Generation
Metrik | Aktuell (Composer 2.5) | Nächste Generation | Gemeldeter Sprung |
Gesamt-Rechenleistung | 1x | 10x | 10x |
H100-äquivalente Kapazität | Ausgangsbasis | 1 Million | Sprung um eine Größenordnung |
Infrastruktur | bestehende Cluster | Colossus 2 | neue Architektur |
Trainingsansatz | Finetuning von offenem Checkpoint | stärker vollständig selbst trainiert | grundlegender Wandel |
Das ist offensichtlich auch Teil der breiteren Erzählung des Unternehmens, weist aber in eine klare Richtung:
Cursor möchte nicht nur eine dünne IDE-Schicht auf dem Modell eines anderen bleiben.
Warum das für Teams im We0-Stil wichtig ist
Man kann eine Geschichte wie diese leicht lesen und denken, dass sie nur für Entwickler relevant ist.
Aber stärkere Coding-Agenten beeinflussen auch:
Prototyping-Geschwindigkeit
Geschwindigkeit der Frontend-Ausgabe
Produktion von Launch-Seiten
Erstellung von Fallstudien- und Showcase-Assets
Reibungsverluste bei der Übergabe zwischen Engineering und Wachstum
Deshalb beschreibt We0 AI die Wertschöpfungskette immer wieder als:
Build -> Showcase -> Grow -> Leads
Wenn Coding-Agenten bei langen Aufgaben, Koordination und produktionsreifen Ergebnissen besser werden, bewegt sich die gesamte Kette schneller.
Fazit
Die sinnvollste Art, dieses Upgrade zu verstehen, ist nicht als einzelner isolierter Trick.
Es lässt sich besser so verstehen:
Composer 2.5 steht dafür, dass Cursor gleichzeitig sowohl den Trainings-Stack als auch die Produktform eines Coding-Agenten weiterentwickelt.
Das macht es interessanter als eine oberflächliche Modellauffrischung.
Verwandte Artikel
Verwandte Tools
Quellen

