
这篇文章最有价值的地方,不是简单告诉你 Claude Code 又多了一个新功能 ,而是把 Dynamic Workflows 到底解决什么问题、为什么重要、它会把 AI 编程带到哪一步 讲得非常透。
如果你以前把 Claude Code 理解成一个会读文件、会跑命令、会改代码的终端助手,那么 Dynamic Workflows 会逼着你把它往前再想一步。它不是在原来那套 Agent 机制上再加一点补丁,而是在重新定义一件事: 当任务大到一轮对话根本装不下时,AI 到底该怎么继续工作。
原文给出的答案很直接: 别再把所有编排都压在 Claude 的上下文里了,干脆让 Claude 先把编排过程写成一段脚本。
Dynamic Workflows 原文封面图
Dynamic Workflows 真正改变了什么
它解决的不是“会不会做”,而是“怎么把大任务组织起来”
原文一开头就用 Bun 的迁移案例把问题打透了。 11 天、约 75 万行 Rust、99.8% 的原有测试通过 ,这不是一个“帮我改个函数”的量级,而是一个已经明显超出单个 Agent 稳定处理范围的工程任务。
作者抓得很准。 Dynamic Workflows 瞄准的从来不是小活 ,而是那些单个 Agent 一次跑不完、就算能跑也很容易把上下文挤爆的任务。比如整个服务范围的 bug 排查、动辄上百个文件的迁移、需要从多个角度压力测试的方案评估,这些任务的共同特点不是单步难,而是 编排难 。
过去的 Claude Code,在任务不太大时其实已经很好用。一个主 Agent 可以自己想下一步、派几个 subagent 去搜文件、读代码、跑命令,再把结果收回来继续判断。 但任务规模一旦上去,这个模式就会开始吃力 ,因为每个 subagent 的结果都要回到 Claude 的上下文里,最后主 Agent 反而会被过程信息淹没。
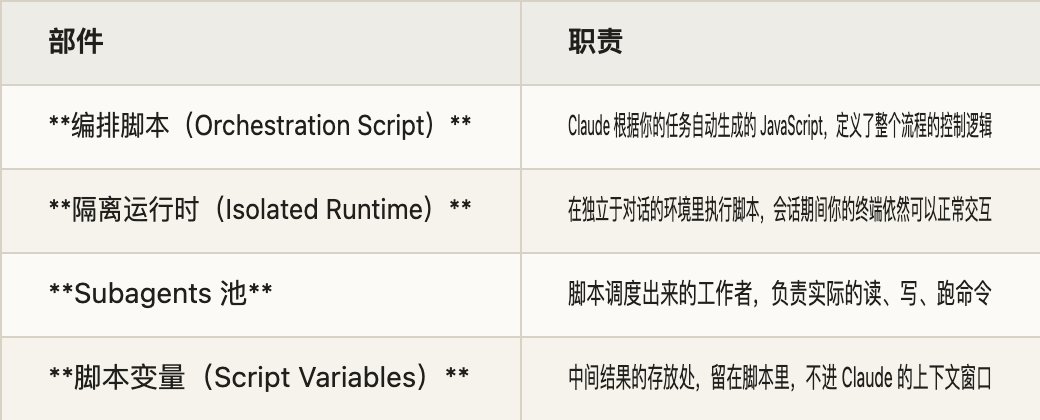
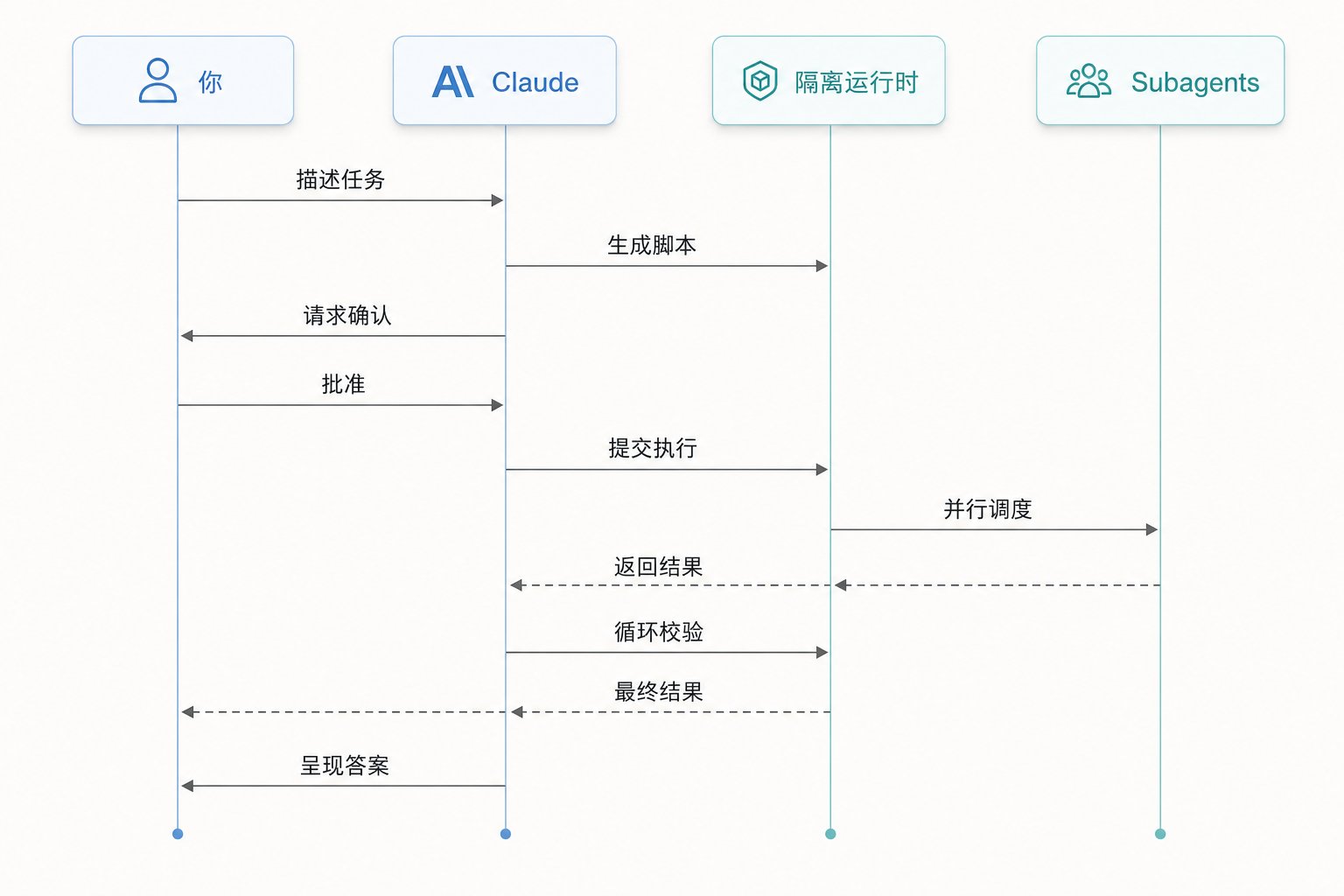
Dynamic Workflows 的关键转折就在这里。它 不再让 Claude 逐轮亲自调度 ,而是先写出一段 JavaScript 编排脚本 ,把循环、分支、阶段划分和中间结果收集都放进代码里,再交给独立运行时执行。这样一来,Claude 的上下文只需要保留最终答案,而不是背着所有中间过程往前走。
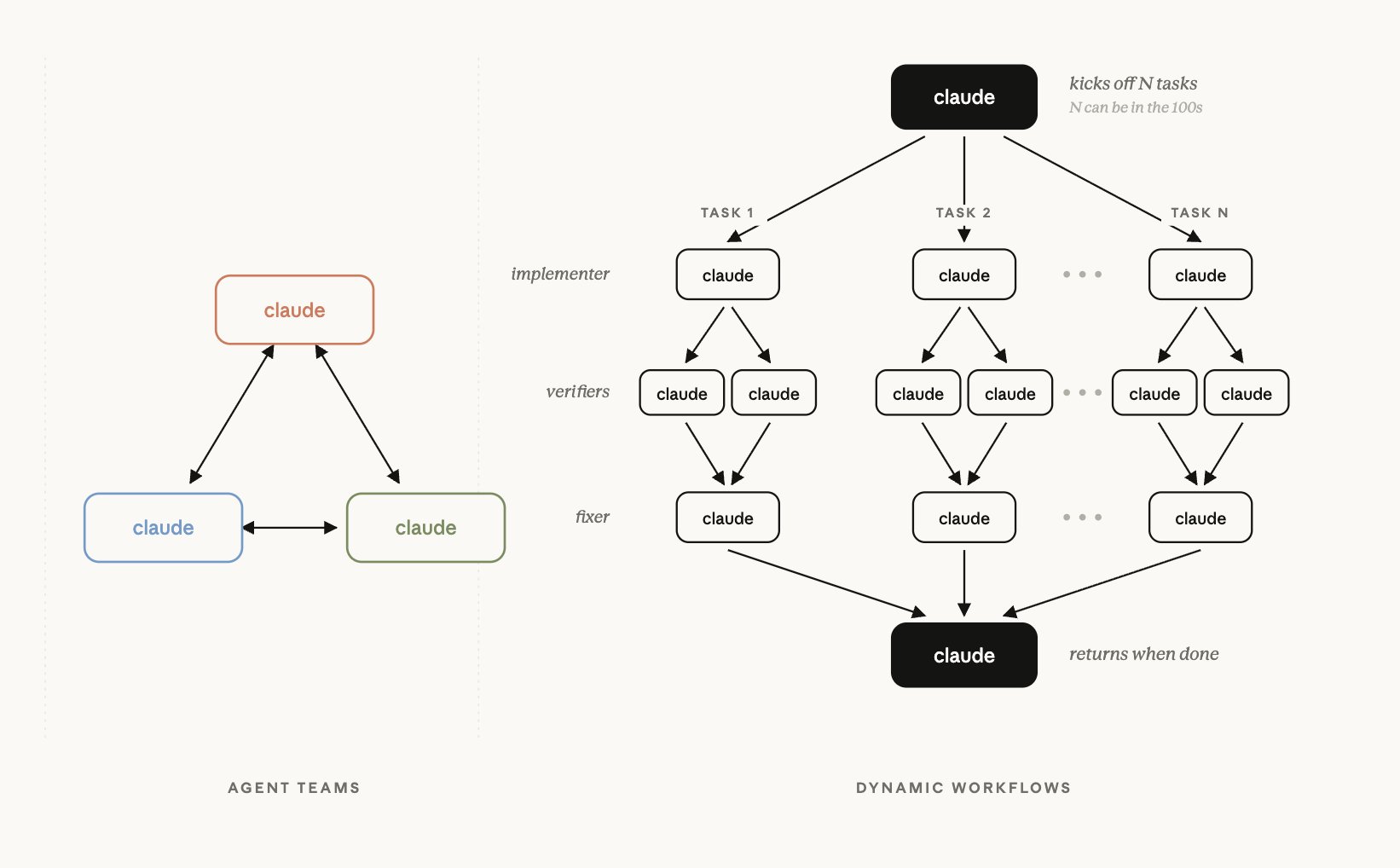
Dynamic Workflows 要解决的大任务场景
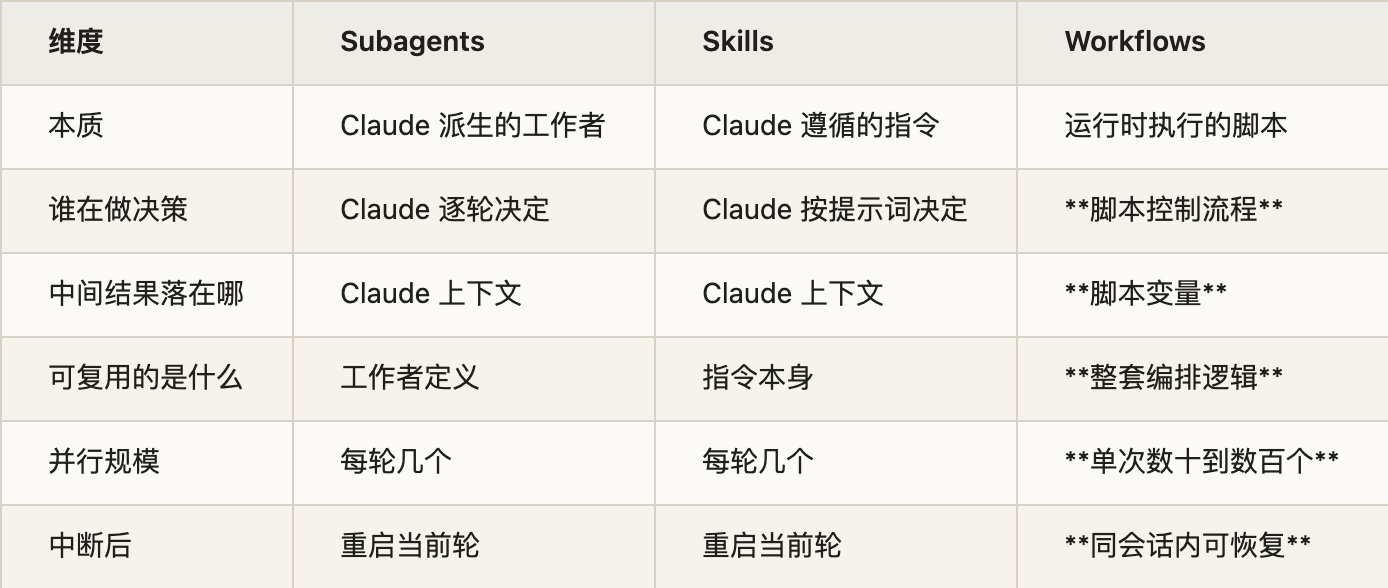
它和 Subagent、Agent Teams 真正差在哪
核心差别在“编排权”到底放在哪里
原文把 Claude Code 的几层协作能力梳理得非常清楚。
最底层是 单个 session ,一个 Agent 从头干到尾。往上一层是 subagent ,主 Agent 派几个小弟出去干活,再把结果收回来。再往上是 Agent Teams ,多个 Claude Code 实例像团队一样并行协作。
但这几层有一个共同前提: 编排者始终是 Claude 本身。 也就是说,Claude 每一轮都得重新判断下一步该派谁、该查什么、该怎么汇总。而 Dynamic Workflows 的本质,是把这层“临场指挥”抽出来,变成一段 先写好、再执行 的代码。
这就是为什么官方会说, workflow 把 plan 搬进了 code 。subagent 和 skills 复用的是“一个工作者”或“一条指令”,workflow 复用的是 整套编排逻辑 。一个复杂的多阶段工程流程一旦写好,以后就能反复跑,而不是每次都靠主 Agent 在对话里临时组织。
Subagent 与 Workflow 的结构变化
一个很容易误会的点
Workflow 不是跑在 Anthropic 云端
原文这一段我很喜欢,因为它把一个常见误解直接拆开了。
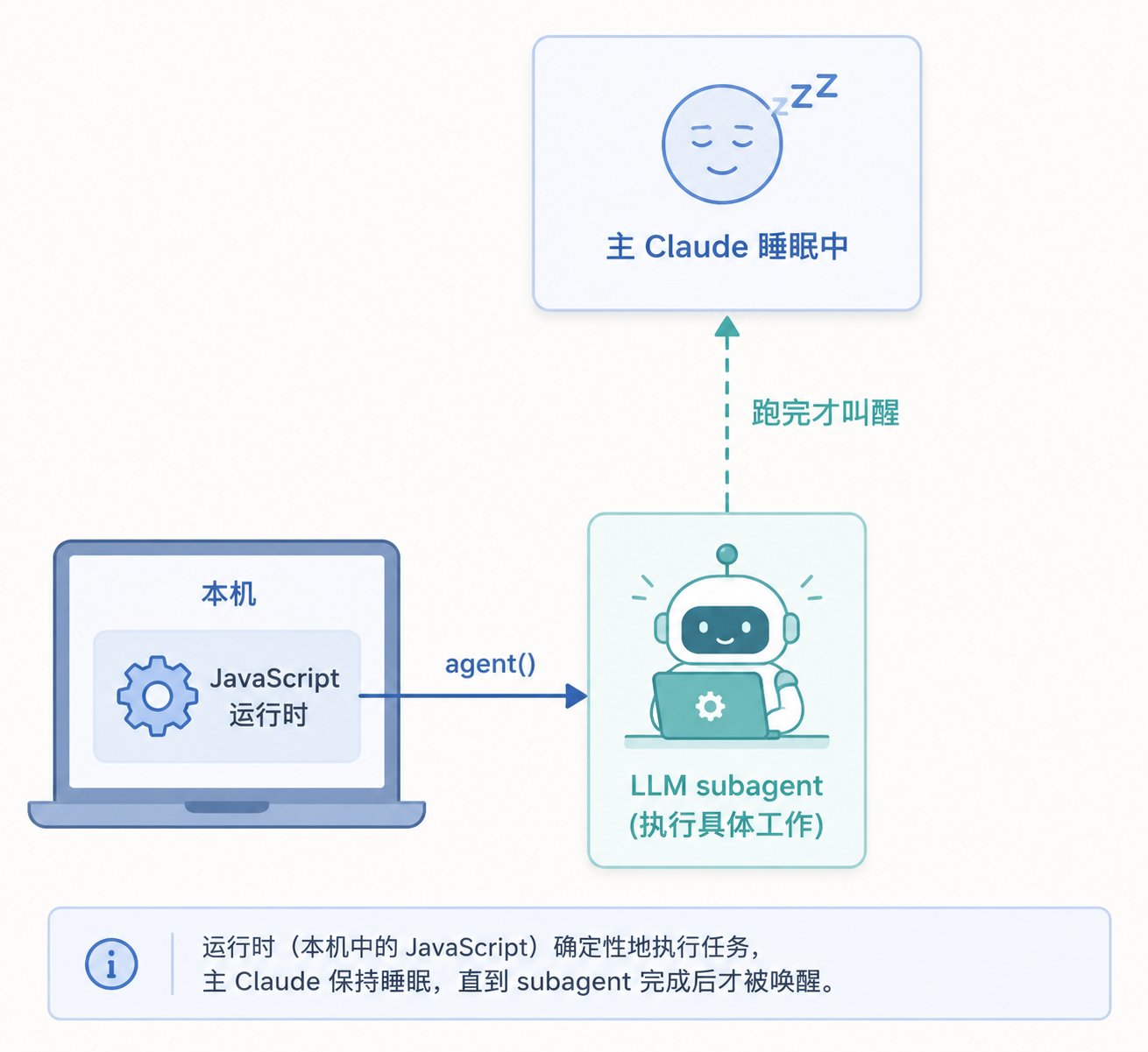
很多人看到 workflow、agent、编排脚本这些词,第一反应会觉得背后应该有个跑在 Anthropic 服务端的编排引擎。 但事实不是这样。 Dynamic Workflows 本身并不是什么神秘的云端调度中心,它本质上是 Claude Code 在 本机运行的一段 JavaScript 脚本 。
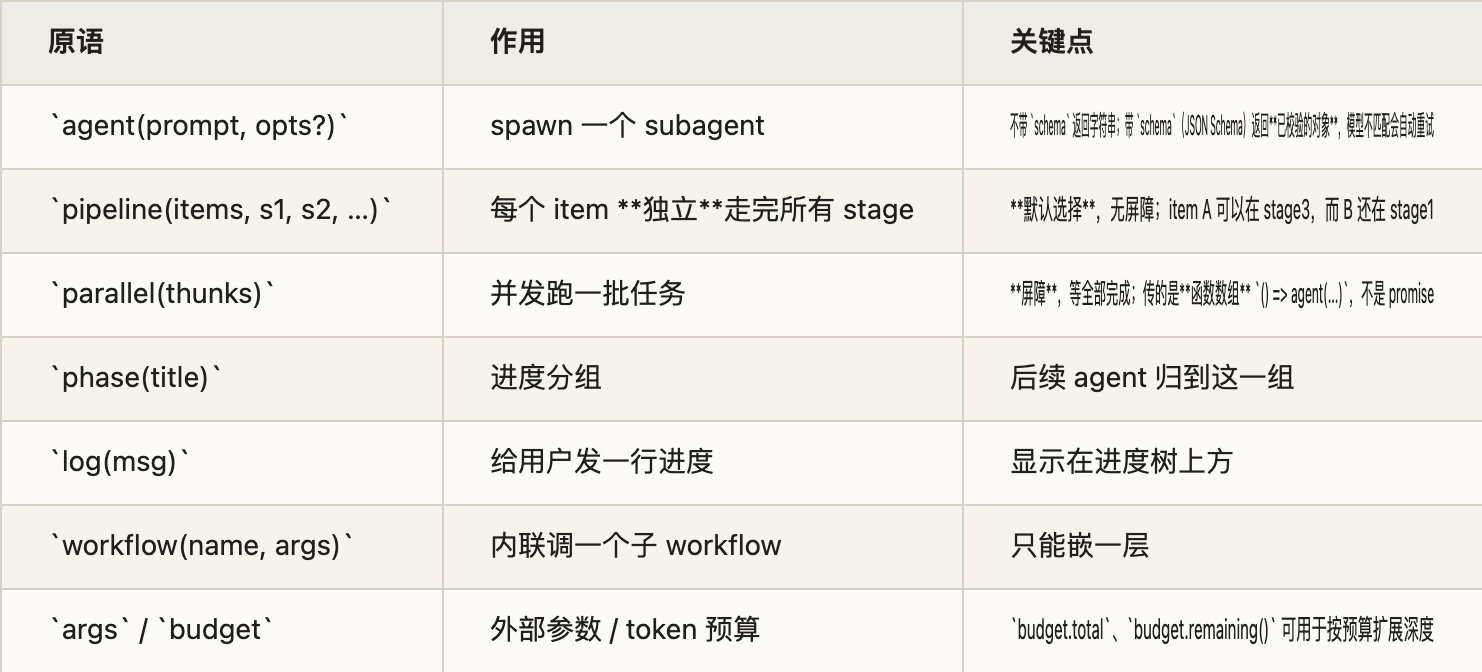
agent()、parallel()、pipeline() 这些控制流都在你机器上执行。真正去调用模型的,是脚本里 spawn 出来的 subagent。换句话说, JavaScript 运行时只是指挥 ,真正负责“动脑”的时刻,是脚本执行到 agent(...) 时临时雇一个 LLM subagent 去干活。
这也解释了另一个现实问题:如果你用第三方 API 中转时 workflow 跑挂了,问题通常不在 workflow 机制本身。因为它底层走的,和 Claude Code 平时调模型用的是 同一套 Anthropic Messages API 逻辑 ,而不是一套独立的新协议。
Workflow 在本机运行的说明图
Dynamic Workflows 最值钱的地方
它把中间状态从上下文里“移”了出去
这篇文章最值得反复咂摸的一点,就是它并没有把 workflow 讲成一个抽象 buzzword,而是讲清了它为什么真的有 工程价值 。
以前我们讨论大上下文,核心是在想“怎么把更多材料塞进模型窗口里”。Dynamic Workflows 则在处理另一个层级的问题: 当任务规模已经大到上下文根本装不下时,怎样才能不靠主对话硬扛。
它的回答非常工程化。脚本自己持有循环、分支和中间变量,subagent 的结果先回到脚本变量里,在运行时内部被过滤、汇总、验证,只有最后凝结成一个较稳定的结果,才真正返回给 Claude 主上下文。 这个差别看着像技术实现,实际上会直接改变任务规模上限。
说得再直白一点, subagent 模式是在让 Claude 一边思考一边兼职当项目经理;workflow 模式则是先把项目管理写进代码,再让 Claude 只在关键节点参与。
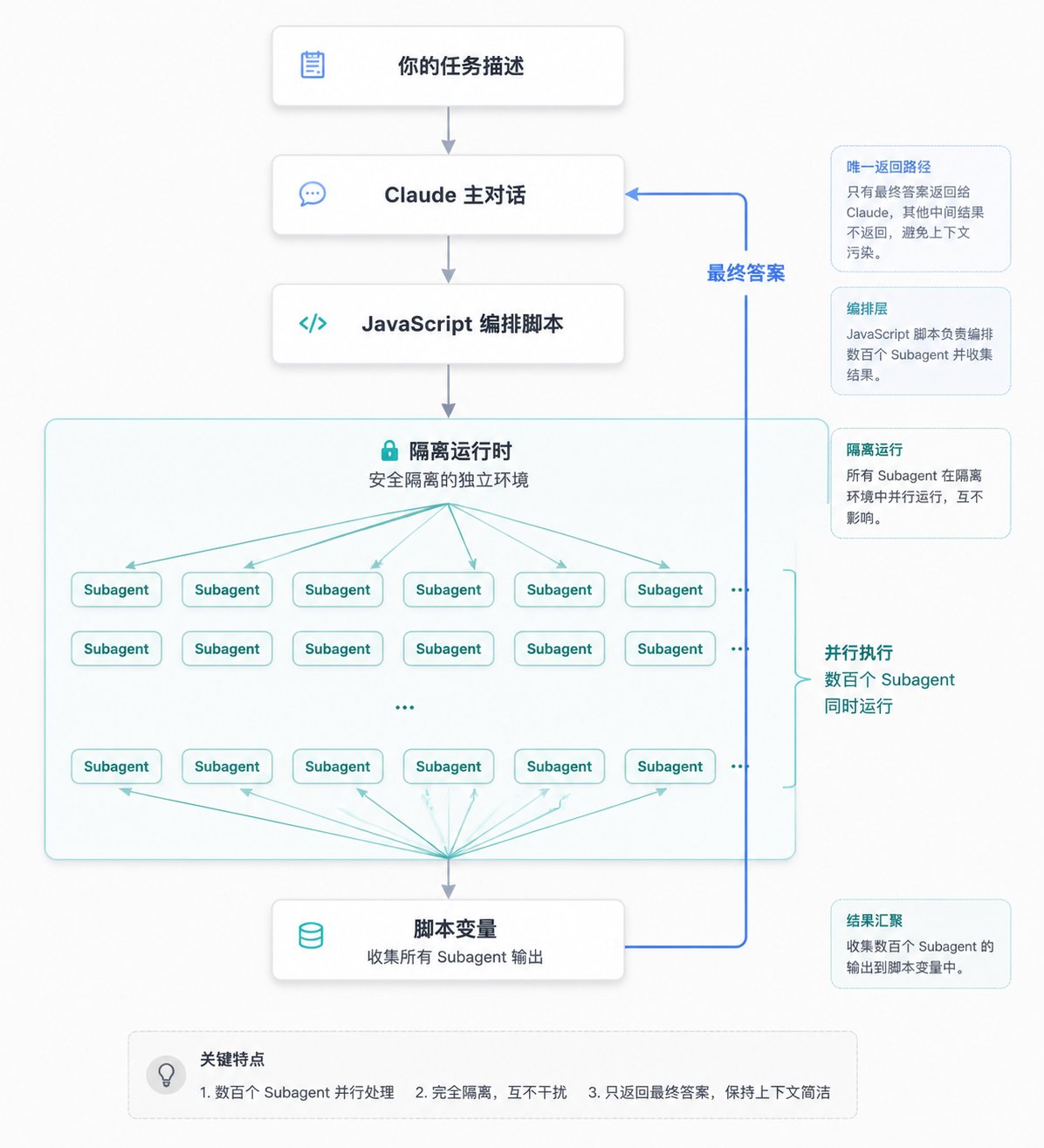
中间结果留在脚本变量中的示意图
真正会影响效果的技术细节
parallel 和 pipeline 的区别,不只是 API 名字不同
原文里讲得很细的一块,是 parallel 和 pipeline 这对最容易踩坑的原语。
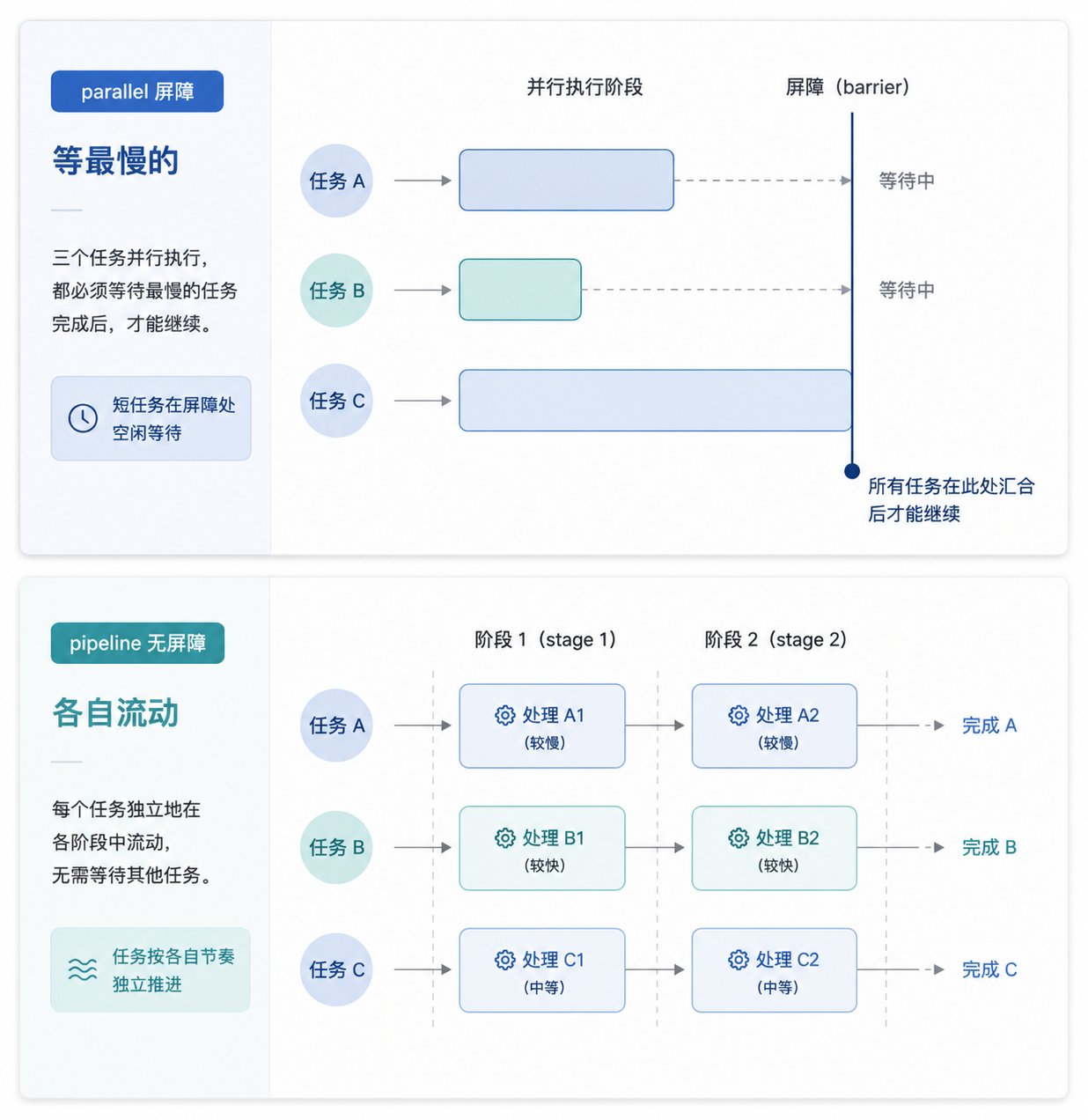
parallel 有明显的屏障语义,也就是这一批任务必须全部结束,下一步才会开始。这适合需要全量合并、去重、横向比较或根据总数做决策的情况。
pipeline 则不是这样。它更像流水线,每个 item 可以独立流过多个 stage,谁先做完谁先往下走,不需要等整批收工。这个差别在复杂任务里会非常实际,因为如果你只是把一个批次先 parallel 跑完,再做一些简单变换,然后又开下一轮 parallel,中间很可能白白等了很多慢任务。
作者这里真正想说的是: Workflow 不只是“把多个 agent 摆在一起” ,而是开始让你像写并发程序一样,认真思考屏障、流动、阶段依赖和编排结构。
parallel 与 pipeline 的差异图
你到底该怎么触发它
三种触发方式,对应三种完全不同的使用心态
第一种最直接,在 prompt 里明确写 workflow,让 Claude 按工作流方式处理。第二种是开 /effort ultracode,把“要不要起 workflow”这个判断交给 Claude。第三种是把 workflow 保存下来,以斜杠命令的形式反复调用。
这三种方式,其实对应了三种完全不同的使用习惯。你可以把 workflow 当成一次性的重任务工具,也可以把它当成更高努力档位下的自动策略,还可以把它沉淀成项目级或个人级资产,变成 .claude/workflows/ 或 ~/.claude/workflows/ 里的可复用脚本。
一旦你接受第三种用法,Dynamic Workflows 就不只是一个功能,而开始像一个 新的开发原语 。因为从那一刻起,你保存下来的不再只是 prompt,而是一整套 可执行的编排逻辑 。
workflow 触发方式与保存方式
两个最值得看的案例
Bun 的案例说明了规模,133 个历史会话的案例说明了现实感
文章里两个案例放在一起看,很有意思。
Bun 从 Zig 迁移到 Rust 是那种一看就知道体量惊人的例子。作者把它拆成三个 workflow 阶段来理解: 先做 Rust lifetime 映射,再并行把 .zig 文件迁成行为等价的 .rs 文件,而且每个文件还配两个 reviewer,最后通过 build 和 test 的 fix loop 一直修到干净为止。 这个案例的意义在于,它证明 workflow 不只是概念上能跑,而是真的能扛 重型机械迁移 。
但作者没有停在这种“天花板秀肌肉”案例上。他还拿自己的 133 个历史会话做实验,让 10 个分析 agent 并行啃批次,再让 1 个综合 agent 汇总。账单很具体: 11 个 agent、81.8 万 token、254 秒。
这一段特别好,因为它把 workflow 从“看上去很厉害”拉回到了“我今天到底能拿它做什么”。而且作者也没有神化它,反而很诚实地补了一句: 对于这种一把梭的 map-reduce 型任务,workflow 和直接派一堆 subagent 的差距并没有想象中那么大。 workflow 真正赚到的,是复杂度继续上升之后的收益。
Bun 迁移与历史会话分析案例图
它和 n8n、Coze、Dify 到底差在哪
不止是“AI 自动编排”这么简单
这篇文章在比较这一段时也挺到位,没有停留在很浅的类比上。
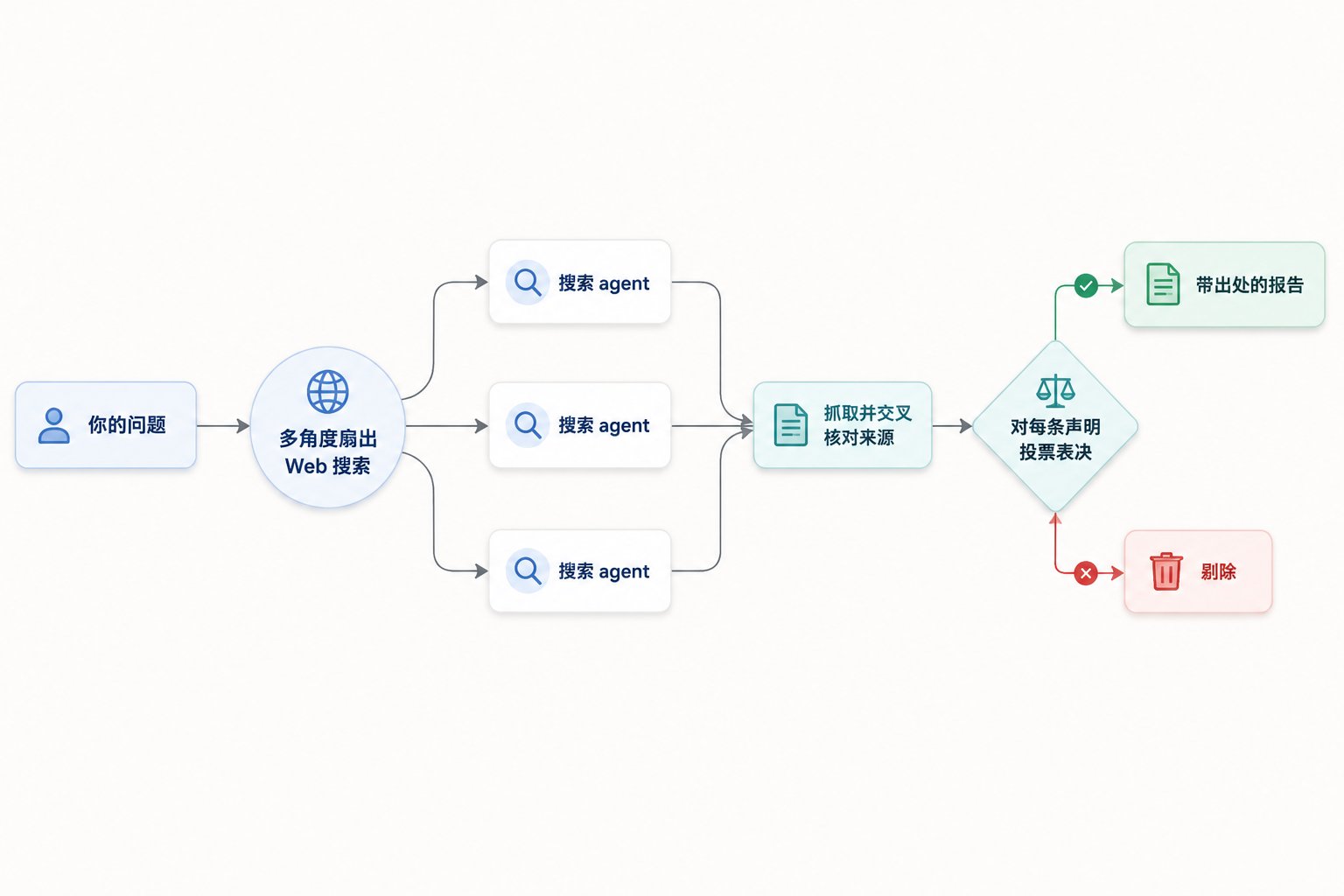
表面上看,Dynamic Workflows 当然会让人想到 n8n、Coze、Dify 这一类流程编排工具,因为大家都在做“把 LLM 和工具串成流程”。但作者指出,真正的共性是:它们都属于确定性 workflow,流程一旦写好,执行本身并不再由模型临场决定。
真正的差别有两层。第一层,是编排作者从“人”变成了“模型”;第二层,是编排载体从可视化 DAG 变成了图灵完备的命令式代码。这听起来像语言差异,实际意味着表达力差异。循环、动态扇出、运行时决定的分支,这些都是传统可视化 DAG 很难自然表达的东西。
所以更准确的说法不是“这就是 AI 自动版 n8n”,而是 “它把 workflow 编排从人工绘图推进到了模型现写代码”。 这会让它在 coding agent 场景里更灵活,也更接近真实工程节奏。
Workflow 与传统流程编排工具的对比
真正的门槛,不只是 token
贵是一回事,治理要求是另一回事
原文对成本问题说得很坦率。单次 workflow 的 token 消耗就是会明显高于普通 Claude Code 对话,因为你本质上是在同时雇很多 subagent,再叠加交叉验证、对抗式 review 和多阶段执行,账单不高才奇怪。
但我觉得这篇文章更有价值的一点,是它没有把问题只说成“贵不贵”,而是在提醒另一件更关键的事: 一旦你让 AI 开始替你组织执行链路,你就必须比以前更认真地面对权限、allowlist、日志、恢复、审查和回滚。
最多 16 个并发 subagent、单次最多 1000 个 agent、脚本没有直接 shell 和文件系统权限、超出 allowlist 还是会弹确认、跨会话无法恢复,这些限制看起来像小字条款,实际上正是在提醒你:workflow 已经不是聊天功能了,它在往工程系统靠。
限制、并发和恢复机制相关图
Dynamic Workflows 很可能代表 coding agent 的未来方向 ,一年之内,这种“模型现写编排脚本,再调度一支 agent 舰队”的做法,大概率会从研究预览长成主流能力。
这个判断我觉得站得住,原因也正是文章里说的那两块拼图:一块是把编排固化成代码,让流程可审、可存、可复用;另一块是要有足够强、足够诚实的前沿模型,能让多智能体交叉验证不是表面热闹,而是真的提高可靠性。
说到底, Dynamic Workflows 的意义不只是在 Claude Code 里多了一个开关 ,而是在告诉所有 AI 编程工具一个方向:下一阶段的竞争,可能不只是看谁更会写代码,而是看谁更会组织复杂工程。
参考链接
https://x.com/riba2534/status/2060102236676792711
https://code.claude.com/docs/en/workflows
https://claude.com/blog/introducing-dynamic-workflows-in-claude-code
https://www.anthropic.com/news/claude-opus-4-8


