IntroductionSi vous entendez parler d’« ingénierie de boucle » sans vraiment savoir par où commencer, ce guide vous propose un point d’entrée pratique.Au lieu d’écrire des prompts à répétition et de vérifier chaque étape manuellement, une boucle permet à un agent IA de travailler vers un petit objectif selon un calendrier. Le système peut attribuer la tâche, lire l’état actuel, exécuter l’agent, vérifier le résultat et faire intervenir de nouveau un humain lorsqu’un jugement est nécessaire.Le rapport original présentait un framework open source d’ingénierie de boucle créé par Cobus Greyling. Au moment de la publication du rapport, le projet comptait environ 4,5 k étoiles sur GitHub. Le dépôt peut désormais afficher un nombre d’étoiles différent, car il a continué à se développer. En bref : l’objectif n’est plus seulement d’écrire de meilleurs prompts. Il s’agit de concevoir une boucle fiable, capable de générer des prompts, de vérifier et d’itérer avec des limites claires.## Qu’est-ce que l’ingénierie de boucle ?L’ingénierie de boucle est une manière de concevoir des flux de travail répétables pour des agents IA. Une boucle n’est pas simplement un prompt unique. C’est un petit système d’exploitation autour d’un agent : elle définit quand l’agent s’exécute, quel contexte il lit, ce qu’il est autorisé à modifier, comment le résultat est vérifié et quand un humain doit examiner l’issue.Une boucle typique peut être utilisée pour des tâches telles que :- le tri quotidien de projets ;
- la surveillance des pull requests ;
- le nettoyage des échecs de CI ;
- l’analyse des dépendances ;
- le tri des issues ;
- le nettoyage après des fusions ;
- la rédaction de journaux de modifications.Ces tâches ne sont pas toujours difficiles, mais elles sont répétitives. Elles exigent de l’attention, du contexte et une norme cohérente. C’est précisément le type de travail pour lequel une boucle bien conçue peut être utile.## Pourquoi ce framework attire l’attentionLe framework open source décrit dans l’article original réunit des modèles de boucle pratiques, des modèles de démarrage et des outils en ligne de commande. Il est conçu pour les agents IA de codage et prend en charge des flux de travail autour d’outils tels que Claude Code, Codex, Grok et OpenCode.Le framework comprend :- sept modèles de boucle prêts à l’emploi ;
- des modèles de démarrage pour des scénarios courants ;
loop-init pour générer la structure d’une boucle ;loop-cost pour estimer le coût en tokens ;loop-audit pour vérifier l’état de préparation d’une boucle ;- des fichiers d’état et de budget pour les flux de travail de longue durée ;
- une prise en charge d’une revue humaine plus sûre et d’un déploiement progressif.Le message central est simple :> Arrêtez de prompter. Concevez la boucle.Cela ne signifie pas que les prompts disparaissent. Cela signifie que les prompts deviennent une partie d’un système plus large, capable de répéter le travail, de suivre l’état et de vérifier les résultats.## Démarrer rapidement : une seule commandeLe moyen le plus rapide de commencer consiste à exécuter
loop-init dans un projet Git.> Remarque : certaines versions republiées de l’article original affichent les options de ligne de commande avec un tiret long. Dans un vrai terminal, utilisez le double tiret standard -- indiqué ci-dessous.```Bash
npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude
```Cette commande génère la structure de la boucle dans votre projet actuel. Vous pouvez remplacer claude par un autre outil pris en charge, comme grok, codex ou opencode, selon le flux de travail que vous souhaitez tester.Le modèle daily-triage constitue un bon point de départ pour les débutants, car il présente moins de risques qu’une automatisation à haute fréquence. Il se concentre sur l’analyse de l’état actuel du projet et la production d’un rapport avant d’autoriser toute modification automatique.## Tutoriel d’ingénierie de boucle adapté aux débutantsL’ingénierie de boucle peut sembler abstraite au premier abord, mais le framework la décompose en quelques blocs de construction concrets.### Les cinq blocs de construction plus la mémoireÀ un niveau de base, une boucle est construite à partir de cinq parties principales, auxquelles s’ajoutent la mémoire et l’état.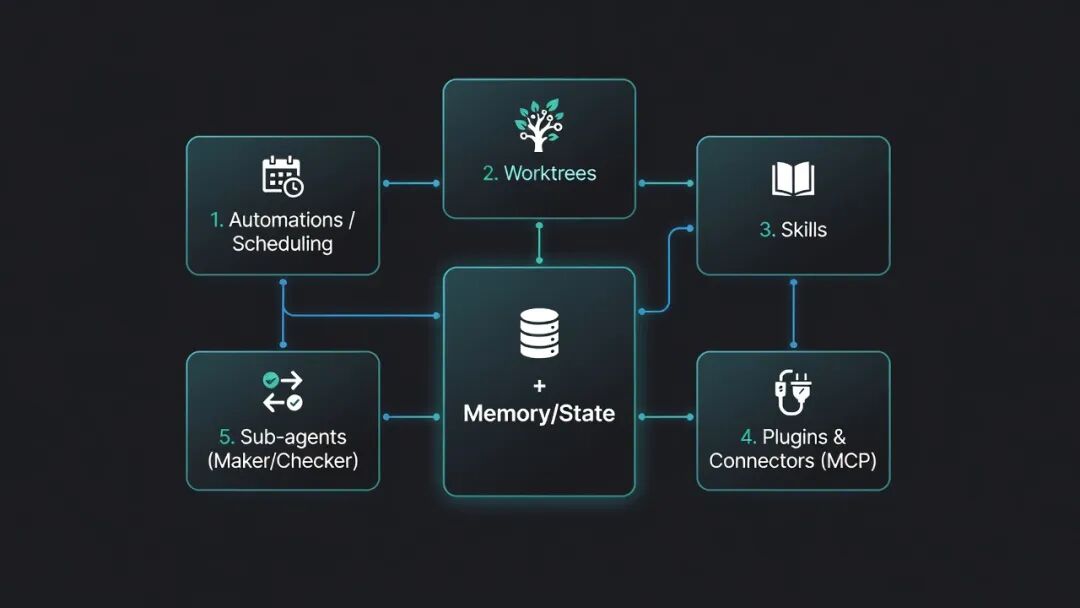 | Bloc de construction | Ce qu’il fait dans la boucle |
| Bloc de construction | Ce qu’il fait dans la boucle |
|-|-|
| Automatisation / Planification | Exécute la boucle selon une cadence, par exemple chaque jour, chaque heure ou toutes les quelques minutes. |
| Arbres de travail | Crée des environnements de travail isolés afin que plusieurs agents ne s’écrasent pas mutuellement. |
| Compétences | Stocke les connaissances réutilisables du projet, les règles et les instructions de tâche. |
| Plugins et connecteurs | Connecte la boucle à de vrais outils via des systèmes tels que MCP, GitHub, Linear ou Slack. |
| Sous-agents | Sépare le rôle de producteur du rôle de vérificateur afin que le même agent n’approuve pas son propre travail. |
| Mémoire / État | Conserve un contexte durable en dehors de la boucle. |chat, généralement via des fichiers tels que STATE.md. |Cette structure rend la boucle plus facile à comprendre. Vous ne demandez pas au modèle de « tout gérer simplement ». Vous lui fournissez un environnement défini, une planification, un fichier d’état, un chemin de vérification et une règle de transfert vers un humain.### Sept modèles de production prêts à l’emploiLe framework comprend également sept modèles orientés production. Chaque modèle possède une cadence, un niveau de risque et un cas d’utilisation optimal différents. | Modèle | Cas d’utilisation typique | Mode de départ suggéré |
| Modèle | Cas d’utilisation typique | Mode de départ suggéré |
|-|-|-|
| Daily Triage | Analyser l’état du projet, les tickets, la CI et les commits. | L1 report-only |
| PR Babysitter | Surveiller les pull requests tout au long de la revue, de la CI, du rebase et de la fusion. | L1 watch |
| CI Sweeper | Surveiller les checks en échec et proposer ou appliquer de petites corrections. | L2 cautious |
| Dependency Sweeper | Vérifier les dépendances obsolètes et les mises à jour de sécurité. | L2 patch-only |
| Issue Triage | Dédupliquer, évaluer et étiqueter les nouveaux tickets. | L1 propose-only |
| Post-Merge Cleanup | Nettoyer les TODO, la dette mineure et les travaux de suivi après les fusions. | L1 off-peak |
| Changelog Drafter | Rédiger les notes de version à partir des commits et des changements fusionnés. | L1 draft |Le conseil pratique est de commencer par une boucle à faible risque. Le triage quotidien est généralement plus facile à adopter en toute confiance, car il n’a pas besoin de modifier le code immédiatement.### Sélecteur interactif de modèlesLe projet fournit également un sélecteur interactif. Au lieu de choisir un modèle manuellement, vous pouvez partir d’un point de douleur comme « les PR restent bloquées », « la CI échoue sans cesse » ou « les tickets sont trop bruyants ».Le sélecteur recommande ensuite un modèle de boucle et vous fournit une commande de départ. C’est utile lorsque vous connaissez le problème, mais que vous ne savez pas quelle boucle doit s’en charger.## Exécuter votre première boucleVoici une manière adaptée aux débutants d’exécuter la première boucle tout en gardant le risque sous contrôle.### Étape 1 : Choisir un modèleCommencez par daily-triage si c’est votre première fois. C’est un modèle à faible risque et un bon moyen de comprendre comment la boucle lit l’état du projet, écrit des notes et prépare le travail pour un humain.### Étape 2 : Générer la structure de la boucleExécutez la commande d’initialisation dans le répertoire racine de votre projet Git.Bash npx @cobusgreyling/loop-init . --pattern daily-triage --tool claude Vous pouvez remplacer le nom de l’outil si vous utilisez un autre agent de codage IA.Bash npx @cobusgreyling/loop-init . --pattern daily-triage --tool grok npx @cobusgreyling/loop-init . --pattern daily-triage --tool codex npx @cobusgreyling/loop-init . --pattern daily-triage --tool opencode Vous pouvez également remplacer daily-triage par un autre modèle pris en charge une fois que vous comprenez le flux de base.### Étape 3 : Estimer le coût en tokensLes boucles à haute fréquence peuvent consommer beaucoup de tokens, surtout si elles utilisent des sous-agents, un long contexte ou des vérifications répétées. Estimez le coût avant d’exécuter une boucle trop souvent.Bash npx @cobusgreyling/loop-cost --pattern daily-triage --level L1 Pour les premiers tests, gardez la boucle au niveau L1 et évitez les planifications agressives.### Étape 4 : Auditer l’état de préparation de la boucleAvant de faire confiance à la boucle, lancez un audit. L’audit attribue au projet un score de préparation de 0 à 100 et suggère des améliorations.Bash npx @cobusgreyling/loop-audit . --suggest Si votre projet n’est pas prêt, corrigez d’abord les éléments manquants. Les lacunes courantes incluent l’absence de fichier d’état, l’absence d’étape de vérification, un périmètre flou, des limites budgétaires manquantes ou des règles faibles de transfert vers un humain.Si le projet atteint un bon niveau de préparation, vous pouvez également générer un badge Loop Ready pour votre README.Bash npx @cobusgreyling/loop-audit . --badge ### Étape 5 : Commencer en mode rapport uniquementNe laissez pas la boucle modifier le code de production dès le premier jour. Commencez en mode rapport uniquement, puis examinez manuellement la sortie.Pour une commande de boucle de style Grok, la première exécution peut ressembler à ceci :```Plaintext
/loop 1d Run loop-triage. Update STATE.md. No auto-fix in week one.
```Cela indique à la boucle d’effectuer le triage, d’écrire l’état et d’éviter les corrections automatiques pendant la première semaine.### Étape 6 : Lire la sortieOuvrez STATE.md et vérifiez ce que la boucle a trouvé. Ce fichier sert de mémoire en dehors de la conversation. Il doit montrer ce que la boucle a vu, ce qu’elle a fait, ce qu’elle a ignoré et ce qui nécessite l’attention d’un humain.Si la sortie est bruyante ou incorrecte, ajustez la boucle avant d’augmenter son autonomie. Une boucle utile doit devenir ennuyeuse, prévisible et inspectable.## Maturité des boucles : de L1 à L3Le Loop Engineering doit être déployé progressivement. Les niveaux de maturité vous aident à éviter d’accorder trop de liberté trop tôt.| Niveau | Signification | Utilisation recommandée |
|-|-|-|
| L1 | La boucle signale les constats et met à jour l’état, mais ne modifie pas le code. | Idéal pour les premières exécutions et une adoption à faible risque. |
| L2 | La boucle peut effectuer de petites modifications avec un vérificateur et une revue humaine. | Utile une fois que l’équipe fait confiance à la sortie de la boucle. |
| L3 | La boucle peut s’exécuter sur de plus longues périodes avec une exécution limitée sans surveillance. | Convient uniquement lorsque le périmètre, la sécurité, le coût et la vérification sont matures. |Un bon premier objectif n’est pas l’autonomie complète. Un bon premier objectif est une boucle L1 fiable qui vous fournit des informations utiles sanscréant un travail de nettoyage supplémentaire.

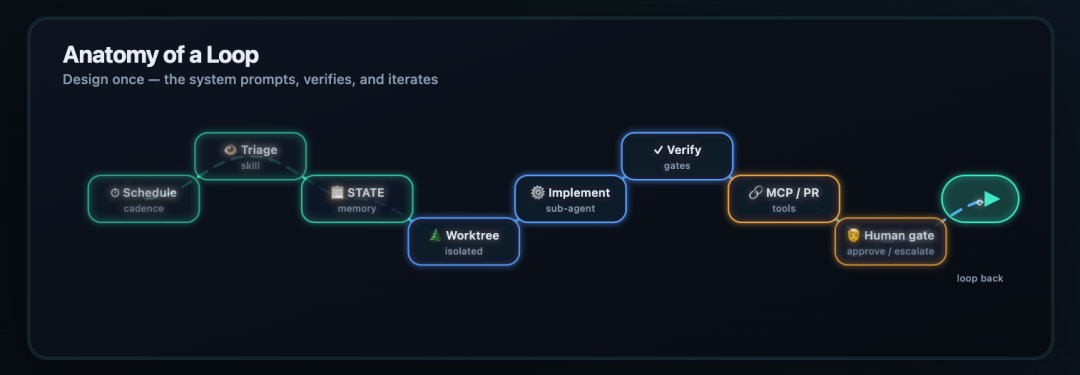 C’est la principale différence entre un prompt occasionnel et une véritable boucle. L’agent ne se contente pas de « faire des choses ». Il travaille dans un processus contrôlé, avec état, isolation, contrôles et transfert.## Andrew Ng : le développement produit a besoin de trois bouclesL’article original reliait également le Loop Engineering à la réflexion d’Andrew Ng sur le développement produit. L’idée essentielle est que construire un logiciel avec l’IA ne repose pas sur une seule boucle. Pour un vrai produit, plusieurs boucles avancent à des vitesses différentes.
C’est la principale différence entre un prompt occasionnel et une véritable boucle. L’agent ne se contente pas de « faire des choses ». Il travaille dans un processus contrôlé, avec état, isolation, contrôles et transfert.## Andrew Ng : le développement produit a besoin de trois bouclesL’article original reliait également le Loop Engineering à la réflexion d’Andrew Ng sur le développement produit. L’idée essentielle est que construire un logiciel avec l’IA ne repose pas sur une seule boucle. Pour un vrai produit, plusieurs boucles avancent à des vitesses différentes. ###
### Ensemble, les trois boucles créent une chaîne pratique de construction produit : l’agent aide à produire rapidement des versions, le développeur décide ce que le produit doit devenir, et les utilisateurs prouvent si la direction mérite d’être poursuivie.## Pourquoi le goût humain compte toujoursLe Loop Engineering ne retire pas les humains du développement logiciel. Il transforme leur rôle.L’agent peut gérer l’exécution répétée, mais il a toujours besoin de limites claires, d’une vérification solide et d’un jugement produit. L’humain comprend toujours le contexte : ce dont les utilisateurs ont besoin, quels compromis comptent, ce qui ne devrait pas être automatisé et ce que signifie réellement « suffisamment bon ».C’est pourquoi une boucle peut être installée avec une seule commande, mais la définition de « terminé » appartient toujours aux personnes qui construisent le produit.## Note sur la sourceSource originale :
Ensemble, les trois boucles créent une chaîne pratique de construction produit : l’agent aide à produire rapidement des versions, le développeur décide ce que le produit doit devenir, et les utilisateurs prouvent si la direction mérite d’être poursuivie.## Pourquoi le goût humain compte toujoursLe Loop Engineering ne retire pas les humains du développement logiciel. Il transforme leur rôle.L’agent peut gérer l’exécution répétée, mais il a toujours besoin de limites claires, d’une vérification solide et d’un jugement produit. L’humain comprend toujours le contexte : ce dont les utilisateurs ont besoin, quels compromis comptent, ce qui ne devrait pas être automatisé et ce que signifie réellement « suffisamment bon ».C’est pourquoi une boucle peut être installée avec une seule commande, mais la définition de « terminé » appartient toujours aux personnes qui construisent le produit.## Note sur la sourceSource originale : 

