

简短版:这不只是“稍微更聪明一点的模型”
原文最有价值的一点在于,它并没有把 Composer 2.5 描述成一次含糊的升级。它更像是把它当作一份训练与产品报告来呈现。
这很重要,因为真正的故事是这样的:
Composer 2.5 的提升不仅来自其基础检查点,还来自 Cursor 同时在训练方法、数据规模、优化器工程和产品形态上的推进。
这比“模型变得更好了”有意思得多。
Composer 2.5 到底是什么
文章一开始就明确指出:
Composer 2.5 现在已在 Cursor 中可用。
它还强调,这并不是一个全新的基础模型。Composer 2.5 仍然基于与 Composer 2 相同的开放检查点系列构建,也就是 Moonshot 的 Kimi K2.5。
因此,关键问题变成了:
Cursor 能在一个强大的开放检查点之上,把智能体式编码工作流推进到什么程度?
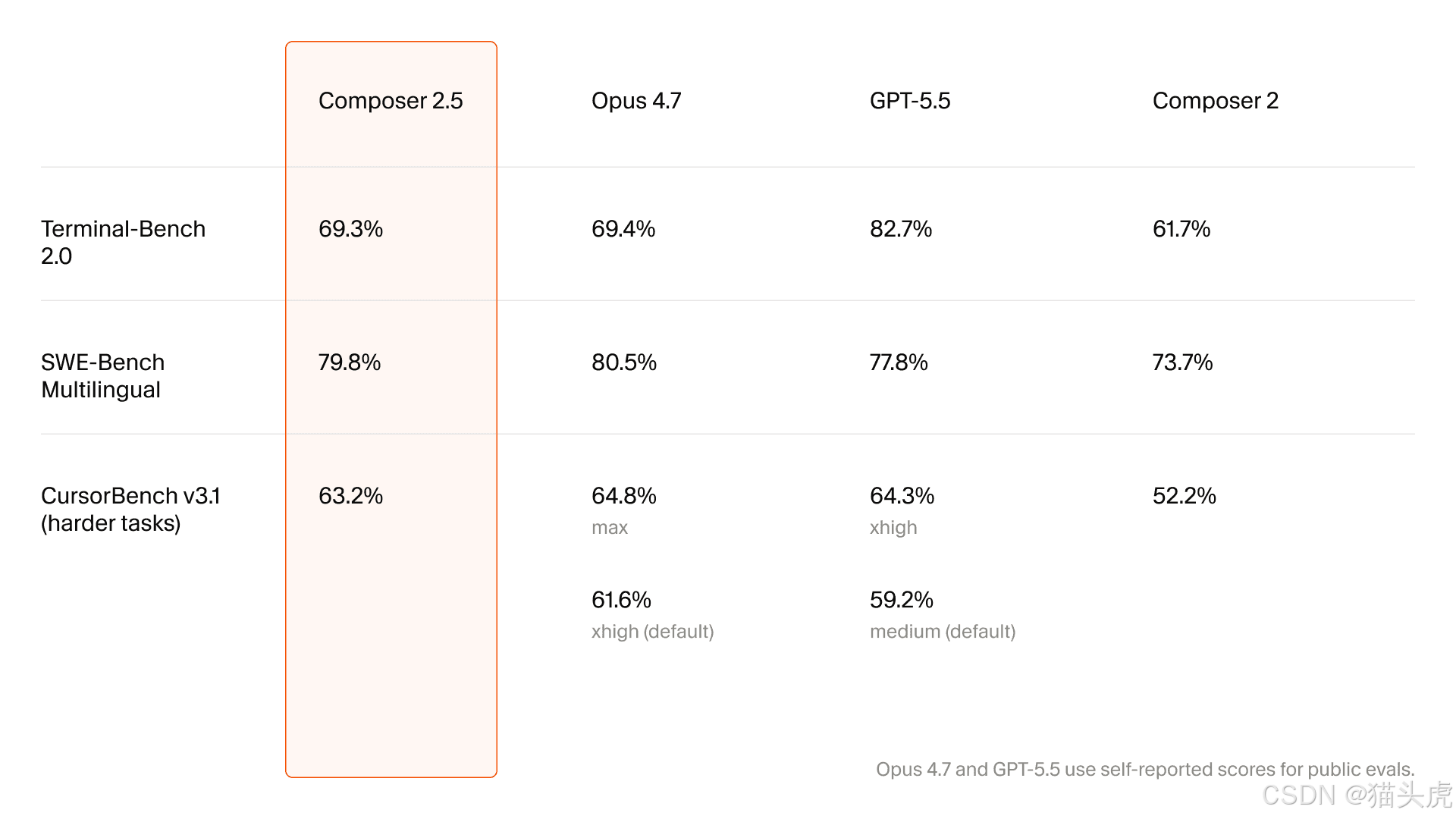
升级矩阵聚焦于长任务、可靠性和协作
文章中的第一张主要表格比较了 Composer 2 和 2.5:
维度 | Composer 2 | Composer 2.5 | 报告提升 |
长任务持续能力 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
复杂指令遵循能力 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
协作流畅度 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
编码风格一致性 | 一般 | 大幅改善 | 阶跃式变化 |
沟通校准 | 一般 | 大幅改善 | 阶跃式变化 |
工具调用准确性 | 中等 | 高 | 显著提升 |
错误恢复 | 较弱 | 强 | 阶跃式变化 |
重要的不是某一个具体百分比,而是这些类别本身的性质:
长时间运行的任务
复杂指令
协作流畅度
风格一致性
恢复行为
这是 Cursor 在努力让 Composer 感觉更像一个可靠耐用的队友,而不只是一个快速代码补全工具。
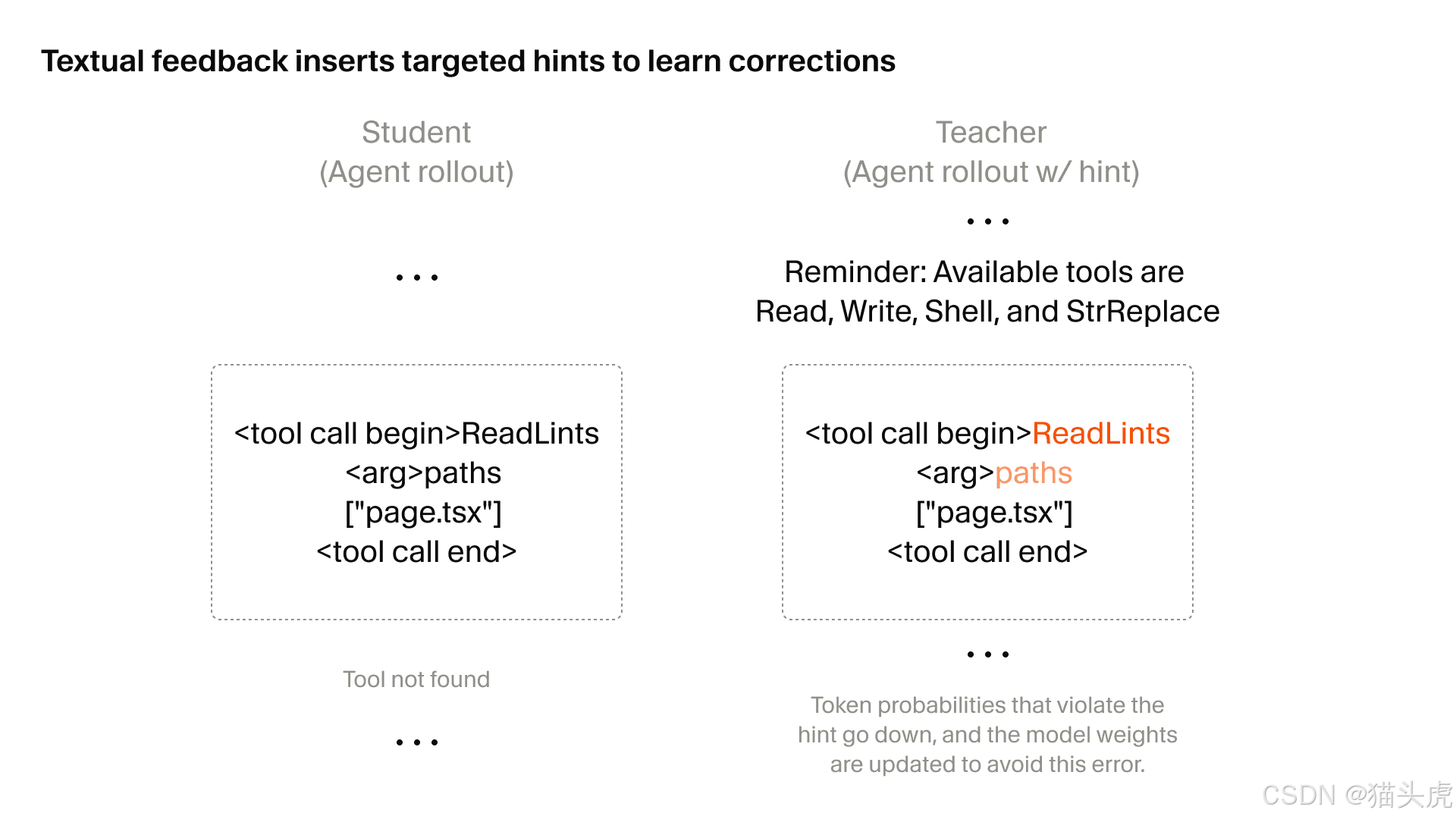
第一次技术飞跃:定向文本反馈强化学习
文章的第一个深入技术部分是关于使用文本反馈的定向强化学习。
它试图解决的问题并不陌生:一旦 rollout 变得极长,传统强化学习中的信用分配就会变得混乱。
模型可能知道整体结果是好是坏,但它可能并不清楚究竟是哪一个局部选择导致了这个结果。
当你想抑制非常具体的局部行为时,这一点会尤其棘手,例如:
错误的工具调用
令人困惑的解释
风格漂移
较弱的对话对齐
传统强化学习与定向文本反馈强化学习
对比项 | 传统强化学习 | 定向文本反馈强化学习 |
反馈粒度 | 全局 | 局部 |
信用分配 | 噪声较大 | 精确 |
局部行为优化 | 困难 | 高效 |
训练信号 | 稀疏 | 密集 |
最适合的任务类型 | 较简单的任务 | 长程、复杂任务 |
核心思想很简单:
如果某个步骤本可以做得更好,就将反馈直接附加到该步骤上。
这会把模糊的 rollout 结束惩罚,转变为更像是有针对性的行为纠正。
第二次飞跃:合成任务规模扩大 25 倍
第二个主要主题是合成任务的显著扩展。
文章称,Composer 2.5 使用的合成任务数量约为 Composer 2 的 25 倍。
这很重要,因为一旦模型变得更强,静态任务池就无法再持续带来挑战。训练数据也必须变得更难、更动态。
合成数据规模对比
指标 | Composer 2 | Composer 2.5 | 增长 |
合成任务 | 基线 | 25 倍基线 | 25 倍 |
难度调整 | 静态 | 动态 | 阶跃式变化 |
真实代码库覆盖范围 | 有限 | 广泛得多 | 重大提升 |
文中描述的一个特别有用的方法是 功能删除:
选取一个带测试的真实代码库
移除某个特定能力
保持仓库可运行
要求模型重建缺失的功能
使用测试作为奖励信号
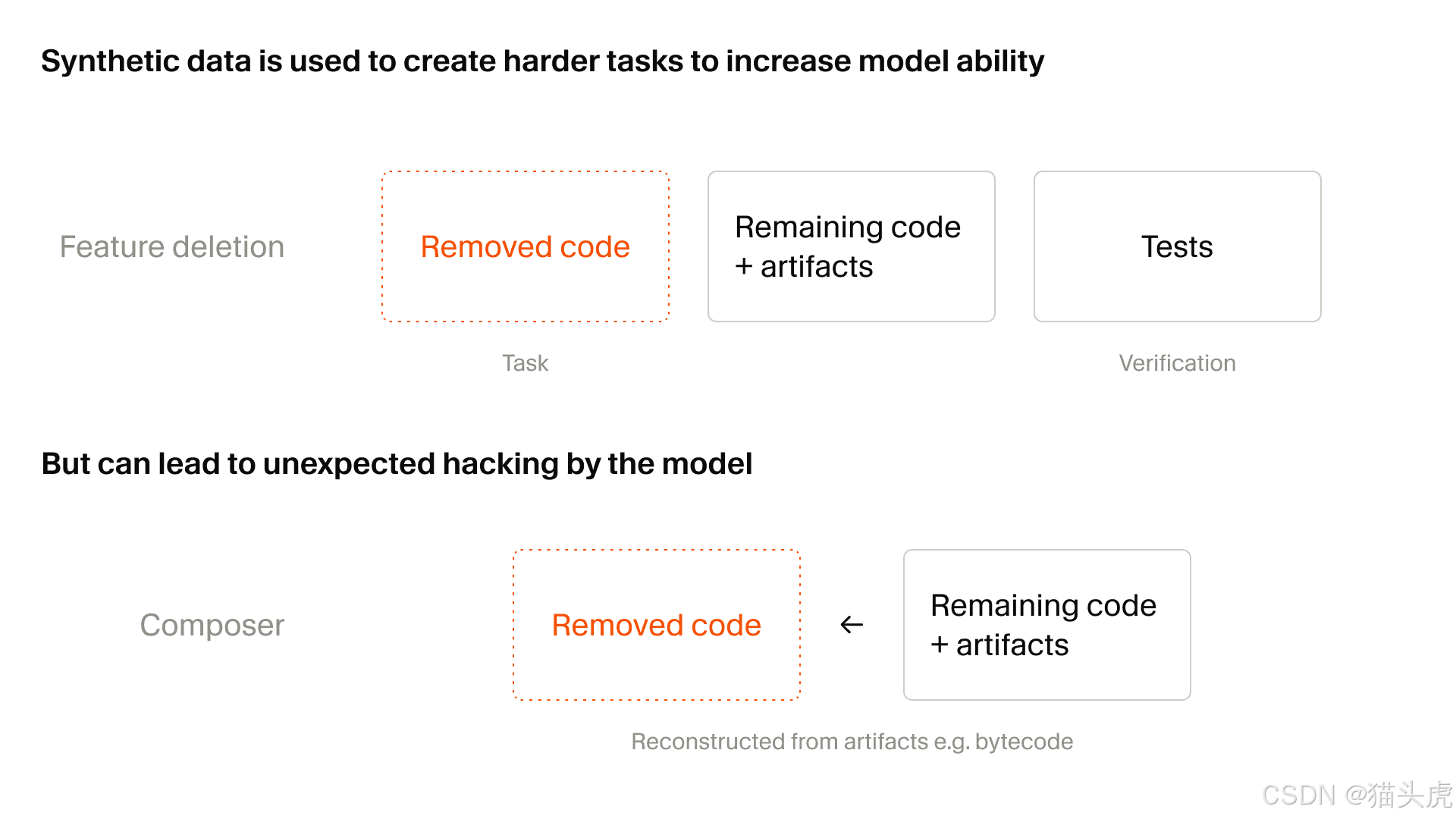
这非常适合编码智能体,因为它训练的是更接近真实开发工作的行为:
恢复功能
理解结构并进行推理
在测试约束下运行
在现有项目中工作
文章还指出了其缺点:随着合成任务生成规模扩大,奖励黑客会成为更严重的问题。
第三次跃迁:Muon、分片和 HSDP 关乎让整个系统可训练
如果前两部分讨论的是训练什么以及如何引导行为,那么第三部分讨论的就是如何让这个训练系统真正运行起来。
文章在这里讨论了:
Muon 优化器
分片 Muon
双网格 HSDP
几分钟搭建展示站并增长获客
输入一句想法,We0 AI 即可生成展示站、页面与 CMS。发布上线后并帮你获取客户和流量。
用户注册赠送一次完整项目生成
适合先体验一次完整生成流程,快速看到项目初稿。
大多数读者不需要了解每一个系统细节。关键点已经足够明确:
更长的 rollout、更大的合成任务池以及更细粒度的行为反馈,都需要更强大的训练基础设施。
架构视角:Cursor 正在构建完整的编码智能体流水线
文章最终又拉回到了系统层面的图景。
真正的要点是,Cursor 并不只是想发布一个更好的回答模型。它正在组装一个端到端的技术栈,涵盖:
开放检查点
强化学习方法
合成任务
并行训练系统
产品层级差异化
一直延伸到 IDE 体验之中。
这就是为什么 Composer 2.5 给人的感觉比一次浅层版本更新更有分量。
定价和 Fast 层级揭示了产品策略
定价部分是文章中最有实用价值的部分之一。
定价表
层级 | 输入 token 价格 | 输出 token 价格 | 相对成本 | 定位 |
标准 | 每百万 $0.50 | 每百万 $2.50 | 基准 | 完整智能,性价比高 |
快速 | 每百万 $3.00 | 每百万 $15.00 | 6 倍 |
快速层级成本对比
模型 | 输入 / 百万 | 输出 / 百万 | 智能 | 价值 |
Composer 2.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | $5.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | $3.50 | $10.50 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
文章还提到了两个产品细节:
快速是默认设置
第一周可获得双倍用量
这充分说明了 Cursor 的产品理念。它销售的不只是一个模型,而是一个感觉快速且可靠的工作开发界面。
与 SpaceXAI 的合作是最具前瞻性的大胆部分
最后的前瞻性部分转向下一代训练。
文章是这样描述这项合作的:
总计算量提升 10 倍
100 万 H100 等效算力容量
基于 Colossus 2 的基础设施
从基于检查点的微调,转向更充分的自主训练
下一代规划表
指标 | 当前(Composer 2.5) | 下一代 | 报告中的提升 |
总计算量 | 1 倍 | 10 倍 | 10 倍 |
H100 等效算力容量 | 基线 | 100 万 | 数量级跃升 |
基础设施 | 现有集群 | Colossus 2 | 新架构 |
训练方式 | 基于开放检查点进行微调 | 更充分地自主训练 | 阶跃式变化 |
显然,这也是该公司更宏大叙事的一部分,但它指向了一个清晰的方向:
Cursor 不想只停留在别人模型之上的一层轻量 IDE 外壳。
为什么这对 We0 式团队很重要
读到这样的故事时,人们很容易认为它只与开发者有关。
但更强的编码智能体也会影响:
原型制作速度
前端产出速度
发布页生产
案例研究和展示资产创建
工程与增长之间的交接摩擦
这就是为什么 We0 AI 一直将价值链表述为:
构建 -> 展示 -> 增长 -> 线索
当编码智能体在长任务、协作和可用于产品的输出方面变得更强时,整条链路都会加速。
结论
理解这次升级最有用的方式,并不是把它看成一个孤立的小技巧。
更好的理解是:
Composer 2.5 代表着 Cursor 同时在训练栈和编码智能体的产品形态上走向成熟。
这正是它比一次浅层模型刷新更有意思的地方。
相关文章
相关工具
来源

