
Un récent problème de journalisation de Codex a transformé une discrète base de données locale en un étonnamment gros générateur d’écritures sur SSD. Selon le rapport GitHub original, les journaux de feedback SQLite de Codex pouvaient écrire environ 640 To par an avec le schéma d’utilisation signalé. Pour un SSD grand public évalué à environ 600 TBW, ce chiffre n’est pas simplement un petit désordre ; il est proche de l’endurance d’écriture garantie du disque.
Le plus étrange, c’est que la base de données de journaux ne semblait pas énorme. Le fichier pouvait rester autour d’un gigaoctet, tandis que les écritures historiques réelles continuaient de s’accumuler en arrière-plan. C’est pourquoi ce bogue a attiré autant d’attention : il ne remplissait pas le disque de manière évidente, mais pouvait tout de même épuiser les cycles d’écriture.

Note sur la source : Cet article est basé sur la republication par BAAI Hub du rapport de Xinzhiyuan et a été recoupé avec l’issue GitHub publique et la discussion sur Hacker News. Les logos de marque, codes QR, invites à suivre et images décoratives sans rapport provenant de la page originale n’ont pas été inclus.
Comment 640 To d’écritures sur SSD peuvent se produire
Le chiffre paraît d’abord exagéré, il est donc utile de commencer par la mesure.
Dans l’issue GitHub, l’auteur du signalement a indiqué qu’après environ 21 jours de fonctionnement, le SSD principal avait écrit environ 37 To. Extrapolé sur une année complète, cela représente environ 640 To. La principale source suspectée était la base de données locale SQLite des journaux de feedback de Codex.
Codex écrivait dans des fichiers situés sous le répertoire de configuration local :
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shmLe comportement n’était pas simplement « le fichier journal grossit indéfiniment ». Au lieu de cela, cela ressemblait davantage à une boucle d’insertion et d’élagage : Codex insérait de nouvelles lignes, puis supprimait les anciennes afin de maintenir stable le nombre de lignes conservées. La taille visible du fichier restait relativement calme, mais le disque devait tout de même traiter les écritures répétées.
Un échantillon de 15 secondes tiré du rapport montrait clairement le problème :
Métrique | Avant | Après |
Lignes conservées | 681,774 | 681,774 |
ID de ligne maximal | 5,003,347,015 | 5,003,383,226 |
Cela signifie qu’environ 36 211 lignes ont été insérées en 15 secondes, même si le nombre de lignes conservées n’a pas augmenté du tout. De l’extérieur, la base de données semblait stable, mais le renouvellement des écritures continuait en dessous.
Les entrées de journal fréquentes n’étaient pas non plus toutes des événements applicatifs à forte valeur. Les exemples comprenaient du bruit répété au niveau du système de fichiers et des dépendances, comme des événements inotify :
128,764x TRACE log: inotify event: ... name: Some("ld.so.cache")
37,982x TRACE log: inotify event: ... name: Some("locale.alias")
23,843x TRACE log: inotify event: ... name: Some("passwd")Le résultat était un système de journalisation local capable de réécrire continuellement le stockage tout en donnant aux utilisateurs très peu de signes visibles qu’il se passait quelque chose d’inhabituel.
Un fichier de 1 Go peut tout de même générer des centaines de téraoctets d’écritures
La partie la plus contre-intuitive de cet incident est simple : l’usure d’un SSD dépend du volume total d’écritures, pas de la taille actuelle du fichier.
Une base de données locale peut rester autour de 1 Go pendant que l’application écrit, élague, indexe, crée des points de contrôle et réécrit de façon répétée certaines de ses parties. Du point de vue de l’état de santé du stockage, ce qui compte n’est pas seulement la taille apparente du fichier aujourd’hui. Ce qui compte, c’est la quantité de données écrites au fil du temps.
Le rapport incluait un instantané qui rendait cet écart plus facile à comprendre :
Métrique | Valeur |
Taille actuelle du fichier | 1,2 Gio |
Lignes actuellement conservées | 506 149 |
Nombre total d’identifiants de ligne alloués | 5 543 677 486 |
La base de données actuelle ne conservait qu’environ un demi-million de lignes, tandis que l’identifiant de ligne auto-incrémenté avait déjà dépassé les 5,5 milliards. C’est le cœur de l’histoire de l’amplification d’écriture : les anciennes lignes peuvent disparaître de la vue actuelle de la base de données, mais les écritures disque qui les ont créées ont déjà eu lieu.
Le WAL de SQLite, ou journalisation en écriture anticipée, joue également un rôle ici. Avec le mode WAL, les modifications sont ajoutées à un fichier -wal séparé avant d’être réintégrées dans la base de données principale lors d’un point de contrôle. Le WAL est un mécanisme SQLite normal et utile, mais lorsqu’une application effectue des insertions et des suppressions très fréquentes, il peut multiplier la quantité d’activité disque qui se produit en arrière-plan.
En termes simples : le carnet semble toujours mince, mais les mêmes pages ont été écrites, effacées et réécrites de nombreuses fois.
Cause profonde : un réglage RUST_LOG qui ne s’est pas comporté comme les utilisateurs s’y attendaient
Le rapport a mis en évidence un détail de configuration particulièrement important dans le chemin de journalisation de Codex :
Targets::new().with_default(Level::TRACE)Dans l’écosystème tracing de Rust, le filtrage des journaux est souvent contrôlé au moyen de cibles et de niveaux. Les utilisateurs peuvent raisonnablement s’attendre à ce que la variable d’environnement RUST_LOG aide à réduire la verbosité des journaux à quelque chose comme info, warn ou un niveau inférieur.
Mais dans ce chemin, le récepteur du journal de commentaires SQLite utilisait une valeur par défaut de TRACE. TRACE est le niveau le plus verbeux, et il peut capturer des détails de dépendances de bas niveau, l’activité brute du protocole et d’autres informations de débogage superflues. Le rapport d’incident soutenait que cette valeur par défaut signifiait que la base de données locale persistante des journaux continuait à stocker bien plus qu’elle ne le devrait.
La répartition des journaux conservés montrait à quel point le contenu de niveau TRACE était dominant :
Niveau | MiB estimés | Part des octets |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
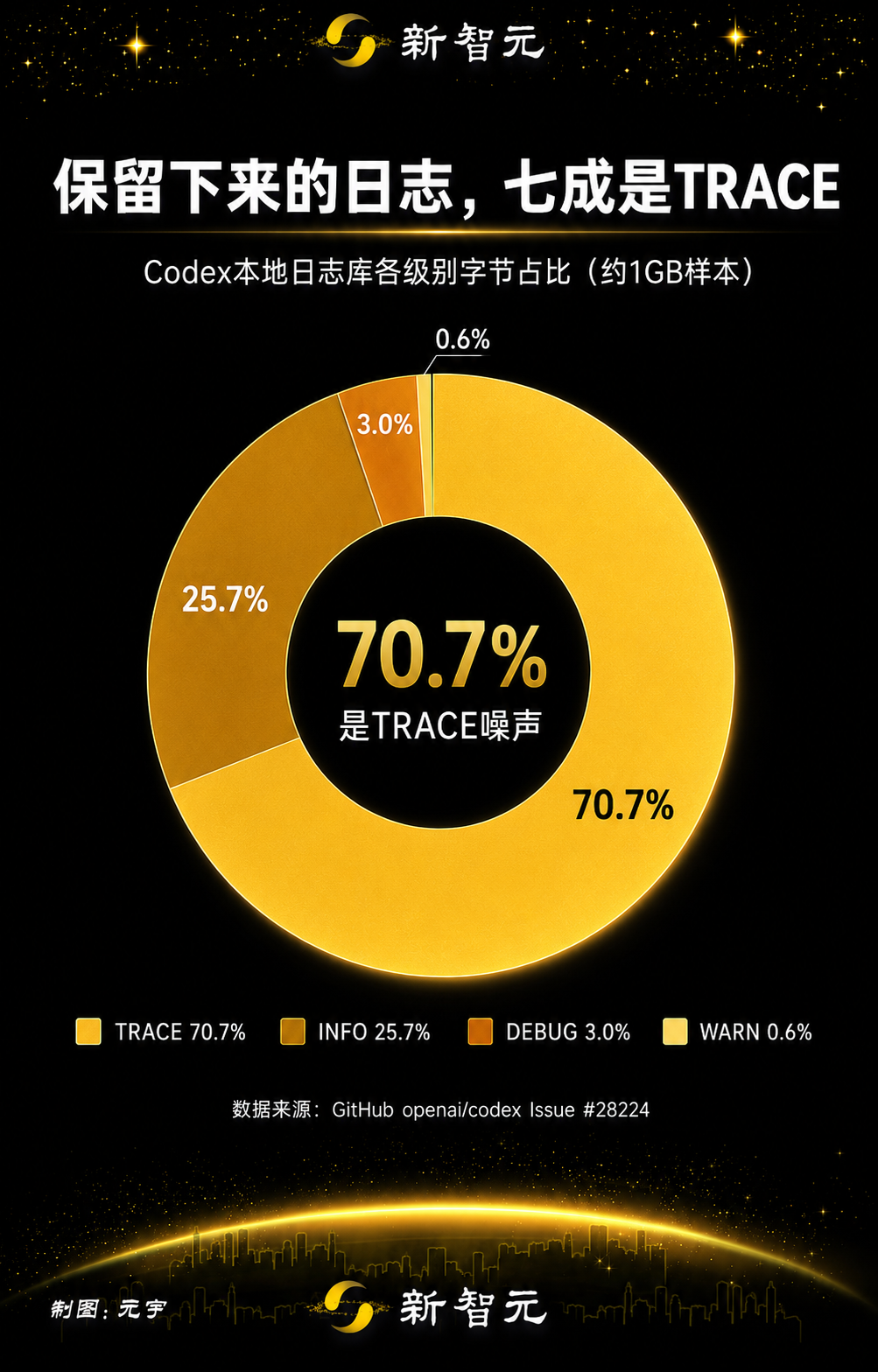
Le rapport a également noté que deux sources de journaux liées à OpenTelemetry et mises en miroir, codex_otel.log_only et codex_otel.trace_safe, représentaient une autre part importante des octets de journaux conservés. Dans cet échantillon, l’auteur du rapport estimait que filtrer ces catégories bruyantes pourrait supprimer la majeure partie du volume de journaux conservés sans désactiver complètement les journaux de retour d’information.
C’est pourquoi ce bogue a semblé si frustrant pour les développeurs. Ce n’était pas simplement « vous avez oublié de configurer la journalisation ». Cela ressemblait davantage à « vous avez essayé de réduire la journalisation, mais ce chemin persistait malgré tout à conserver des journaux verbeux ».
几分钟搭建展示站并增长获客
输入一句想法,We0 AI 即可生成展示站、页面与 CMS。发布上线后并帮你获取客户和流量。
Ce n’était pas le premier problème connexe
Le rapport ne présentait pas cela comme un accident isolé. Il énumérait un ensemble de problèmes Codex liés aux journaux SQLite, à la croissance du WAL, à une forte activité disque et à une journalisation locale illimitée ou excessive.
Voici quelques exemples mentionnés dans le rapport :
Problème | Thème signalé |
| Écritures SQLite WAL excessives pendant le streaming, car les journaux TRACE ignoraient |
| Croissance de |
| Fichiers WAL restant alloués ou augmentant de façon inattendue |
| Croissance du journal de feedback SQLite sans rétention ni rotation suffisantes |
| Amplification des écritures sur une minuscule base de données SQLite |
| E/S intensives provenant de processus Codex inactifs |
| Temps d’activité du disque à 100 % sous Windows / WSL2 |
Les outils de codage IA sont de plus en plus considérés comme des partenaires de développement toujours actifs. Ils lisent des fichiers, surveillent des dépôts, maintiennent des sessions ouvertes, collectent de la télémétrie et préservent le contexte. Cela rend les budgets locaux de disque, de mémoire et de CPU tout aussi importants que les budgets de jetons et la qualité du modèle.
Les correctifs ont été fusionnés, mais le débat n’est pas terminé
Le problème GitHub a ensuite ajouté une mise à jour indiquant que trois pull requests avaient été fusionnées et que les propres retours Codex du rapporteur suggéraient une réduction estimée de 85 % des journaux.
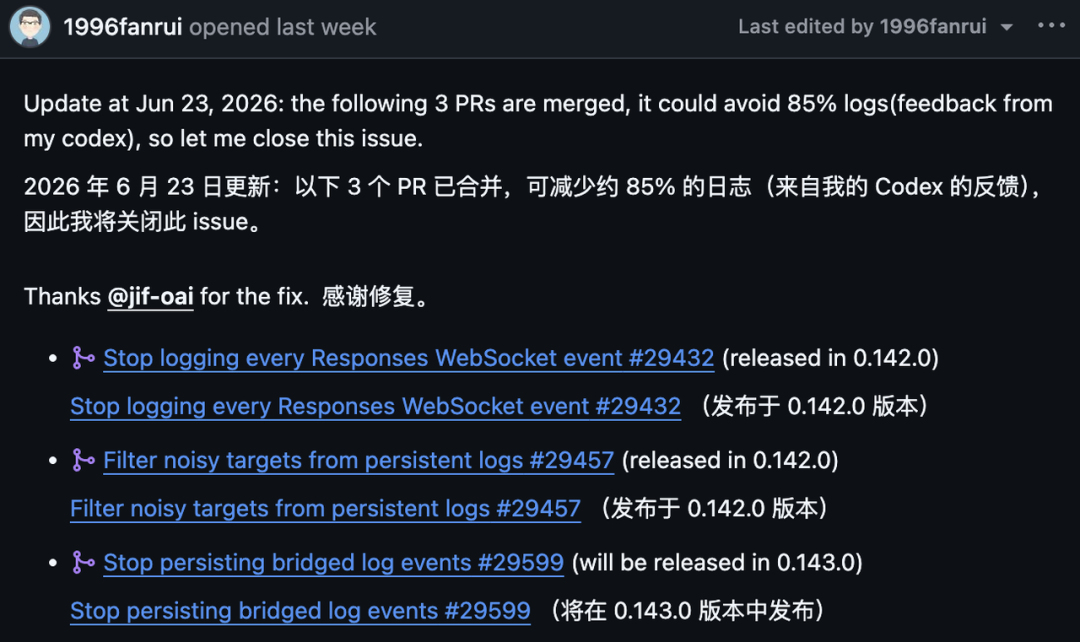
Le problème énumérait les trois correctifs ainsi :
Pull Request | Objectif | Note de version dans l’issue |
| Arrêter de consigner chaque événement WebSocket Responses | Publié dans |
| Filtrer les cibles bruyantes des journaux persistants | Publié dans |
| Arrêter de conserver les événements de journal relayés | Prévu pour |
Une réduction de 85 % est significative, mais ce n’est pas la même chose que de prouver que la journalisation locale dispose désormais d’un budget d’écriture strict à long terme. C’est cette distinction qui explique pourquoi la discussion s’est poursuivie. Les développeurs ne demandaient pas seulement si ce bug précis avait été atténué ; ils demandaient si les agents de codage IA devraient avoir des limites plus claires pour la télémétrie locale persistante.
Le ticket GitHub incluait également une solution de contournement simple partagée par un commentateur. Elle bloque les insertions dans la table logs en créant un déclencheur SQLite :
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"Utilisez ce type de solution de contournement avec prudence. Elles peuvent réduire les écritures de journaux locaux, mais elles peuvent aussi supprimer des données de diagnostic dont les équipes de support ou les développeurs pourraient avoir besoin plus tard. En général, mettre à jour vers une version corrigée et vérifier le comportement actuel des journaux est plus sûr que de modifier silencieusement une base de données d’application sans comprendre le compromis.
La bataille des outils de codage ne fait pas que brûler des SSD
La discussion a rapidement dépassé le seul cas de Codex. Sur Hacker News, les développeurs ont également évoqué des critiques plus larges concernant les outils de codage IA : forte utilisation du GPU, consommation importante de mémoire, activité en arrière-plan et gros journaux de débogage locaux.

Cette réaction est compréhensible. Les assistants de codage IA modernes ne sont plus de simples utilitaires en ligne de commande. Beaucoup d’entre eux se comportent davantage comme des agents locaux : ils surveillent les projets, communiquent avec des modèles distants, gèrent le contexte, exécutent des commandes et conservent un état d’une tâche à l’autre. Cette puissance est utile, mais elle crée aussi une nouvelle catégorie de responsabilités d’ingénierie.
Un outil peut sembler « correct » dans l’interface utilisateur tout en consommant discrètement des ressources en arrière-plan. Les processeurs rapides, la grande quantité de mémoire et les disques NVMe modernes peuvent masquer les problèmes pendant longtemps. L’application peut ne pas se figer. Le disque peut ne pas se remplir. Le terminal peut continuer à répondre. Mais les indicateurs de santé du matériel peuvent raconter une autre histoire.
C’est pourquoi cet incident est devenu une étude de cas utile pour les outils de développement IA. Les capacités du modèle comptent, mais la qualité opérationnelle locale compte aussi. Un agent de codage qui réside sur la machine d’un développeur a besoin de paramètres par défaut raisonnables, de limites de conservation, d’une rotation des journaux et d’un moyen pour les utilisateurs de comprendre ce qu’il fait.
FAQ
Quel était le bug de journalisation SQLite de Codex ?
Il s’agissait d’un problème signalé de journalisation de Codex, dans lequel les journaux locaux de feedback SQLite pouvaient générer de très grandes quantités d’écritures disque. Le rapport GitHub estimait environ 640 To d’écritures par an selon le schéma d’utilisation mesuré par l’auteur du signalement.
Pourquoi un petit fichier logs_2.sqlite pouvait-il tout de même user un SSD ?
L’endurance d’un SSD dépend du volume total de données écrites au fil du temps, et pas seulement de la taille actuelle du fichier. Une base de données peut insérer, supprimer, écrire dans le WAL, effectuer des checkpoints et mettre à jour des index de façon répétée tout en paraissant petite sur le disque.
Que signifie SQLite WAL dans ce contexte ?
WAL signifie Write-Ahead Logging. SQLite écrit d’abord les modifications dans un fichier -wal distinct, puis les réintègre plus tard dans la base de données principale via des checkpoints, ce qui est un comportement normal mais peut générer beaucoup d’activité lorsque les insertions et suppressions se produisent très fréquemment.
Quel rôle la journalisation TRACE a-t-elle joué ?
TRACE est le niveau de journalisation le plus détaillé. Dans l’échantillon signalé, le contenu de niveau TRACE représentait environ 70,7 % des octets de journaux conservés, et le problème soulevait que des journaux détaillés de dépendances et de protocoles étaient conservés par défaut.
OpenAI a-t-il corrigé le problème de journalisation de Codex ?
La mise à jour du ticket GitHub indiquait que trois PR avaient été fusionnées, le rapporteur estimant qu’elles pourraient éviter environ 85 % des journaux d’après les retours issus de son utilisation de Codex. Deux correctifs étaient indiqués comme publiés dans 0.142.0, tandis que le troisième était indiqué comme prévu pour 0.143.0.
Les utilisateurs doivent-ils supprimer ou bloquer manuellement les journaux de Codex ?
Les modifications manuelles doivent être traitées avec prudence, car elles peuvent supprimer des informations de diagnostic et avoir des effets secondaires. Une première étape plus sûre consiste à mettre Codex à jour, à examiner les fichiers journaux et à surveiller les compteurs d’écriture du SSD si cela vous préoccupe.
Est-ce uniquement un problème lié à Codex ?
Ce rapport spécifique portait sur Codex. Toutefois, la préoccupation plus large s’applique aux agents d’IA locaux en général : les outils toujours actifs ont besoin de budgets de ressources clairs pour le disque, le CPU, la mémoire, la télémétrie et les journaux conservés.
Outils associés
Dépôt GitHub d’OpenAI Codex : le dépôt public de Codex CLI et du code source associé.
SQLite : le moteur de base de données embarqué utilisé par de nombreuses applications et outils locaux.
Documentation de SQLite sur la journalisation en écriture anticipée : documentation officielle expliquant le fonctionnement du WAL et l’importance des points de contrôle.
tracing Rust : le framework Rust de journalisation structurée et de diagnostic évoqué dans le problème Codex.
smartmontools : un ensemble d’outils permettant de vérifier les données de santé SMART du stockage, y compris les compteurs d’écriture des SSD sur les disques compatibles.
Hacker News : la plateforme de discussion où le rapport sur la journalisation de Codex a suscité une attention plus large de la part des développeurs.
Liens connexes
Problème n° 28224 concernant les journaux de commentaires SQLite de Codex : le principal problème GitHub documentant l’estimation rapportée de 640 To/an d’écriture et les éléments de preuve.
Arrêter de journaliser chaque événement WebSocket de Responses #29432 : l’une des PR fusionnées répertoriées dans le cadre du travail de réduction de la journalisation.
Filtrer les cibles bruyantes des journaux persistants #29457 : la PR s’est concentrée sur le filtrage des cibles de journalisation persistante bruyantes.
Arrêter de persister les événements de journalisation relayés #29599 : la PR de suivi visait à empêcher la persistance des événements de journalisation des dépendances relayés.
Discussion sur Hacker News : discussion de la communauté autour de la journalisation de Codex, des écritures sur SSD et de la qualité des outils de codage par IA.
README de l’interface CLI OpenAI Codex : README du dépôt officiel pour installer et exécuter l’interface CLI Codex.
Documentation SQLite WAL : explication officielle des fichiers WAL, des points de contrôle et des considérations de performance.


