
Un problema reciente de registro en Codex convirtió una tranquila base de datos local en un escritor de SSD sorprendentemente intenso. Según el informe original de GitHub, los registros de retroalimentación de SQLite de Codex podían escribir aproximadamente 640 TB al año con el patrón de uso reportado. Para un SSD de consumo con una clasificación de alrededor de 600 TBW, esa cifra no es solo un pequeño desorden; está cerca de la resistencia de escritura garantizada de la unidad.
Lo extraño es que la base de datos de registros no parecía enorme. El archivo podía rondar un gigabyte, mientras que las escrituras históricas reales seguían acumulándose en segundo plano. Por eso este error atrajo tanta atención: no llenaba el disco de una forma evidente, pero aun así podía consumir ciclos de escritura.

Nota sobre la fuente: Este artículo se basa en la republicación de BAAI Hub del informe de Xinzhiyuan y se contrastó con el issue público de GitHub y la discusión de Hacker News. No se incluyeron logotipos de marcas, códigos QR, invitaciones a seguir, ni imágenes decorativas no relacionadas de la página original.
Cómo pueden producirse 640 TB de escrituras en un SSD
Al principio, la cifra suena exagerada, así que conviene empezar por la medición.
En el issue de GitHub, la persona que informó del problema dijo que, tras unos 21 días de actividad, el SSD principal había escrito alrededor de 37 TB. Extrapolado a un año completo, eso equivale aproximadamente a 640 TB. Se sospechaba que la fuente principal era la base de datos local de registros de retroalimentación de SQLite de Codex.
Codex escribía en archivos ubicados en el directorio de configuración local:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shmEl comportamiento no era simplemente que “el archivo de registro sigue creciendo para siempre”. En cambio, se parecía más a un bucle de insertar y podar: Codex insertaba nuevas filas y luego eliminaba filas antiguas para mantener estable el número de filas conservadas. El tamaño visible del archivo se mantenía relativamente tranquilo, pero la unidad aún tenía que procesar las escrituras repetidas.
Una muestra de 15 segundos del informe mostró claramente el problema:
Métrica | Antes | Después |
Filas conservadas | 681,774 | 681,774 |
ID máximo de fila | 5,003,347,015 | 5,003,383,226 |
Eso significa que se insertaron alrededor de 36.211 filas en 15 segundos, aunque el recuento de filas retenidas no aumentó en absoluto. La base de datos parecía estable desde fuera, pero la rotación de escrituras continuaba por debajo.
Las entradas de registro frecuentes tampoco eran todas eventos de aplicación de alto valor. Los ejemplos incluían ruido repetido a nivel del sistema de archivos y de dependencias, como eventos de inotify:
128,764x registro TRACE: evento inotify: ... nombre: Some("ld.so.cache")
37,982x registro TRACE: evento inotify: ... nombre: Some("locale.alias")
23,843x registro TRACE: evento inotify: ... nombre: Some("passwd")El resultado fue un sistema de registro local que podía seguir reescribiendo el almacenamiento mientras ofrecía a los usuarios muy pocas señales visibles de que estuviera ocurriendo algo inusual.
Un archivo de 1 GB aún puede producir cientos de terabytes de escrituras
La parte más contraintuitiva de este incidente es sencilla: el desgaste de un SSD depende del total de escrituras, no del tamaño actual del archivo.
Una base de datos local puede mantenerse alrededor de 1 GB mientras la aplicación escribe, depura, indexa, crea puntos de control y reescribe partes de ella repetidamente. Desde la perspectiva de la salud del almacenamiento, lo que importa no es solo lo grande que parece el archivo hoy. Lo que importa es cuántos datos se han escrito a lo largo del tiempo.
El informe incluía una instantánea que hacía que la diferencia fuera más fácil de ver:
Métrica | Valor |
Tamaño actual del archivo | 1.2 GiB |
Filas conservadas actualmente | 506,149 |
Total de ID de fila asignados | 5,543,677,486 |
La base de datos actual conservaba solo alrededor de medio millón de filas, mientras que el ID de fila autoincremental ya había superado los 5.5 mil millones. Ese es el núcleo de la historia de la amplificación de escritura: las filas antiguas pueden desaparecer de la vista actual de la base de datos, pero las escrituras en disco que las crearon ya se han producido.
El WAL de SQLite, o registro de escritura anticipada, también es importante aquí. Con el modo WAL, los cambios se añaden a un archivo -wal separado antes de registrarse mediante checkpoint de vuelta en la base de datos principal. WAL es un mecanismo normal y útil de SQLite, pero cuando una aplicación realiza inserciones y eliminaciones con mucha frecuencia, puede multiplicar la cantidad de actividad de disco que ocurre entre bastidores.
En lenguaje sencillo: el cuaderno sigue pareciendo delgado, pero las mismas páginas se han escrito, borrado y reescrito muchas veces.
Causa raíz: una configuración de RUST_LOG que no se comportó como esperaban los usuarios
El informe señaló un detalle de configuración especialmente importante en la ruta de registro de Codex:
Targets::new().with_default(Level::TRACE)En el ecosistema tracing de Rust, el filtrado de registros suele controlarse mediante objetivos y niveles. Los usuarios pueden esperar razonablemente que la variable de entorno RUST_LOG ayude a reducir la verbosidad de los registros a algo como info, warn o inferior.
Pero en esta ruta, el destino de registro de comentarios de SQLite usaba un valor predeterminado de TRACE. TRACE es el nivel más detallado, y puede capturar detalles de dependencias de bajo nivel, actividad de protocolo sin procesar y otro ruido de depuración. El informe del problema argumentaba que este valor predeterminado significaba que la base de datos local persistente de registros seguía almacenando mucho más de lo que debería.
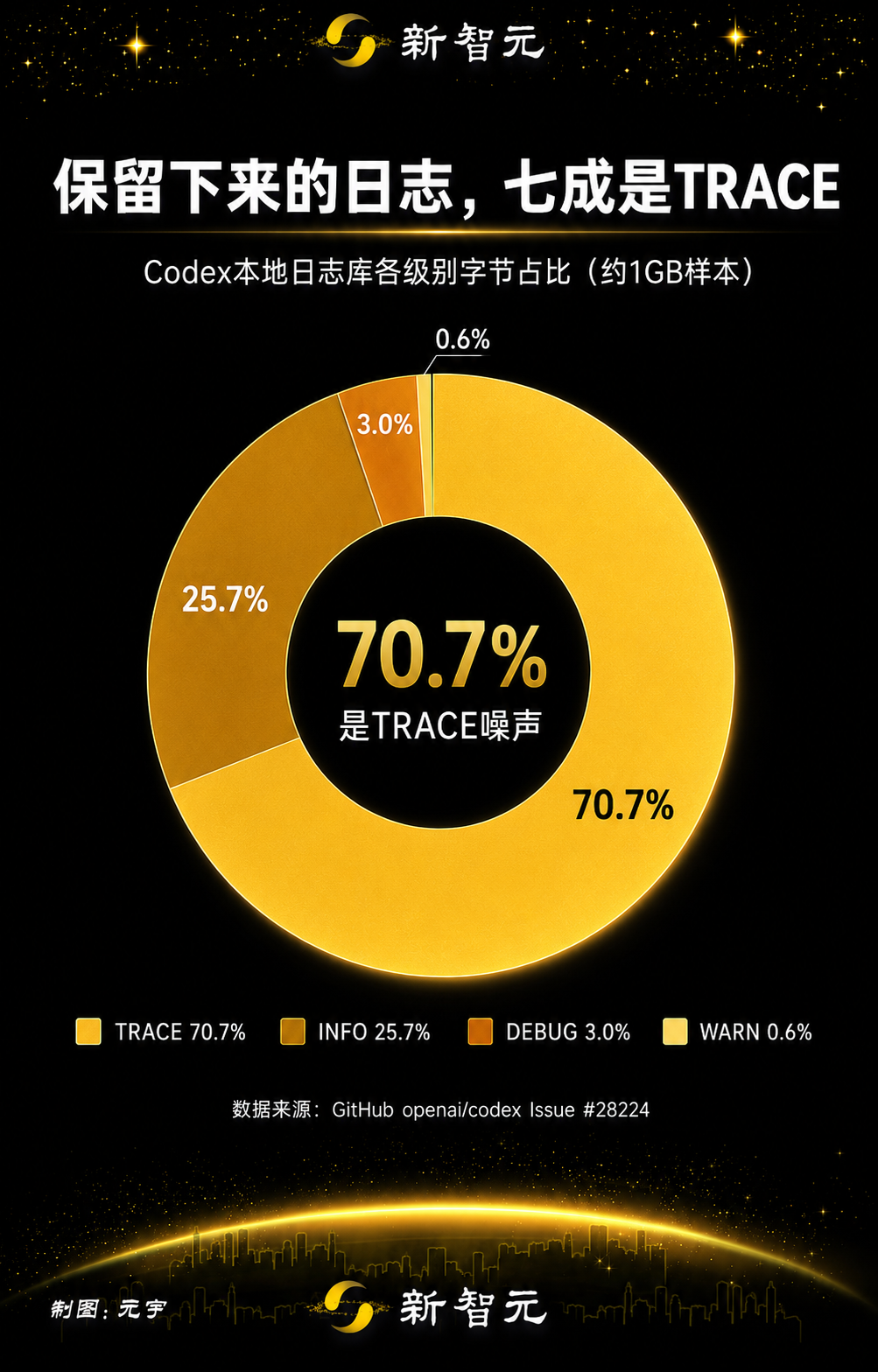
La distribución de registros conservados mostró lo dominante que era el contenido de nivel TRACE:
Nivel | MiB estimados | Proporción de bytes |
TRACE | 732.5 | 70.7% |
INFO | 266.5 | 25.7% |
DEBUG | 30.6 | 3.0% |
WARN | 5.9 | 0.6% |
El informe también señaló que dos fuentes de registro duplicadas relacionadas con OpenTelemetry, codex_otel.log_only y codex_otel.trace_safe, representaban otra gran parte de los bytes de registro conservados. En esa muestra, el informante estimó que filtrar estas categorías ruidosas podría eliminar la mayor parte del volumen de registros conservados sin desactivar por completo los registros de retroalimentación.
Por eso el error resultaba tan frustrante para los desarrolladores. No era simplemente “olvidaste configurar el registro”. Se parecía más a “intentaste reducir el registro, pero esta ruta aun así seguía conservando registros detallados”.
几分钟搭建展示站并增长获客
输入一句想法,We0 AI 即可生成展示站、页面与 CMS。发布上线后并帮你获取客户和流量。
Este no fue el primer problema relacionado
El informe no trató esto como un accidente aislado. Enumeró un grupo de problemas relacionados de Codex en torno a registros de SQLite, crecimiento de WAL, actividad intensa del disco y registro local ilimitado o excesivo.
Algunos ejemplos mencionados en el informe incluían:
Incidencia | Tema informado |
| Escrituras WAL excesivas de SQLite durante la transmisión porque los registros TRACE ignoraban |
| Crecimiento de |
| Archivos WAL que permanecen asignados o crecen inesperadamente |
| Crecimiento del registro de comentarios en SQLite sin suficiente retención o rotación |
| Amplificación de escritura en una base de datos SQLite diminuta |
| E/S intensa de procesos Codex inactivos |
| 100 % de tiempo de actividad del disco en Windows / WSL2 |
Las herramientas de programación con IA se tratan cada vez más como socios de desarrollo siempre activos. Leen archivos, supervisan repositorios, mantienen sesiones abiertas, recopilan telemetría y conservan el contexto. Eso hace que los presupuestos locales de disco, memoria y CPU sean tan importantes como los presupuestos de tokens y la calidad del modelo.
Las correcciones se fusionaron, pero el debate no terminó
El issue de GitHub añadió más tarde una actualización en la que decía que se habían fusionado tres pull requests y que los propios comentarios de Codex del informante sugerían una reducción estimada del 85 % en los registros.
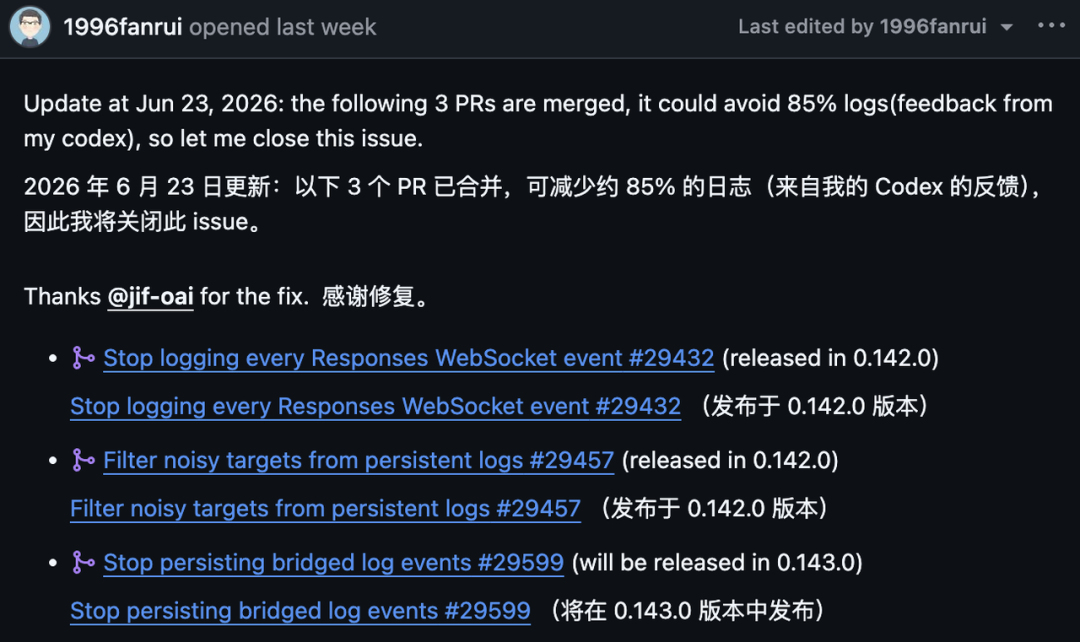
El issue enumeraba las tres correcciones así:
Solicitud de incorporación de cambios | Propósito | Nota de la versión en el issue |
| Dejar de registrar cada evento de WebSocket de Responses | Publicado en |
| Filtrar los destinos ruidosos de los registros persistentes | Publicado en |
| Dejar de persistir los eventos de registro puenteados | Previsto para |
Una reducción del 85 % es significativa, pero no equivale a demostrar que el registro local tenga ahora un presupuesto de escritura estricto a largo plazo. Esa distinción es la razón por la que la discusión continuó. Los desarrolladores no solo preguntaban si este error en particular se había reducido; preguntaban si los agentes de codificación de IA deberían tener límites más claros para la telemetría local persistente.
El issue de GitHub también incluía una solución alternativa sencilla compartida por un comentarista. Bloquea las inserciones en la tabla logs creando un disparador de SQLite:
sqlite3 ~/.codex/logs_2.sqlite "CREATE TRIGGER IF NOT EXISTS
block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE);
END;"Utiliza soluciones alternativas como esta con cuidado. Pueden reducir las escrituras de registros locales, pero también pueden eliminar datos de diagnóstico que los equipos de soporte o los desarrolladores podrían necesitar más adelante. En general, actualizar a una versión corregida y comprobar el comportamiento actual de los registros es más seguro que modificar silenciosamente una base de datos de la aplicación sin entender la contrapartida.
La batalla de las herramientas de codificación está quemando algo más que SSD
La discusión se trasladó rápidamente más allá de Codex. En Hacker News, los desarrolladores también plantearon quejas más amplias sobre las herramientas de codificación con IA: alto uso de la GPU, gran consumo de memoria, actividad en segundo plano y grandes registros locales de depuración.

Esa reacción tiene sentido. Los asistentes modernos de codificación con IA ya no son simples utilidades de línea de comandos. Muchos de ellos se comportan más como agentes locales: observan proyectos, se comunican con modelos remotos, gestionan el contexto, ejecutan comandos y mantienen el estado entre tareas. Esa potencia es útil, pero también crea una nueva categoría de responsabilidad en ingeniería.
Una herramienta puede parecer “correcta” en la interfaz de usuario y aun así consumir recursos silenciosamente en segundo plano. Las CPU rápidas, la gran cantidad de memoria y las unidades NVMe modernas pueden ocultar problemas durante mucho tiempo. La aplicación puede no congelarse. El disco puede no llenarse. La terminal puede seguir respondiendo. Pero los contadores de salud del hardware pueden contar una historia diferente.
Por eso este incidente se convirtió en un caso de estudio útil para las herramientas de desarrollo con IA. La capacidad del modelo importa, pero la calidad operativa local también importa. Un agente de codificación que vive en la máquina de un desarrollador necesita valores predeterminados sensatos, límites de retención, rotación de registros y una forma de que los usuarios entiendan qué está haciendo.
Preguntas frecuentes
¿Cuál fue el error de registro SQLite de Codex?
Fue un problema reportado de registro de Codex en el que los registros locales de retroalimentación en SQLite podían generar cantidades muy grandes de escrituras en disco. El informe de GitHub estimó alrededor de 640 TB de escrituras al año según el patrón de uso medido por la persona que lo reportó.
¿Por qué un archivo logs_2.sqlite pequeño aún podría desgastar un SSD?
La resistencia de un SSD depende del total de datos escritos a lo largo del tiempo, no solo del tamaño actual del archivo. Una base de datos puede insertar, eliminar, escribir en WAL, hacer puntos de control y actualizar índices repetidamente sin dejar de parecer pequeña en el disco.
¿Qué significa SQLite WAL en este contexto?
WAL significa registro de escritura anticipada. SQLite escribe primero los cambios en un archivo -wal separado y más tarde los confirma de vuelta en la base de datos principal, lo cual es un comportamiento normal, pero puede generar mucha actividad cuando las inserciones y eliminaciones ocurren con mucha frecuencia.
¿Qué papel desempeñó el registro TRACE?
TRACE es el nivel de registro más detallado. En la muestra reportada, el contenido de nivel TRACE representaba aproximadamente el 70,7% de los bytes de registro conservados, y el informe sostenía que los registros detallados de dependencias y protocolos se estaban guardando de forma predeterminada.
¿OpenAI solucionó el problema de registro de Codex?
La actualización del issue de GitHub indicó que se fusionaron tres PR, y el informante estimó que podrían evitar alrededor del 85% de los registros basándose en los comentarios derivados de su uso de Codex. Dos correcciones figuraban como publicadas en 0.142.0, mientras que la tercera figuraba como planificada para 0.143.0.
¿Deben los usuarios eliminar o bloquear manualmente los registros de Codex?
Los cambios manuales deben tratarse con cuidado porque pueden eliminar información de diagnóstico y tener efectos secundarios. Un primer paso más seguro es actualizar Codex, inspeccionar los archivos de registro y supervisar los contadores de escritura del SSD si te preocupa.
¿Es este solo un problema de Codex?
Este informe específico se centró en Codex. Sin embargo, la preocupación más amplia se aplica a los agentes de IA locales en general: las herramientas siempre activas necesitan presupuestos de recursos claros para disco, CPU, memoria, telemetría y registros conservados.
Herramientas relacionadas
Repositorio de GitHub de OpenAI Codex: El repositorio público de Codex CLI y el código fuente relacionado.
SQLite: El motor de base de datos integrado utilizado por muchas aplicaciones y herramientas locales.
Documentación de SQLite sobre el registro de escritura anticipada: Documentación oficial que explica cómo funciona WAL y por qué los puntos de control son importantes.
tracing de Rust: El marco de registro estructurado y diagnóstico de Rust analizado en la incidencia de Codex.
smartmontools: Un conjunto de herramientas para comprobar los datos de salud de almacenamiento SMART, incluidos los contadores de escritura de SSD en unidades compatibles.
Hacker News: La plataforma de debate donde el informe sobre el registro de Codex atrajo una mayor atención de los desarrolladores.
Enlaces relacionados
Problema #28224 de registros de comentarios de Codex SQLite: El principal problema de GitHub que documenta la estimación reportada de 640 TB/año de escritura y la evidencia.
Dejar de registrar todos los eventos de WebSocket de Responses #29432: Una de las PR fusionadas incluidas como parte del trabajo de reducción de registros.
Filtrar objetivos ruidosos de los registros persistentes #29457: La PR se centró en filtrar objetivos ruidosos del registro persistente.
Dejar de persistir eventos de registro puenteados #29599: La PR de seguimiento tenía como objetivo evitar que los eventos de registro de dependencias puenteados se persistieran.
Discusión en Hacker News: Discusión de la comunidad sobre el registro de Codex, las escrituras en SSD y la calidad de las herramientas de codificación con IA.
README de OpenAI Codex CLI: README oficial del repositorio para instalar y ejecutar Codex CLI.
Documentación de WAL de SQLite: Explicación oficial de los archivos WAL, los puntos de control y las consideraciones de rendimiento.


