
关键要点
Gemini 3.5 Flash 中最昂贵的错误是静默默认值,而不是语法错误。
对于许多编码代理来说,
low比人们预期的更适合作为默认值。通过 GitHub Copilot 运行的重型代理循环可能会因为 14 倍计费而变得昂贵得多。
在 We0 AI,模型选择只是工作流的一部分。其余部分在于产品如何被解释、展示和发现。
gemini-3.5-flash 看起来很容易调用。
这也正是它容易被低估的原因。即使只是从预览版时代的代码做一次小迁移,也可能在完全不抛出可见错误的情况下,产生更差的输出、不同的成本结构,以及更昂贵的多轮循环。
本指南聚焦于最重要的三个陷阱、避免它们的代码形态,以及一个你可以快速改造的实用 MCP 风格代理循环。
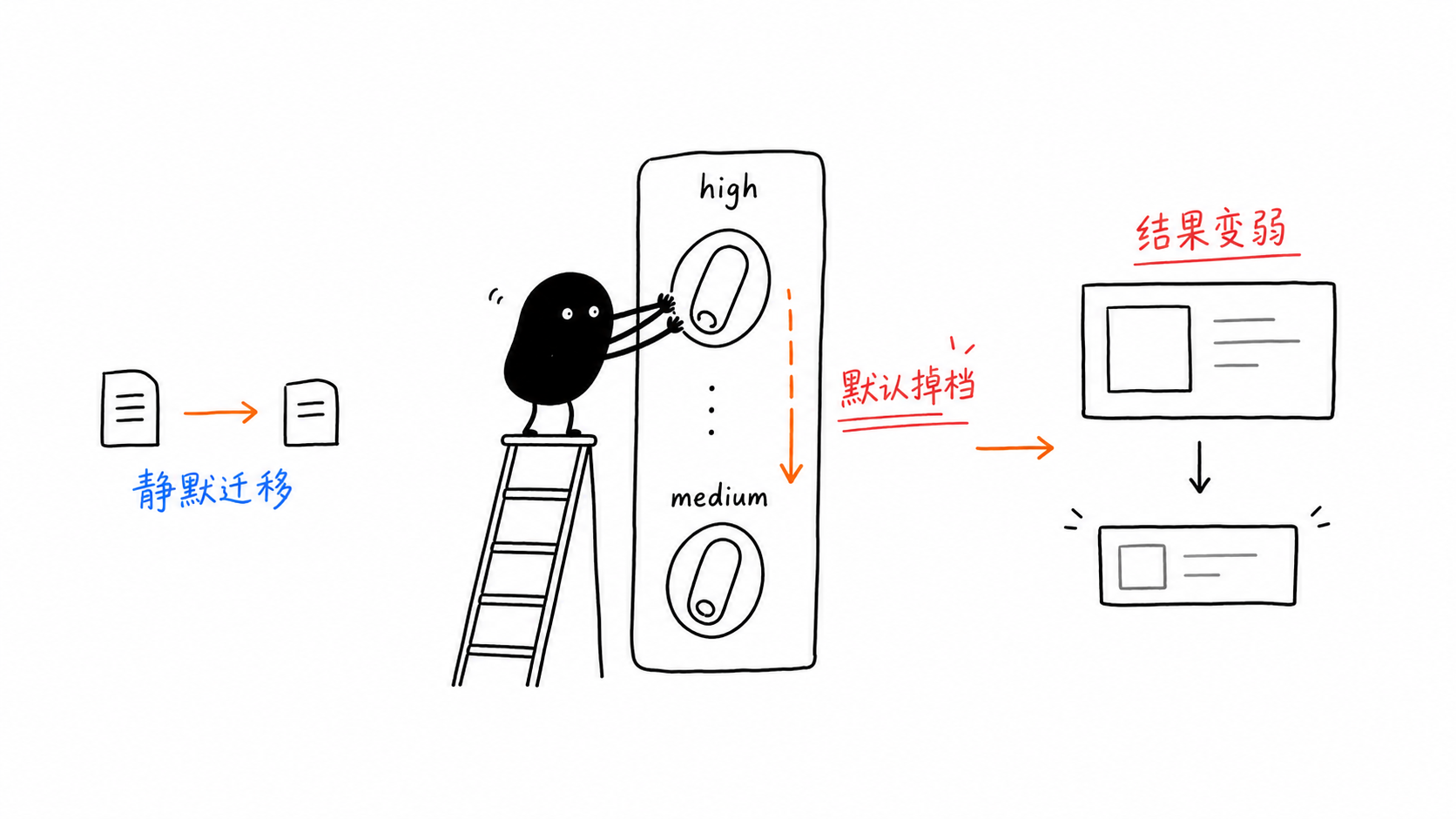
陷阱 1:thinking_level 的默认值从高降到了中
这很危险,因为不会有任何东西崩溃。
你迁移了旧代码,请求依然会返回,但模型的推理水平已经不再是你原先假定的那样。
旧版与新版的思维模型
值
作用
何时使用
minimal
最低限度的推理
自动补全、分类、单次补全
low
针对代码和代理任务重新调优
编码代理、MCP 工具循环、多步骤工作流
medium
新的默认值——平衡型
面向消费者的聊天、通用问答
high
最大推理强度
高难度推理、调试新颖问题、数学、规划
最容易犯的错误
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=prompt,
)
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
)第二段代码可以运行,但默认值已经不再相同。
更安全的迁移方式
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={
"thinking_config": {
"thinking_level": "high" # or "low" for coding agents
}
},
)一个违反直觉的建议
对于许多编码代理工作流,应该从 low 开始,而不是 high。
实际原因很简单:
更快
更便宜
对于以工具为主的编码循环,通常已经足够好,或者表现相当
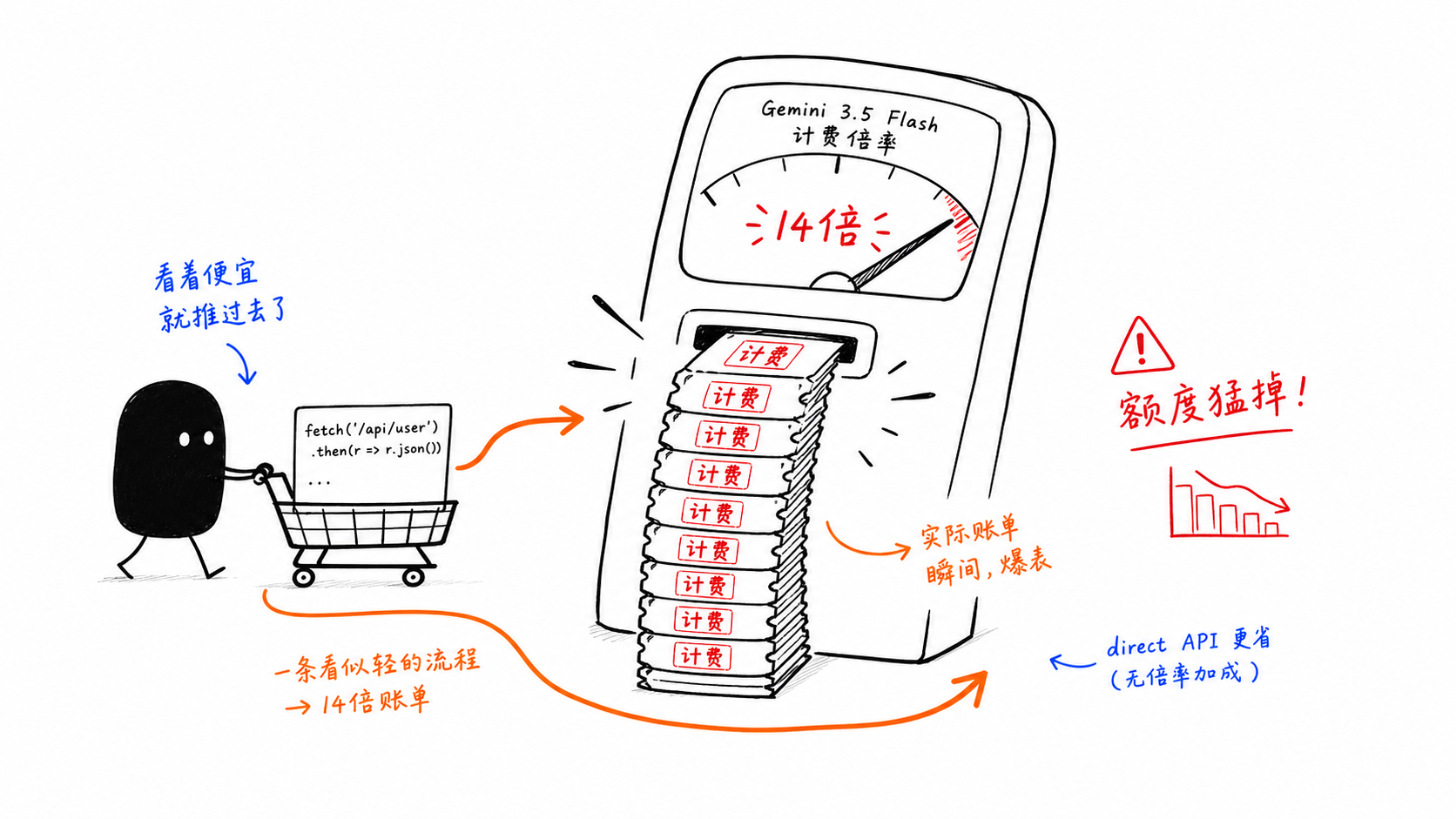
陷阱 2:GitHub Copilot 对 Gemini 3.5 Flash 按 14 倍计费
这是本文中成本最高的陷阱。
问题不在于模型的标价,而在于 GitHub Copilot 内部的高级请求乘数。一旦以代理方式使用 Flash,成本结构就会迅速变化。
这就是为什么许多团队会拆分路径:
轻量级交互式使用保留在 Copilot 内部
重型循环和批处理式工作流走直连 API
几分钟搭建展示站并增长获客
输入一句想法,We0 AI 即可生成展示站、页面与 CMS。发布上线后并帮你获取客户和流量。
用户注册赠送一次完整项目生成
适合先体验一次完整生成流程,快速看到项目初稿。
架构本身就成了成本控制手段。
陷阱 3:思维保留会自动抬高多轮 Token 账单
Gemini 3.5 Flash 会在多轮之间延续内部推理。
这会提升连贯性,但也意味着这些思维内容可能会持续出现在后续的 token 计费中。
对于长代理循环,这可能会显著提高 token 使用量。
实用的缓解方法
在清晰的阶段边界重置聊天
总结并只保留真正重要的内容继续传递
对稳定的指令和工具定义使用提示缓存
持续关注思维 token 与提示 token 的比例变化
一个可运行在 Gemini 3.5 Flash 上的 MCP 代理
原文包含了一个非常有用的端到端模式:一个文件读取工具、一个 URL 抓取工具、标准的函数声明结构,以及一个将工具响应回传给模型的循环。
工具定义
import os
import httpx
from pathlib import Path
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
read_file = types.FunctionDeclaration(
name="read_file",
description="Read a local file and return its contents as text.",
parameters={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Absolute path to the file"
}
},
"required": ["path"],
},
)
fetch_url = types.FunctionDeclaration(
name="fetch_url",
description="Fetch a URL and return the response body as text.",
parameters={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Fully-qualified URL"
}
},
"required": ["url"],
},
)Agent 循环模式
tools = types.Tool(function_declarations=[read_file, fetch_url])
def execute_tool(call):
if call.name == "read_file":
return Path(call.args["path"]).read_text(encoding="utf-8")
if call.name == "fetch_url":
return httpx.get(call.args["url"], timeout=15).text[:50000]
raise ValueError(f"Unknown tool: {call.name}")
def run_agent(task: str, max_turns: int = 8):
history = [types.Content(role="user", parts=[types.Part(text=task)])]
for _ in range(max_turns):
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=history,
config=types.GenerateContentConfig(
tools=[tools],
thinking_config=types.ThinkingConfig(thinking_level="low"),
),
)
if not response.function_calls:
return response.text
history.append(response.candidates[0].content)
tool_results = []
for call in response.function_calls:
result = execute_tool(call)
tool_results.append(
types.Part(
function_response=types.FunctionResponse(
id=call.id,
name=call.name,
response={"result": result},
)
)
)
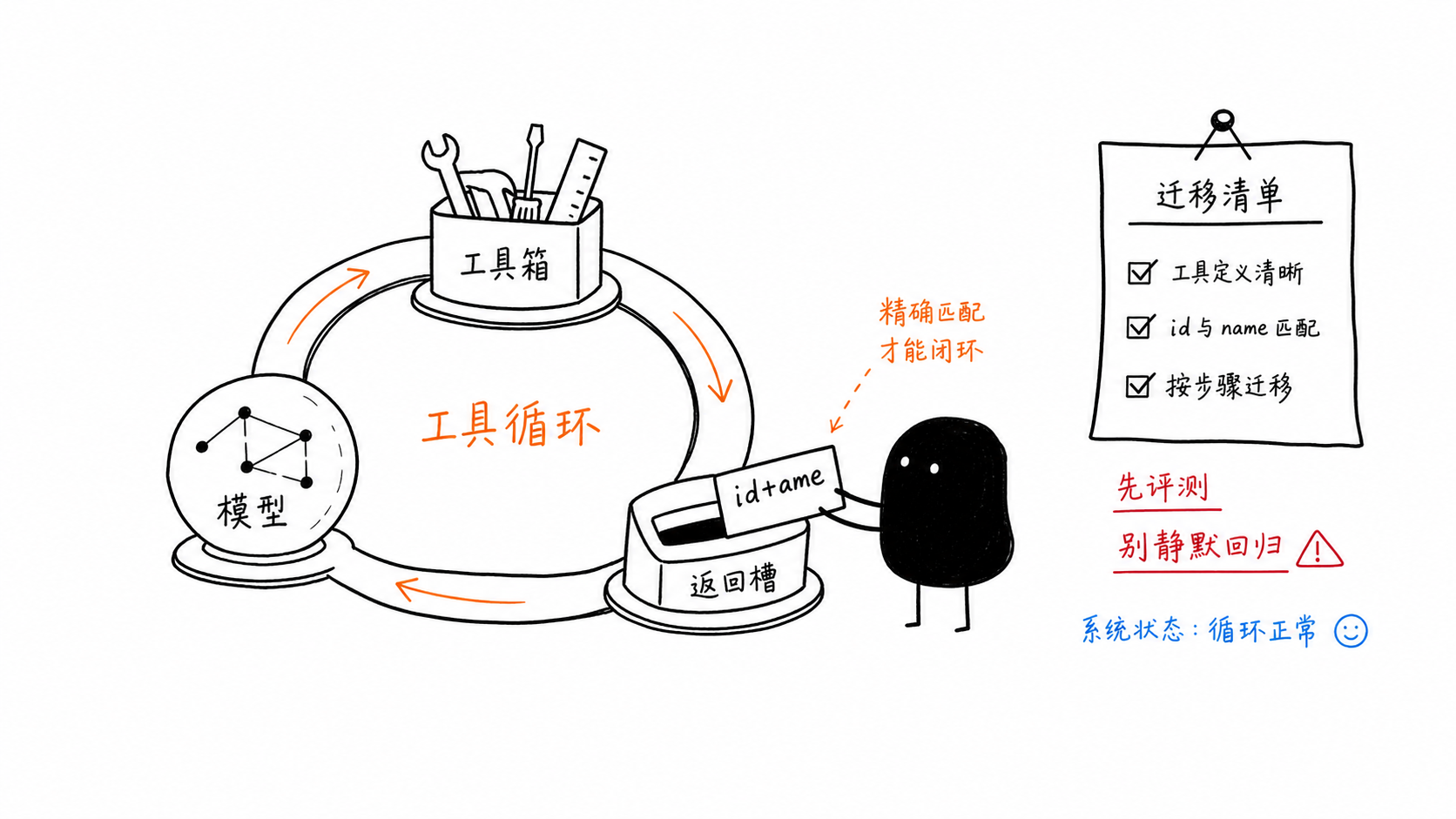
history.append(types.Content(role="tool", parts=tool_results))这个虽小但至关重要的迁移规则是:你的函数响应需要同时匹配原始调用中的 id 和 name。
何时应该改用 Antigravity
手动构建工具循环对于原型来说没问题。但在生产环境中,你很快就会发现自己在重复构建编排、缓存、路由、重试和可观测性。
这就是为什么更重要的问题不仅是“我能把这个模型接进来吗”,而是“我到底要自己承担多少代理基础设施?”
快速迁移清单
如果你要从 gemini-3-flash-preview 迁移到 gemini-3.5-flash,请明确检查以下项目:
仔细替换模型 ID
有意识地设置
thinking_level除非评估结果证明有必要,否则移除过时的采样覆盖设置
在工具响应中匹配 id 和 name
检查
response.usage_metadata.thoughts_token_count对于你仍然依赖但尚不受支持的 API,继续保留预览版
运行迁移前后的评估
将 Copilot 计费与直接 API 成本进行比较
用你的工具试试 Gemini 3.5 Flash
如果你的目标不仅是测试提示词,还要把文件、代码仓库、API、文档和代理工作流连接起来,那么你通常需要的不只是一个原始模型端点。
在 We0 AI,这一原则还要再向前延伸一步:代理工作流只完成了一半工作。另一半是通过文档、FAQ、产品页面、展示内容以及 SEO / GEO 渠道,让产品变得可理解、可搜索、可推荐并可转化。
常见问题
如何通过 Python 调用 Gemini 3.5 Flash?
调用本身很简短。真正重要的是显式设置 thinking_level,这样迁移时才不会悄悄降低输出质量。
thinking_level 有哪些取值?
minimal:适用于非常轻量的任务low:适用于编码和代理式工作流medium:作为面向消费者风格的默认值high:适用于更难的推理和更深入的规划
为什么 Gemini 3.5 Flash 在 GitHub Copilot 中成本更高?
因为计费乘数改变了整体经济性。对于高强度代理使用场景,这对成本的影响可能比基础模型价格本身更大。
什么是思维保留(thought preservation)?
它指的是模型在多轮对话中持续携带内部推理过程。这有助于提升多轮一致性,但也会增加令牌成本随时间上升的可能性。
Gemini 3.5 Flash 适合用于 MCP 吗?
是的,尤其是在谨慎处理工具模式、响应匹配、thinking_level 和令牌预算时。


